 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Entropy Estimators for Sequential Experiment Design with Reinforcement Learning
Paper and Code

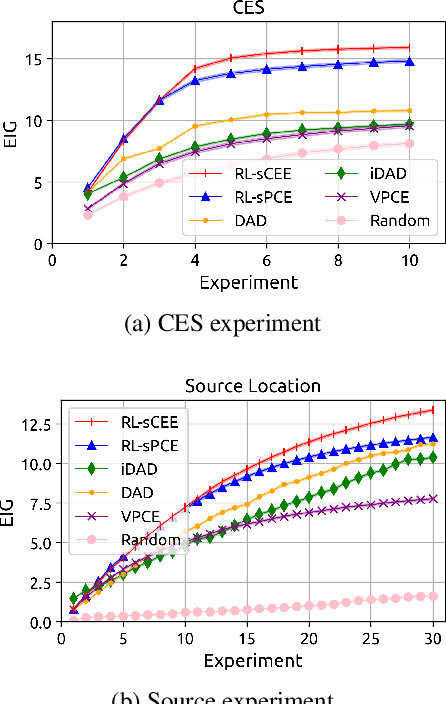
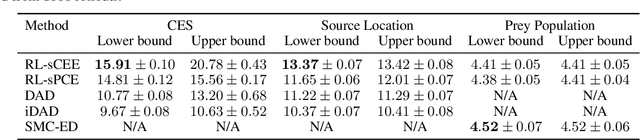
Reinforcement learning can effectively learn amortised design policies for designing sequences of experiments. However, current methods rely on contrastive estimators of expected information gain, which require an exponential number of contrastive samples to achieve an unbiased estimation. We propose an alternative lower bound estimator, based on the cross-entropy of the joint model distribution and a flexible proposal distribution. This proposal distribution approximates the true posterior of the model parameters given the experimental history and the design policy. Our estimator requires no contrastive samples, can achieve more accurate estimates of high information gains, allows learning of superior design policies, and is compatible with implicit probabilistic models. We assess our algorithm's performance in various tasks, including continuous and discrete designs and explicit and implicit likelihoods.