 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Demonstration without Demonstrations
Jun 17, 2021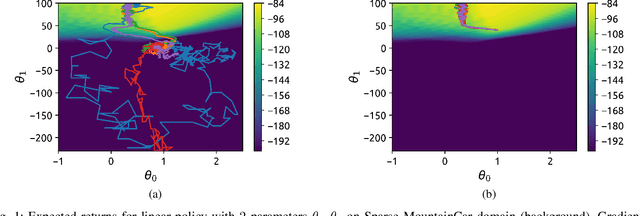
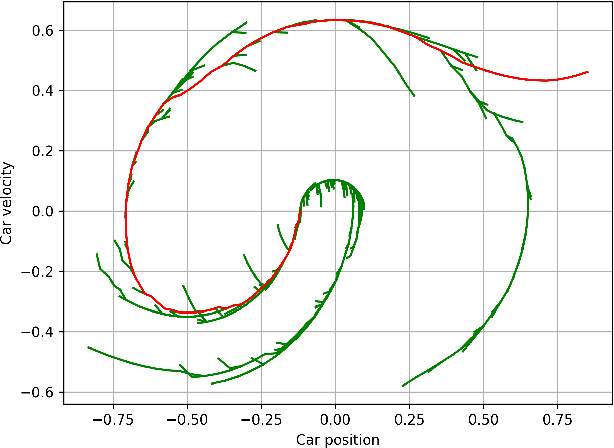
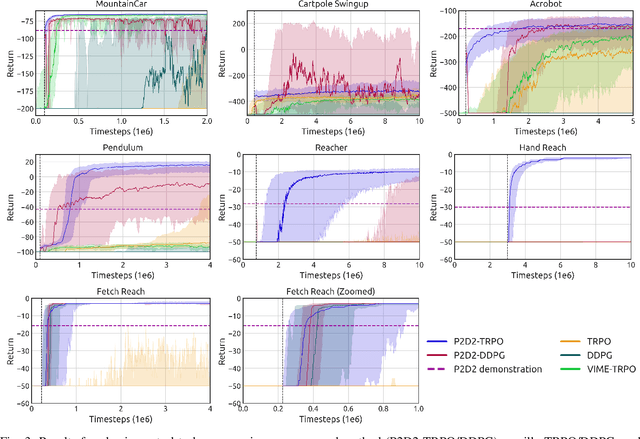
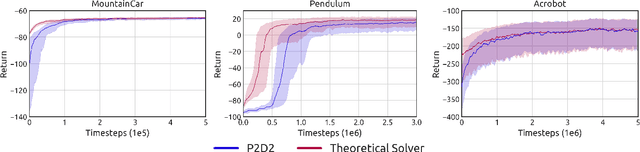
State-of-the-art reinforcement learning (RL) algorithms suffer from high sample complexity, particularly in the sparse reward case. A popular strategy for mitigating this problem is to learn control policies by imitating a set of expert demonstrations. The drawback of such approaches is that an expert needs to produce demonstrations, which may be costly in practice. To address this shortcoming, we propose Probabilistic Planning for Demonstration Discovery (P2D2), a technique for automatically discovering demonstrations without access to an expert. We formulate discovering demonstrations as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree to find demonstration trajectories. These demonstrations are used to initialize a policy, then refined by a generic RL algorithm. We provide theoretical guarantees of P2D2 finding successful trajectories, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration RL techniques in a range of classic control and robotics tasks, requiring only a fraction of exploration samples and achieving better asymptotic performance.
Robust Hierarchical Planning with Policy Delegation
Oct 25, 2020
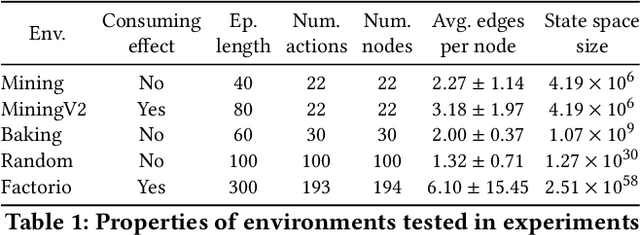
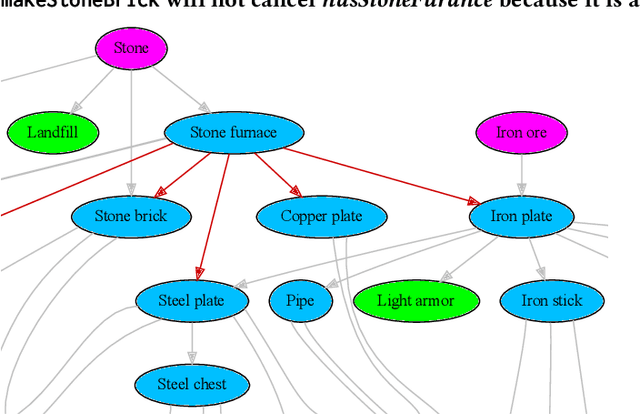
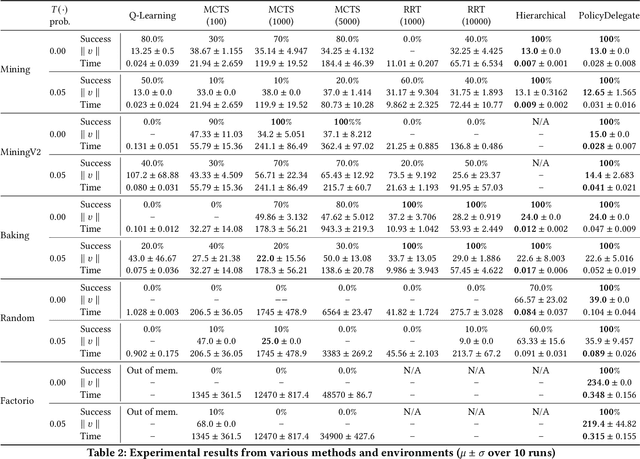
We propose a novel framework and algorithm for hierarchical planning based on the principle of delegation. This framework, the Markov Intent Process, features a collection of skills which are each specialised to perform a single task well. Skills are aware of their intended effects and are able to analyse planning goals to delegate planning to the best-suited skill. This principle dynamically creates a hierarchy of plans, in which each skill plans for sub-goals for which it is specialised. The proposed planning method features on-demand execution---skill policies are only evaluated when needed. Plans are only generated at the highest level, then expanded and optimised when the latest state information is available. The high-level plan retains the initial planning intent and previously computed skills, effectively reducing the computation needed to adapt to environmental changes. We show this planning approach is experimentally very competitive to classic planning and reinforcement learning techniques on a variety of domains, both in terms of solution length and planning time.
Intrinsic Exploration as Multi-Objective RL
Apr 06, 2020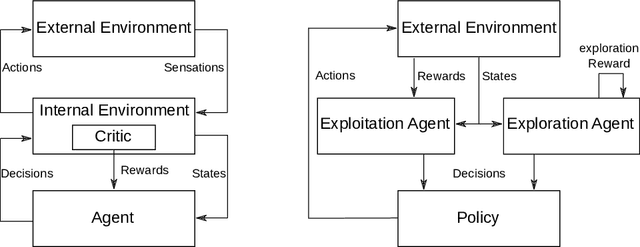

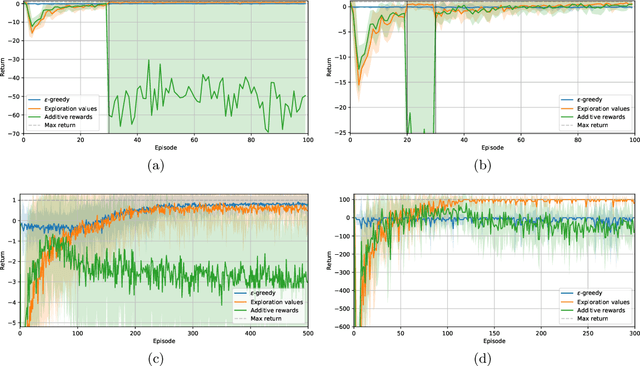
Intrinsic motivation enables reinforcement learning (RL) agents to explore when rewards are very sparse, where traditional exploration heuristics such as Boltzmann or e-greedy would typically fail. However, intrinsic exploration is generally handled in an ad-hoc manner, where exploration is not treated as a core objective of the learning process; this weak formulation leads to sub-optimal exploration performance. To overcome this problem, we propose a framework based on multi-objective RL where both exploration and exploitation are being optimized as separate objectives. This formulation brings the balance between exploration and exploitation at a policy level, resulting in advantages over traditional methods. This also allows for controlling exploration while learning, at no extra cost. Such strategies achieve a degree of control over agent exploration that was previously unattainable with classic or intrinsic rewards. We demonstrate scalability to continuous state-action spaces by presenting a method (EMU-Q) based on our framework, guiding exploration towards regions of higher value-function uncertainty. EMU-Q is experimentally shown to outperform classic exploration techniques and other intrinsic RL methods on a continuous control benchmark and on a robotic manipulator.
Reinforcement Learning with Probabilistically Complete Exploration
Jan 20, 2020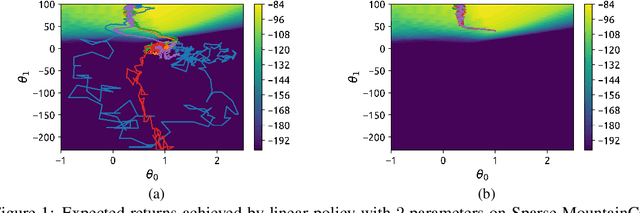

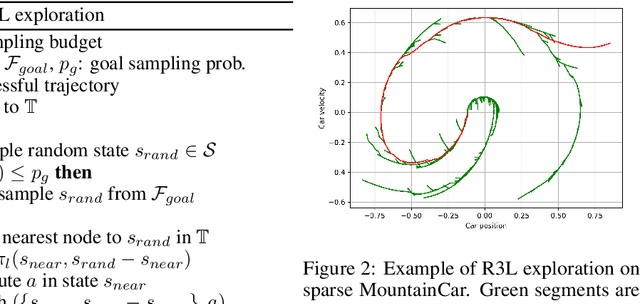
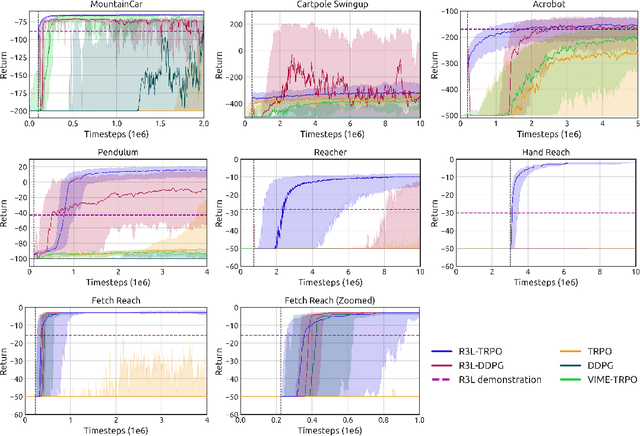
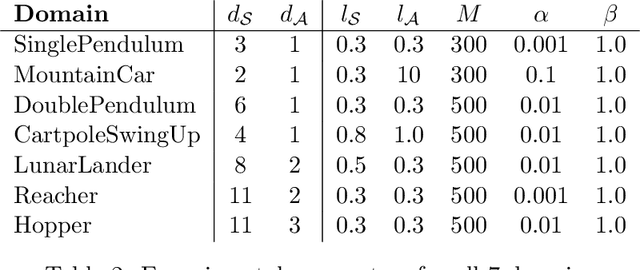
Balancing exploration and exploitation remains a key challenge in reinforcement learning (RL). State-of-the-art RL algorithms suffer from high sample complexity, particularly in the sparse reward case, where they can do no better than to explore in all directions until the first positive rewards are found. To mitigate this, we propose Rapidly Randomly-exploring Reinforcement Learning (R3L). We formulate exploration as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree (RRT) to find initial solutions. These solutions are used as demonstrations to initialize a policy, then refined by a generic RL algorithm, leading to faster and more stable convergence. We provide theoretical guarantees of R3L exploration finding successful solutions, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration techniques, requiring only a fraction of exploration samples and achieving better asymptotic performance.
Local Sampling-based Planning with Sequential Bayesian Updates
Sep 08, 2019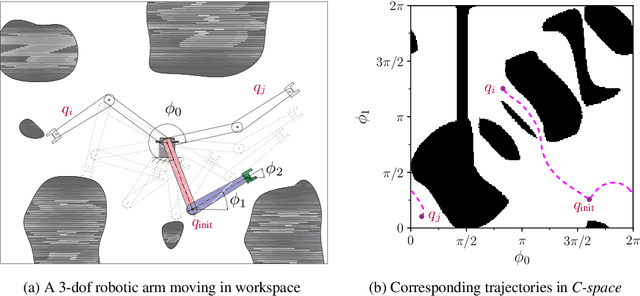
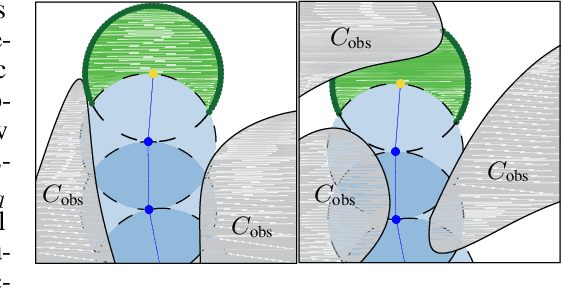
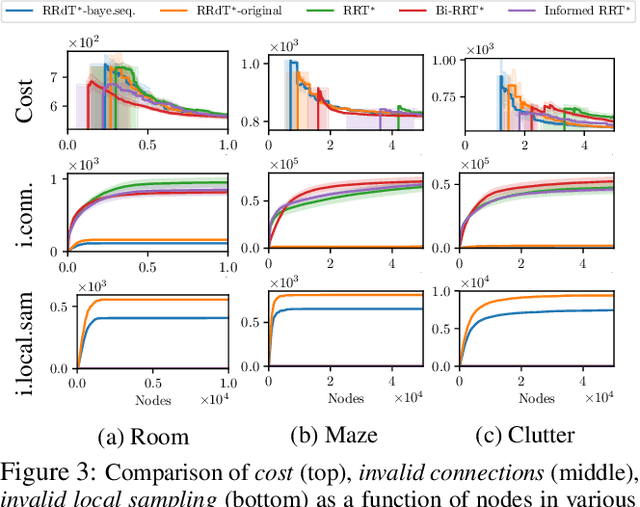
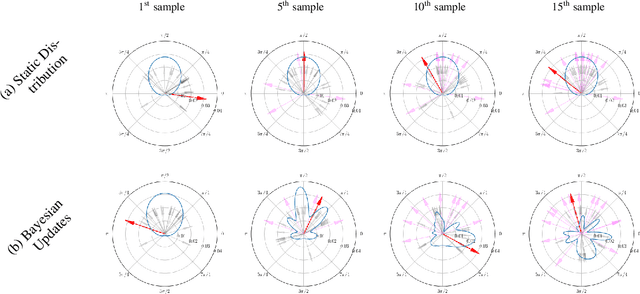
Sampling-based planners are the predominant motion planning paradigm for robots. Majority of sampling-based planners use a global random sampling scheme to guarantee completeness. However, these schemes are sample inefficient as the majority of the samples are wasted in narrow passages. Consequently, information about the local structure is neglected. Local sampling-based motion planners, on the other hand, take sequential decisions of random walks to samples valid trajectories in configuration space. However, current approaches do not adapt their strategies according to the success and failures of past samples. In this work, we introduce a local sampling-based motion planner with a Bayesian update scheme for modelling a sampling proposal distribution. The proposal distribution is sequentially updated based on previous sample outcomes, consequently shaping the proposal distribution according to local obstacles and constraints in the configuration space. Thus, through learning from past observed outcomes, we can maximise the likelihood of sampling in regions that have a higher probability to form trajectories within narrow passages.
Learning to Plan Hierarchically from Curriculum
Jun 18, 2019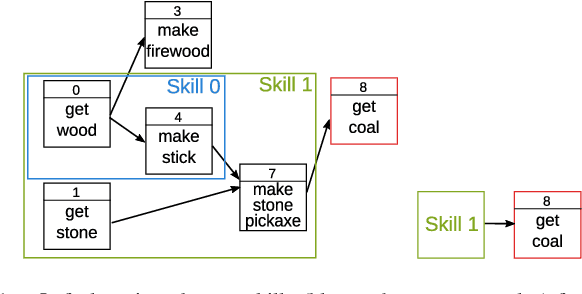
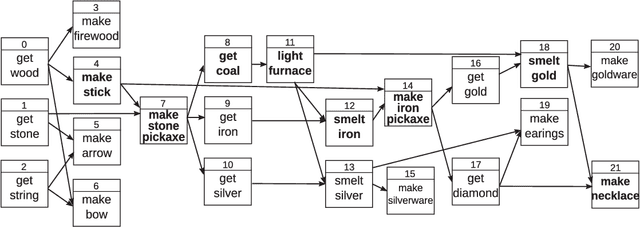
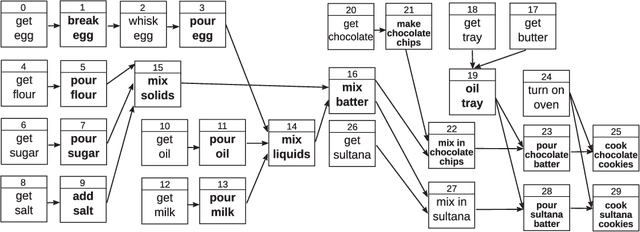
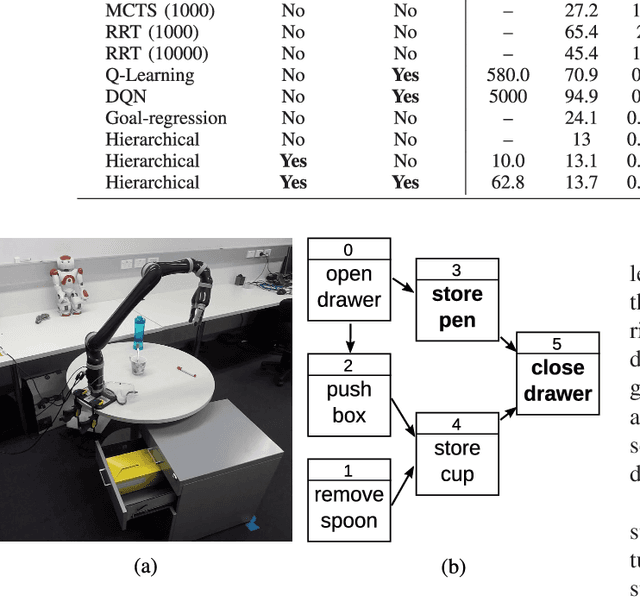
We present a framework for learning to plan hierarchically in domains with unknown dynamics. We enhance planning performance by exploiting problem structure in several ways: (i) We simplify the search over plans by leveraging knowledge of skill objectives, (ii) Shorter plans are generated by enforcing aggressively hierarchical planning, (iii) We learn transition dynamics with sparse local models for better generalisation. Our framework decomposes transition dynamics into skill effects and success conditions, which allows fast planning by reasoning on effects, while learning conditions from interactions with the world. We propose a simple method for learning new abstract skills, using successful trajectories stemming from completing the goals of a curriculum. Learned skills are then refined to leverage other abstract skills and enhance subsequent planning. We show that both conditions and abstract skills can be learned simultaneously while planning, even in stochastic domains. Our method is validated in experiments of increasing complexity, with up to 2^100 states, showing superior planning to classic non-hierarchical planners or reinforcement learning methods. Applicability to real-world problems is demonstrated in a simulation-to-real transfer experiment on a robotic manipulator.
Sequential Bayesian Optimisation as a POMDP for Environment Monitoring with UAVs
Mar 13, 2017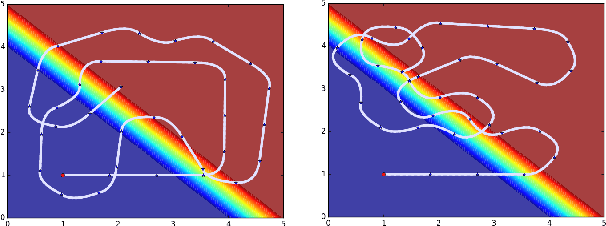
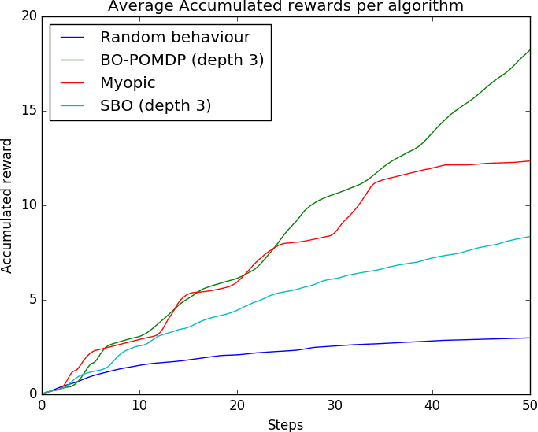
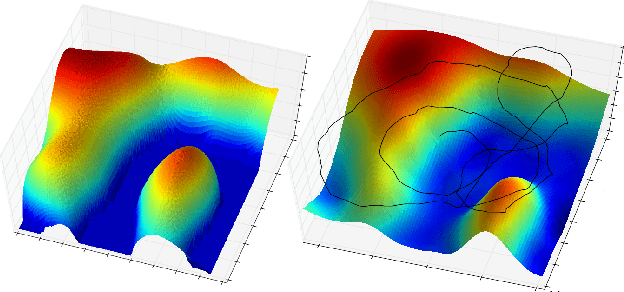
Bayesian Optimisation has gained much popularity lately, as a global optimisation technique for functions that are expensive to evaluate or unknown a priori. While classical BO focuses on where to gather an observation next, it does not take into account practical constraints for a robotic system such as where it is physically possible to gather samples from, nor the sequential nature of the problem while executing a trajectory. In field robotics and other real-life situations, physical and trajectory constraints are inherent problems. This paper addresses these issues by formulating Bayesian Optimisation for continuous trajectories within a Partially Observable Markov Decision Process (POMDP) framework. The resulting POMDP is solved using Monte-Carlo Tree Search (MCTS), which we adapt to using a reward function balancing exploration and exploitation. Experiments on monitoring a spatial phenomenon with a UAV illustrate how our BO-POMDP algorithm outperforms competing techniques.