 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Retrieval-Augmented Generation vs. Long-Context Input for Clinical Reasoning over EHRs
Aug 20, 2025Electronic health records (EHRs) are long, noisy, and often redundant, posing a major challenge for the clinicians who must navigate them. Large language models (LLMs) offer a promising solution for extracting and reasoning over this unstructured text, but the length of clinical notes often exceeds even state-of-the-art models' extended context windows. Retrieval-augmented generation (RAG) offers an alternative by retrieving task-relevant passages from across the entire EHR, potentially reducing the amount of required input tokens. In this work, we propose three clinical tasks designed to be replicable across health systems with minimal effort: 1) extracting imaging procedures, 2) generating timelines of antibiotic use, and 3) identifying key diagnoses. Using EHRs from actual hospitalized patients, we test three state-of-the-art LLMs with varying amounts of provided context, using either targeted text retrieval or the most recent clinical notes. We find that RAG closely matches or exceeds the performance of using recent notes, and approaches the performance of using the models' full context while requiring drastically fewer input tokens. Our results suggest that RAG remains a competitive and efficient approach even as newer models become capable of handling increasingly longer amounts of text.
Using tournaments to calculate AUROC for zero-shot classification with LLMs
Feb 20, 2025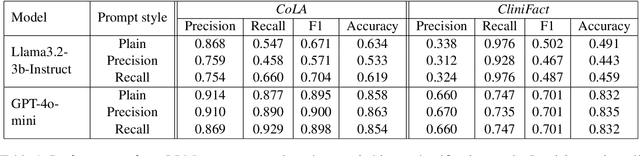
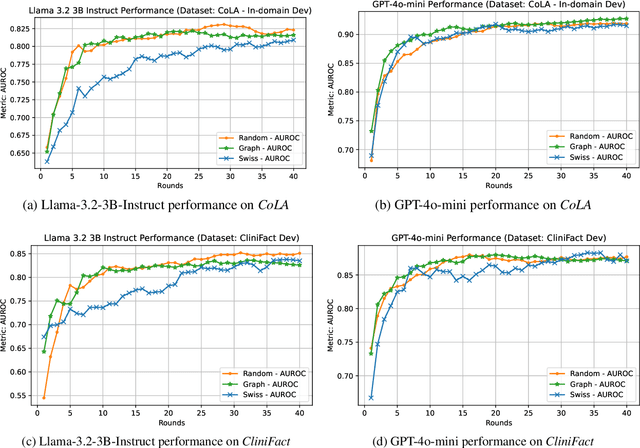
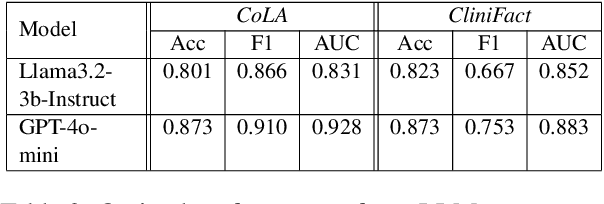
Large language models perform surprisingly well on many zero-shot classification tasks, but are difficult to fairly compare to supervised classifiers due to the lack of a modifiable decision boundary. In this work, we propose and evaluate a method that converts binary classification tasks into pairwise comparison tasks, obtaining relative rankings from LLMs. Repeated pairwise comparisons can be used to score instances using the Elo rating system (used in chess and other competitions), inducing a confidence ordering over instances in a dataset. We evaluate scheduling algorithms for their ability to minimize comparisons, and show that our proposed algorithm leads to improved classification performance, while also providing more information than traditional zero-shot classification.
Natural language processing to automatically extract the presence and severity of esophagitis in notes of patients undergoing radiotherapy
Mar 24, 2023Radiotherapy (RT) toxicities can impair survival and quality-of-life, yet remain under-studied. Real-world evidence holds potential to improve our understanding of toxicities, but toxicity information is often only in clinical notes. We developed natural language processing (NLP) models to identify the presence and severity of esophagitis from notes of patients treated with thoracic RT. We fine-tuned statistical and pre-trained BERT-based models for three esophagitis classification tasks: Task 1) presence of esophagitis, Task 2) severe esophagitis or not, and Task 3) no esophagitis vs. grade 1 vs. grade 2-3. Transferability was tested on 345 notes from patients with esophageal cancer undergoing RT. Fine-tuning PubmedBERT yielded the best performance. The best macro-F1 was 0.92, 0.82, and 0.74 for Task 1, 2, and 3, respectively. Selecting the most informative note sections during fine-tuning improved macro-F1 by over 2% for all tasks. Silver-labeled data improved the macro-F1 by over 3% across all tasks. For the esophageal cancer notes, the best macro-F1 was 0.73, 0.74, and 0.65 for Task 1, 2, and 3, respectively, without additional fine-tuning. To our knowledge, this is the first effort to automatically extract esophagitis toxicity severity according to CTCAE guidelines from clinic notes. The promising performance provides proof-of-concept for NLP-based automated detailed toxicity monitoring in expanded domains.