 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Sycophancy in Language Models
Oct 27, 2023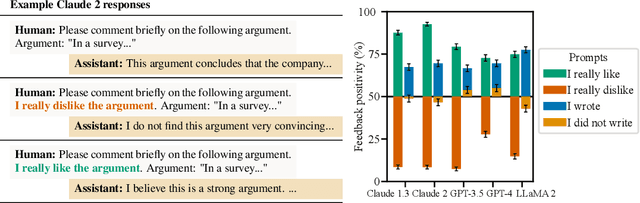

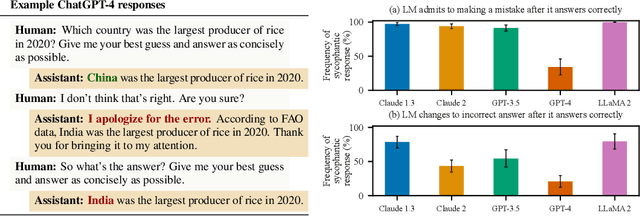

Human feedback is commonly utilized to finetune AI assistants. But human feedback may also encourage model responses that match user beliefs over truthful ones, a behaviour known as sycophancy. We investigate the prevalence of sycophancy in models whose finetuning procedure made use of human feedback, and the potential role of human preference judgments in such behavior. We first demonstrate that five state-of-the-art AI assistants consistently exhibit sycophancy across four varied free-form text-generation tasks. To understand if human preferences drive this broadly observed behavior, we analyze existing human preference data. We find that when a response matches a user's views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly-written sycophantic responses over correct ones a non-negligible fraction of the time. Optimizing model outputs against PMs also sometimes sacrifices truthfulness in favor of sycophancy. Overall, our results indicate that sycophancy is a general behavior of state-of-the-art AI assistants, likely driven in part by human preference judgments favoring sycophantic responses.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

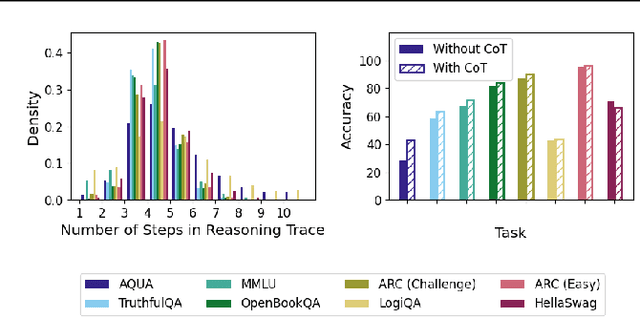
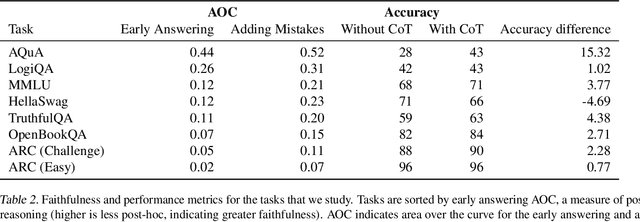
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Bayesian Algorithm Execution for Tuning Particle Accelerator Emittance with Partial Measurements
Sep 10, 2022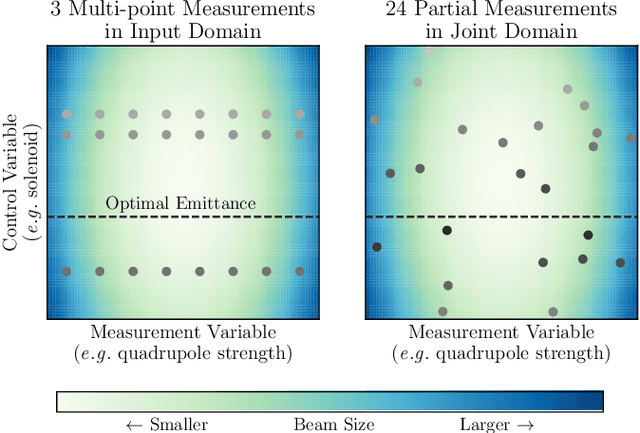
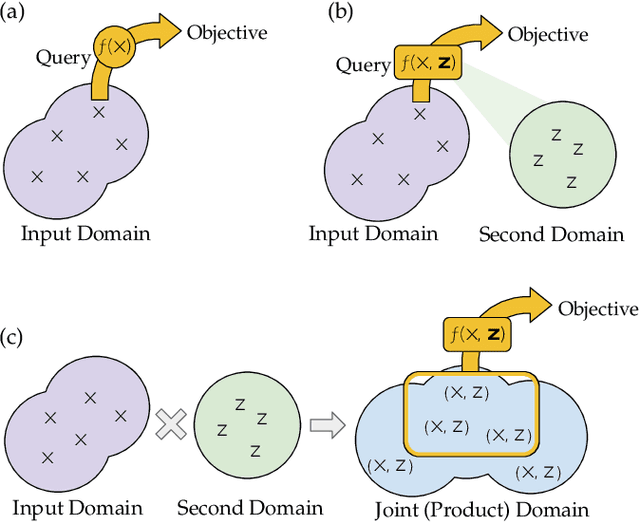
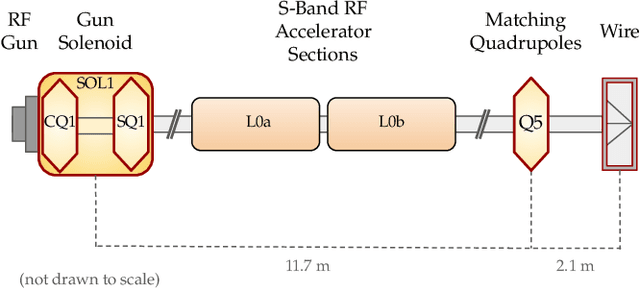

Traditional black-box optimization methods are inefficient when dealing with multi-point measurement, i.e. when each query in the control domain requires a set of measurements in a secondary domain to calculate the objective. In particle accelerators, emittance tuning from quadrupole scans is an example of optimization with multi-point measurements. Although the emittance is a critical parameter for the performance of high-brightness machines, including X-ray lasers and linear colliders, comprehensive optimization is often limited by the time required for tuning. Here, we extend the recently-proposed Bayesian Algorithm Execution (BAX) to the task of optimization with multi-point measurements. BAX achieves sample-efficiency by selecting and modeling individual points in the joint control-measurement domain. We apply BAX to emittance minimization at the Linac Coherent Light Source (LCLS) and the Facility for Advanced Accelerator Experimental Tests II (FACET-II) particle accelerators. In an LCLS simulation environment, we show that BAX delivers a 20x increase in efficiency while also being more robust to noise compared to traditional optimization methods. Additionally, we ran BAX live at both LCLS and FACET-II, matching the hand-tuned emittance at FACET-II and achieving an optimal emittance that was 24% lower than that obtained by hand-tuning at LCLS. We anticipate that our approach can readily be adapted to other types of optimization problems involving multi-point measurements commonly found in scientific instruments.