 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Hub: A metric library and practical selection workflow for use-case-driven data quality assessment in medical AI
Jan 30, 2026Machine learning (ML) in medicine has transitioned from research to concrete applications aimed at supporting several medical purposes like therapy selection, monitoring and treatment. Acceptance and effective adoption by clinicians and patients, as well as regulatory approval, require evidence of trustworthiness. A major factor for the development of trustworthy AI is the quantification of data quality for AI model training and testing. We have recently proposed the METRIC-framework for systematically evaluating the suitability (fit-for-purpose) of data for medical ML for a given task. Here, we operationalize this theoretical framework by introducing a collection of data quality metrics - the metric library - for practically measuring data quality dimensions. For each metric, we provide a metric card with the most important information, including definition, applicability, examples, pitfalls and recommendations, to support the understanding and implementation of these metrics. Furthermore, we discuss strategies and provide decision trees for choosing an appropriate set of data quality metrics from the metric library given specific use cases. We demonstrate the impact of our approach exemplarily on the PTB-XL ECG-dataset. This is a first step to enable fit-for-purpose evaluation of training and test data in practice as the base for establishing trustworthy AI in medicine.
Convolutional Dictionary Learning by End-To-End Training of Iterative Neural Networks
Jun 09, 2022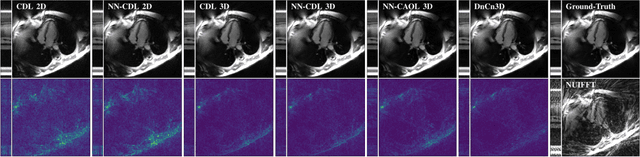
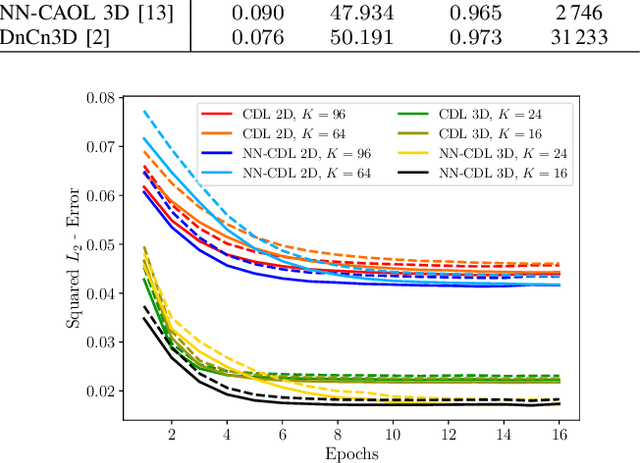

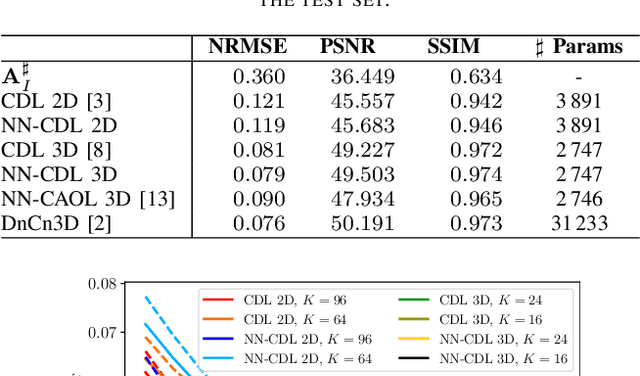
Sparsity-based methods have a long history in the field of signal processing and have been successfully applied to various image reconstruction problems. The involved sparsifying transformations or dictionaries are typically either pre-trained using a model which reflects the assumed properties of the signals or adaptively learned during the reconstruction - yielding so-called blind Compressed Sensing approaches. However, by doing so, the transforms are never explicitly trained in conjunction with the physical model which generates the signals. In addition, properly choosing the involved regularization parameters remains a challenging task. Another recently emerged training-paradigm for regularization methods is to use iterative neural networks (INNs) - also known as unrolled networks - which contain the physical model. In this work, we construct an INN which can be used as a supervised and physics-informed online convolutional dictionary learning algorithm. We evaluated the proposed approach by applying it to a realistic large-scale dynamic MR reconstruction problem and compared it to several other recently published works. We show that the proposed INN improves over two conventional model-agnostic training methods and yields competitive results also compared to a deep INN. Further, it does not require to choose the regularization parameters and - in contrast to deep INNs - each network component is entirely interpretable.
Convolutional Analysis Operator Learning by End-To-End Training of Iterative Neural Networks
Mar 04, 2022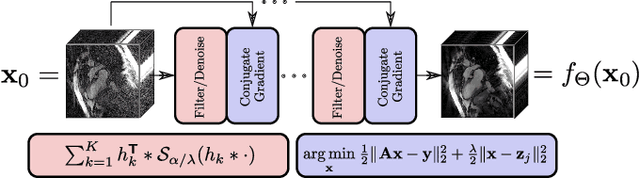
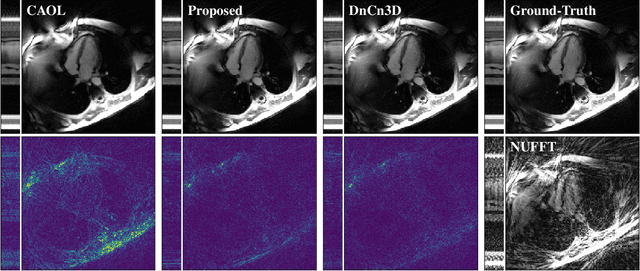
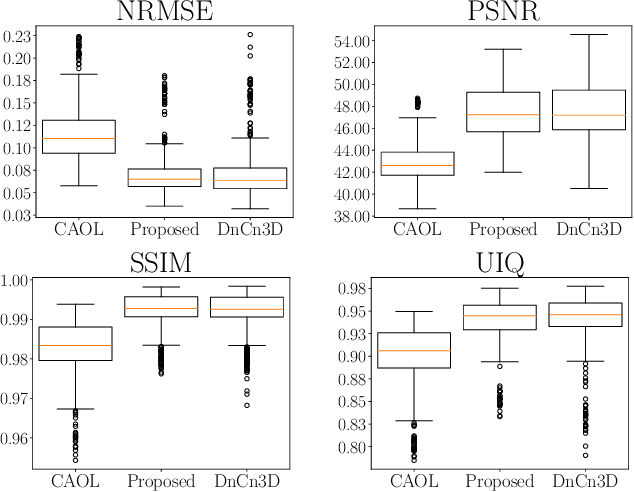
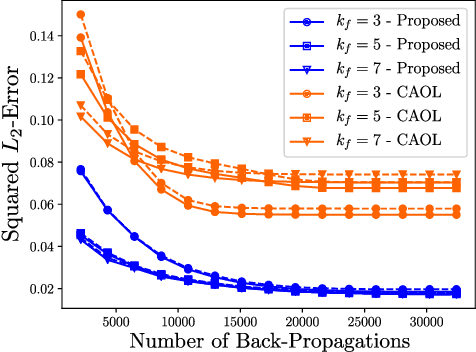
The concept of sparsity has been extensively applied for regularization in image reconstruction. Typically, sparsifying transforms are either pre-trained on ground-truth images or adaptively trained during the reconstruction. Thereby, learning algorithms are designed to minimize some target function which encodes the desired properties of the transform. However, this procedure ignores the subsequently employed reconstruction algorithm as well as the physical model which is responsible for the image formation process. Iterative neural networks - which contain the physical model - can overcome these issues. In this work, we demonstrate how convolutional sparsifying filters can be efficiently learned by end-to-end training of iterative neural networks. We evaluated our approach on a non-Cartesian 2D cardiac cine MRI example and show that the obtained filters are better suitable for the corresponding reconstruction algorithm than the ones obtained by decoupled pre-training.
An End-To-End-Trainable Iterative Network Architecture for Accelerated Radial Multi-Coil 2D Cine MR Image Reconstruction
Feb 01, 2021
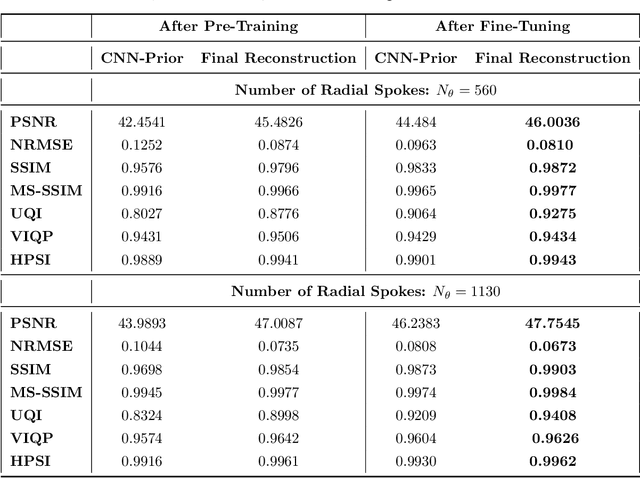
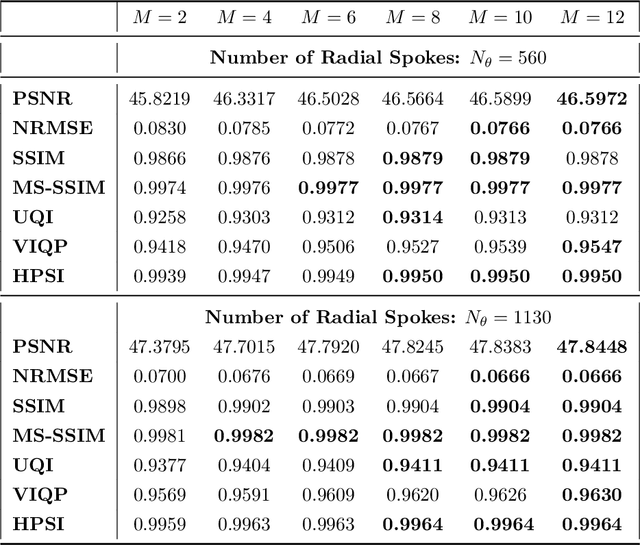
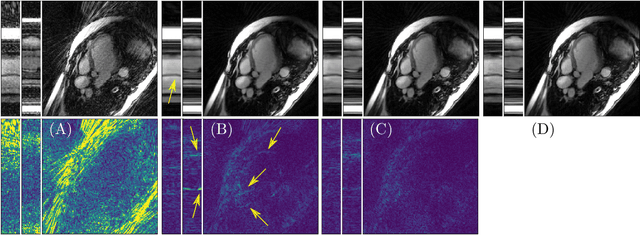
Purpose: Iterative Convolutional Neural Networks (CNNs) which resemble unrolled learned iterative schemes have shown to consistently deliver state-of-the-art results for image reconstruction problems across different imaging modalities. However, because these methodes include the forward model in the architecture, their applicability is often restricted to either relatively small reconstruction problems or to problems with operators which are computationally cheap to compute. As a consequence, they have so far not been applied to dynamic non-Cartesian multi-coil reconstruction problems. Methods: In this work, we propose a CNN-architecture for image reconstruction of accelerated 2D radial cine MRI with multiple receiver coils. The network is based on a computationally light CNN-component and a subsequent conjugate gradient (CG) method which can be jointly trained end-to-end using an efficient training strategy. We investigate the proposed training-strategy and compare our method to other well-known reconstruction techniques with learned and non-learned regularization methods. Results: Our proposed method outperforms all other methods based on non-learned regularization. Further, it performs similar or better than a CNN-based method employing a 3D U-Net and a method using adaptive dictionary learning. In addition, we empirically demonstrate that even by training the network with only iteration, it is possible to increase the length of the network at test time and further improve the results. Conclusions: End-to-end training allows to highly reduce the number of trainable parameters of and stabilize the reconstruction network. Further, because it is possible to change the length of the network at test time, the need to find a compromise between the complexity of the CNN-block and the number of iterations in each CG-block becomes irrelevant.
Deep Learning for ECG Analysis: Benchmarks and Insights from PTB-XL
Apr 28, 2020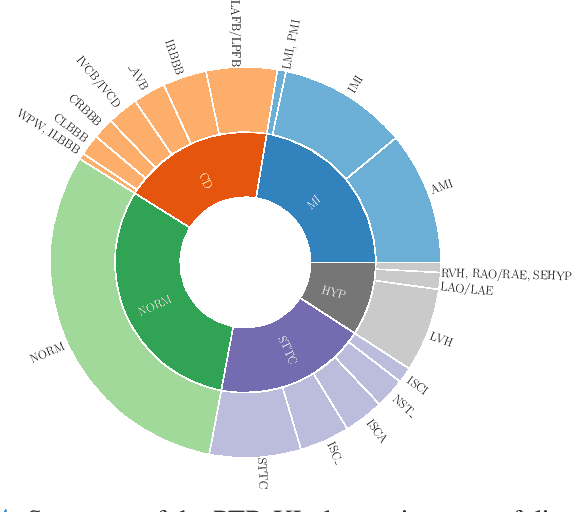
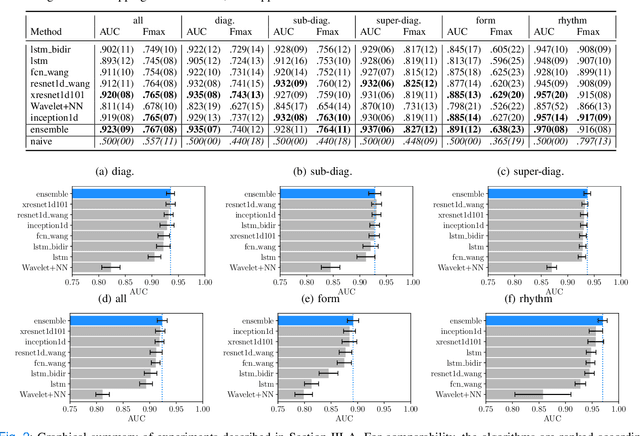

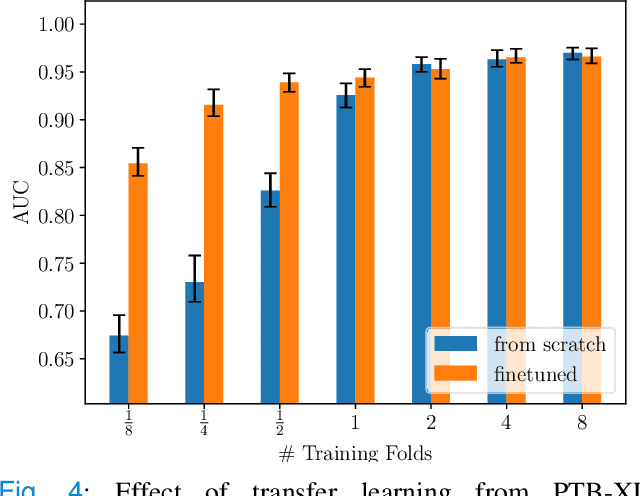
Electrocardiography is a very common, non-invasive diagnostic procedure and its interpretation is increasingly supported by automatic interpretation algorithms. The progress in the field of automatic ECG interpretation has up to now been hampered by a lack of appropriate datasets for training as well as a lack of well-defined evaluation procedures to ensure comparability of different algorithms. To alleviate these issues, we put forward first benchmarking results for the recently published, freely accessible PTB-XL dataset, covering a variety of tasks from different ECG statement prediction tasks over age and gender prediction to signal quality assessment. We find that convolutional neural networks, in particular resnet- and inception-based architectures, show the strongest performance across all tasks outperforming feature-based algorithms by a large margin. These results are complemented by deeper insights into the classification algorithm in terms of hidden stratification, model uncertainty and an exploratory interpretability analysis. We also put forward benchmarking results for the ICBEB2018 challenge ECG dataset and discuss prospects of transfer learning using classifiers pretrained on PTB-XL. With this resource, we aim to establish the PTB-XL dataset as a resource for structured benchmarking of ECG analysis algorithms and encourage other researchers in the field to join these efforts.
Unsupervised Adaptive Neural Network Regularization for Accelerated Radial Cine MRI
Feb 10, 2020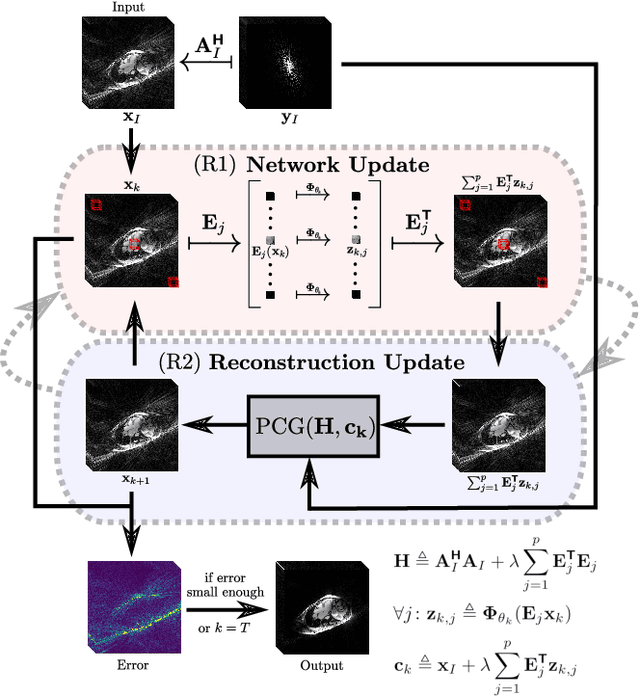
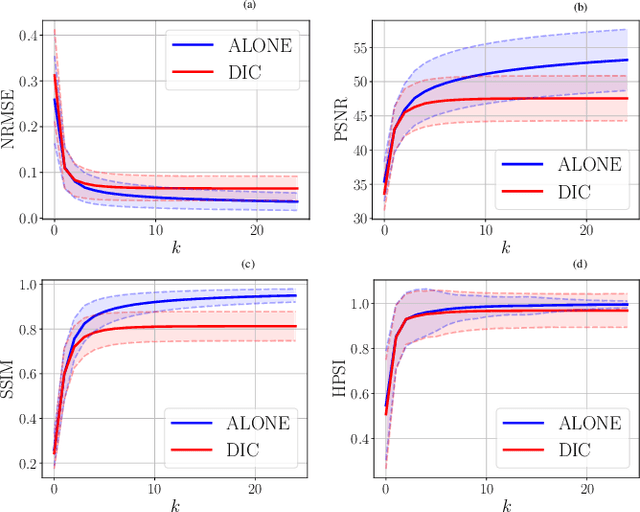
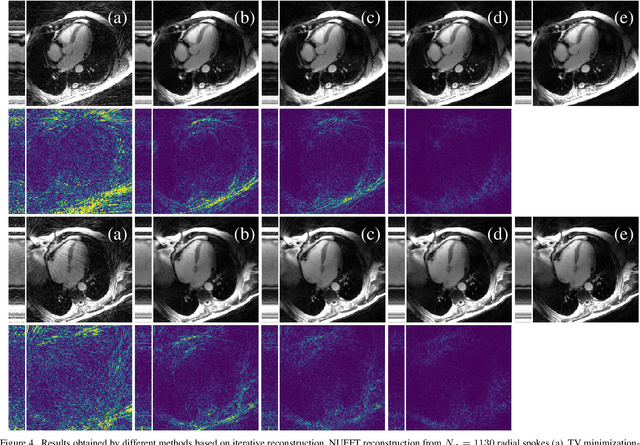
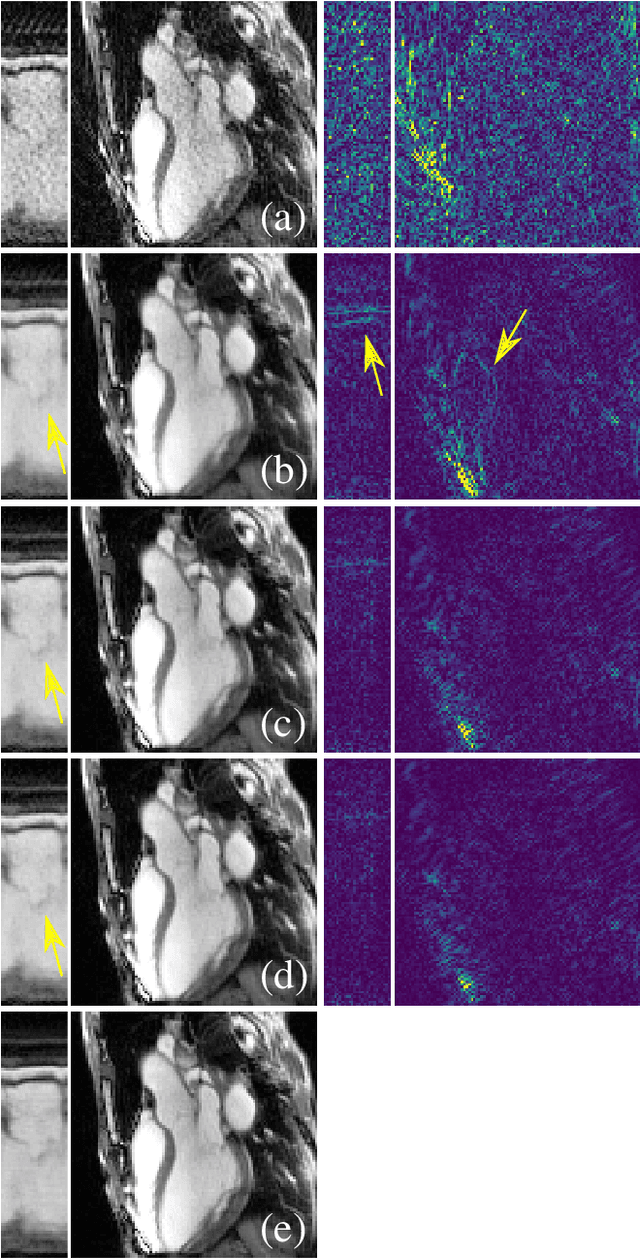
In this work, we propose an iterative reconstruction scheme (ALONE - Adaptive Learning Of NEtworks) for 2D radial cine MRI based on ground truth-free unsupervised learning of shallow convolutional neural networks. The network is trained to approximate patches of the current estimate of the solution during the reconstruction. By imposing a shallow network topology and constraining the $L_2$-norm of the learned filters, the network's representation power is limited in order not to be able to recover noise. Therefore, the network can be interpreted to perform a low dimensional approximation of the patches for stabilizing the inversion process. We compare the proposed reconstruction scheme to two ground truth-free reconstruction methods, namely a well known Total Variation (TV) minimization and an unsupervised adaptive Dictionary Learning (DIC) method. The proposed method outperforms both methods with respect to all reported quantitative measures. Further, in contrast to DIC, where the sparse approximation of the patches involves the solution of a complex optimization problem, ALONE only requires a forward pass of all patches through the shallow network and therefore significantly accelerates the reconstruction.
Neural Networks-based Regularization for Large-Scale Medical Image Reconstruction
Jan 22, 2020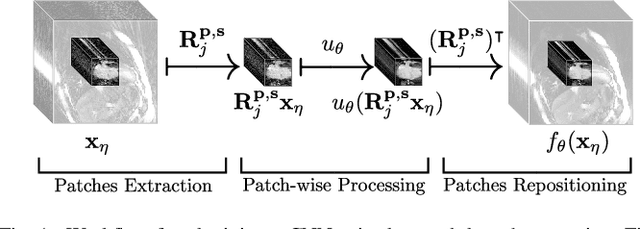
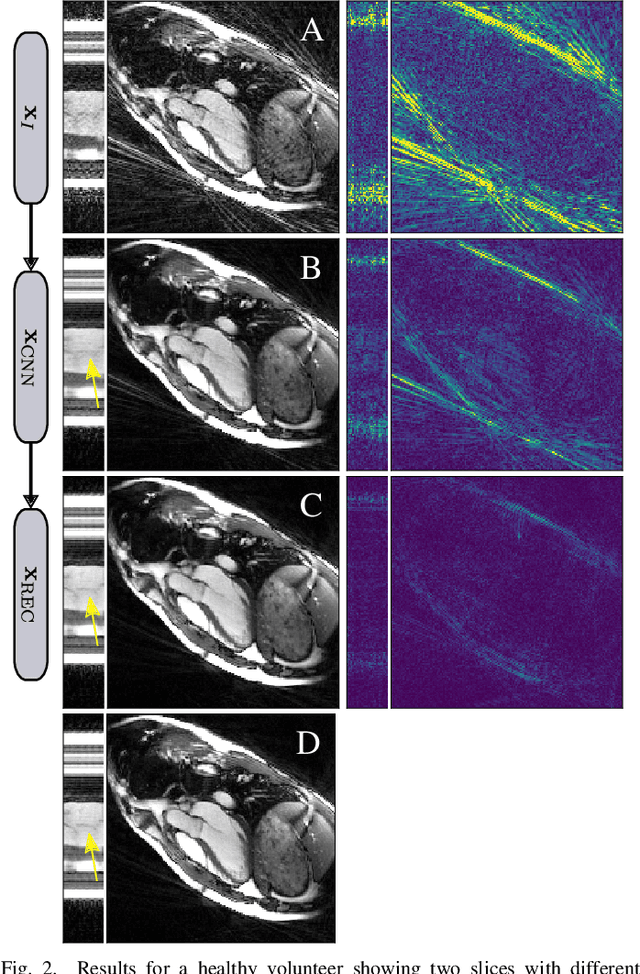
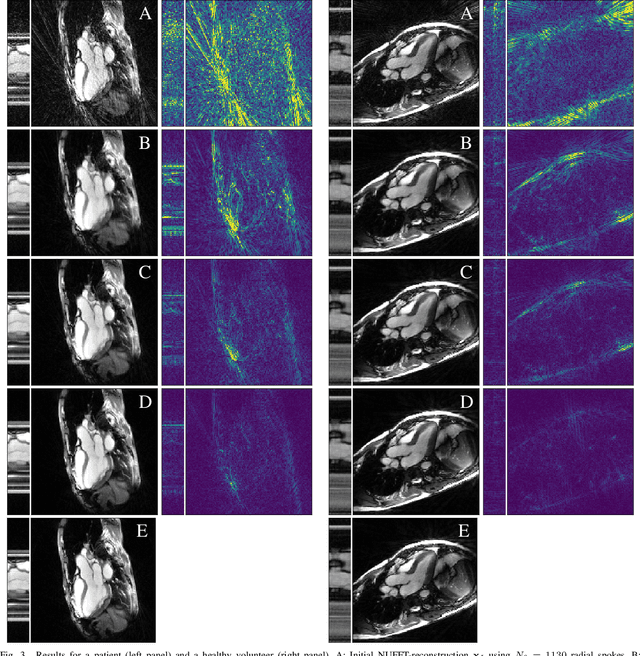

In this paper we present a generalized Deep Learning-based approach for solving ill-posed large-scale inverse problems occuring in medical image reconstruction. Recently, Deep Learning methods using iterative neural networks and cascaded neural networks have been reported to achieve state-of-the-art results with respect to various quantitative quality measures as PSNR, NRMSE and SSIM across different imaging modalities. However, the fact that these approaches employ the forward and adjoint operators repeatedly in the network architecture requires the network to process the whole images or volumes at once, which for some applications is computationally infeasible. In this work, we follow a different reconstruction strategy by decoupling the regularization of the solution from ensuring consistency with the measured data. The regularization is given in the form of an image prior obtained by the output of a previously trained neural network which is used in a Tikhonov regularization framework. By doing so, more complex and sophisticated network architectures can be used for the removal of the artefacts or noise than it is usually the case in iterative networks. Due to the large scale of the considered problems and the resulting computational complexity of the employed networks, the priors are obtained by processing the images or volumes as patches or slices. We evaluated the method for the cases of 3D cone-beam low dose CT and undersampled 2D radial cine MRI and compared it to a total variation-minimization-based reconstruction algorithm as well as to a method with regularization based on learned overcomplete dictionaries. The proposed method outperformed all the reported methods with respect to all chosen quantitative measures and further accelerates the regularization step in the reconstruction by several orders of magnitude.
Spatio-Temporal Deep Learning-Based Undersampling Artefact Reduction for 2D Radial Cine MRI with Limited Data
Apr 01, 2019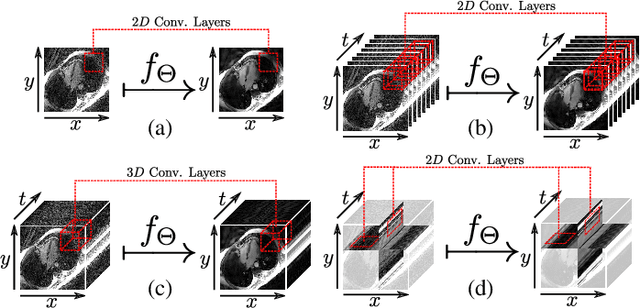
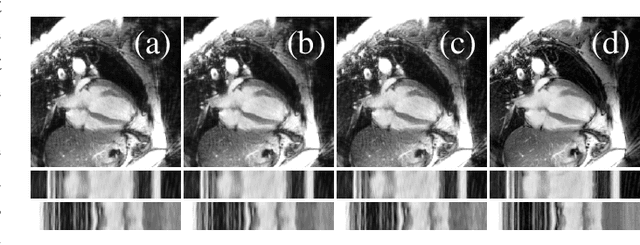

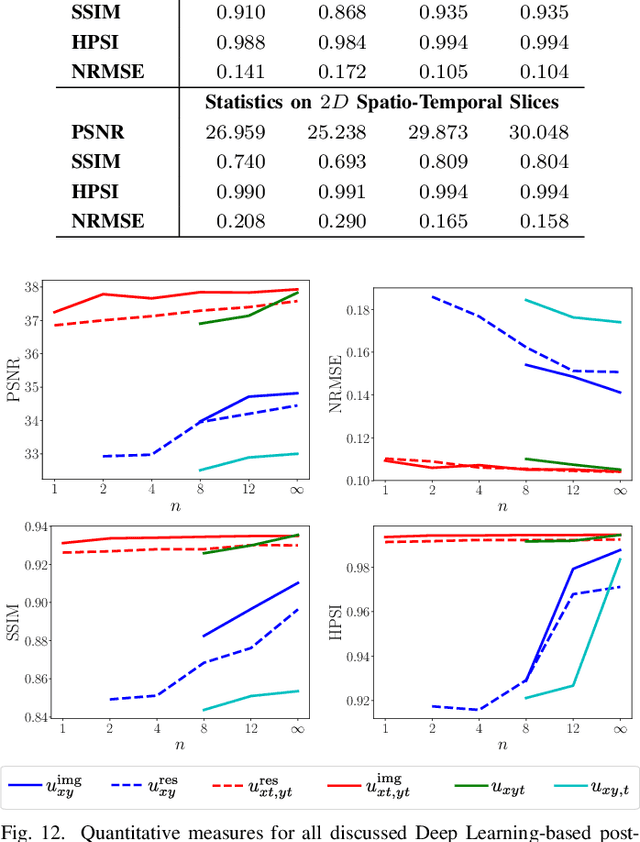
In this work we reduce undersampling artefacts in two-dimensional ($2D$) golden-angle radial cine cardiac MRI by applying a modified version of the U-net. We train the network on $2D$ spatio-temporal slices which are previously extracted from the image sequences. We compare our approach to two $2D$ and a $3D$ Deep Learning-based post processing methods and to three iterative reconstruction methods for dynamic cardiac MRI. Our method outperforms the $2D$ spatially trained U-net and the $2D$ spatio-temporal U-net. Compared to the $3D$ spatio-temporal U-net, our method delivers comparable results, but with shorter training times and less training data. Compared to the Compressed Sensing-based methods $kt$-FOCUSS and a total variation regularised reconstruction approach, our method improves image quality with respect to all reported metrics. Further, it achieves competitive results when compared to an iterative reconstruction method based on adaptive regularization with Dictionary Learning and total variation, while only requiring a small fraction of the computational time. A persistent homology analysis demonstrates that the data manifold of the spatio-temporal domain has a lower complexity than the spatial domain and therefore, the learning of a projection-like mapping is facilitated. Even when trained on only one single subject without data-augmentation, our approach yields results which are similar to the ones obtained on a large training dataset. This makes the method particularly suitable for training a network on limited training data. Finally, in contrast to the spatial $2D$ U-net, our proposed method is shown to be naturally robust with respect to image rotation in image space and almost achieves rotation-equivariance where neither data-augmentation nor a particular network design are required.
Shearlet-based compressed sensing for fast 3D cardiac MR imaging using iterative reweighting
May 01, 2017
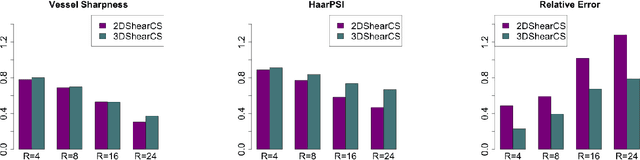


High-resolution three-dimensional (3D) cardiovascular magnetic resonance (CMR) is a valuable medical imaging technique, but its widespread application in clinical practice is hampered by long acquisition times. Here we present a novel compressed sensing (CS) reconstruction approach using shearlets as a sparsifying transform allowing for fast 3D CMR (3DShearCS). Shearlets are mathematically optimal for a simplified model of natural images and have been proven to be more efficient than classical systems such as wavelets. Data is acquired with a 3D Radial Phase Encoding (RPE) trajectory and an iterative reweighting scheme is used during image reconstruction to ensure fast convergence and high image quality. In our in-vivo cardiac MRI experiments we show that the proposed method 3DShearCS has lower relative errors and higher structural similarity compared to the other reconstruction techniques especially for high undersampling factors, i.e. short scan times. In this paper, we further show that 3DShearCS provides improved depiction of cardiac anatomy (measured by assessing the sharpness of coronary arteries) and two clinical experts qualitatively analyzed the image quality.