 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing tournaments to calculate AUROC for zero-shot classification with LLMs
Paper and Code
Feb 20, 2025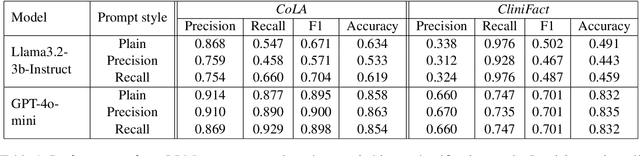
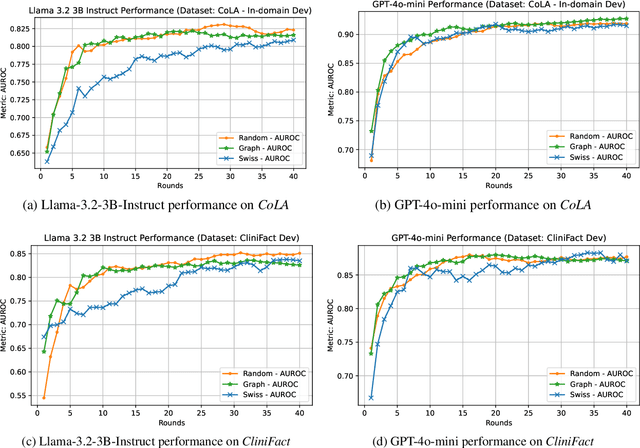
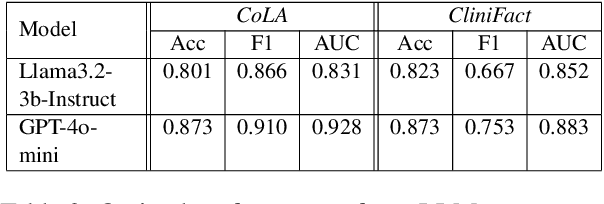
Large language models perform surprisingly well on many zero-shot classification tasks, but are difficult to fairly compare to supervised classifiers due to the lack of a modifiable decision boundary. In this work, we propose and evaluate a method that converts binary classification tasks into pairwise comparison tasks, obtaining relative rankings from LLMs. Repeated pairwise comparisons can be used to score instances using the Elo rating system (used in chess and other competitions), inducing a confidence ordering over instances in a dataset. We evaluate scheduling algorithms for their ability to minimize comparisons, and show that our proposed algorithm leads to improved classification performance, while also providing more information than traditional zero-shot classification.