 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonalization without Diagonalization: A Direct Optimization Approach for Solid-State Density Functional Theory
Nov 06, 2024



We present a novel approach to address the challenges of variable occupation numbers in direct optimization of density functional theory (DFT). By parameterizing both the eigenfunctions and the occupation matrix, our method minimizes the free energy with respect to these parameters. As the stationary conditions require the occupation matrix and the Kohn-Sham Hamiltonian to be simultaneously diagonalizable, this leads to the concept of ``self-diagonalization,'' where, by assuming a diagonal occupation matrix without loss of generality, the Hamiltonian matrix naturally becomes diagonal at stationary points. Our method incorporates physical constraints on both the eigenfunctions and the occupations into the parameterization, transforming the constrained optimization into an fully differentiable unconstrained problem, which is solvable via gradient descent. Implemented in JAX, our method was tested on aluminum and silicon, confirming that it achieves efficient self-diagonalization, produces the correct Fermi-Dirac distribution of the occupation numbers and yields band structures consistent with those obtained with SCF methods in Quantum Espresso.
Nonparametric Generative Modeling with Conditional and Locally-Connected Sliced-Wasserstein Flows
May 03, 2023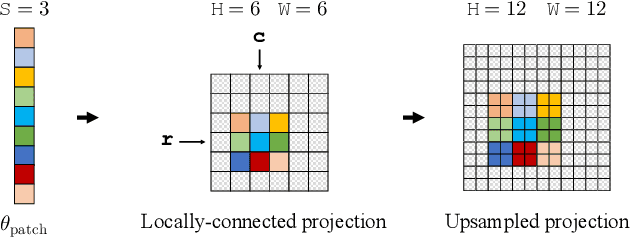
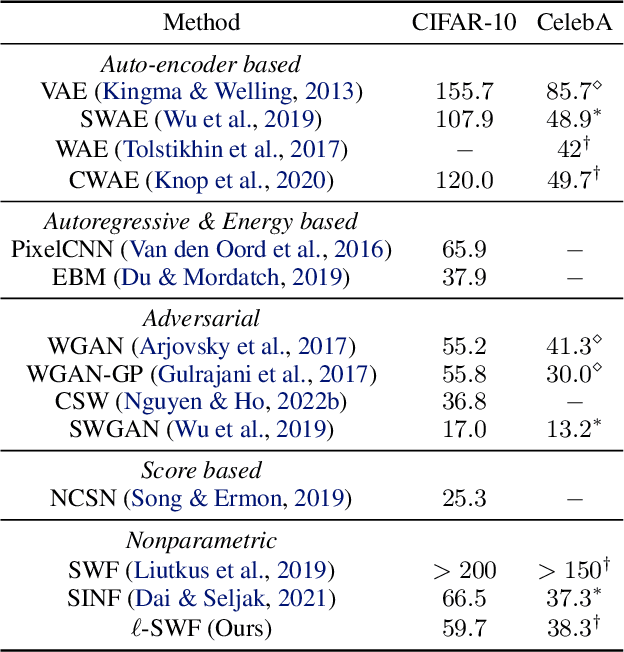

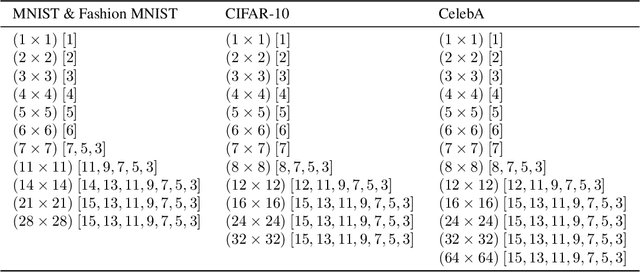
Sliced-Wasserstein Flow (SWF) is a promising approach to nonparametric generative modeling but has not been widely adopted due to its suboptimal generative quality and lack of conditional modeling capabilities. In this work, we make two major contributions to bridging this gap. First, based on a pleasant observation that (under certain conditions) the SWF of joint distributions coincides with those of conditional distributions, we propose Conditional Sliced-Wasserstein Flow (CSWF), a simple yet effective extension of SWF that enables nonparametric conditional modeling. Second, we introduce appropriate inductive biases of images into SWF with two techniques inspired by local connectivity and multiscale representation in vision research, which greatly improve the efficiency and quality of modeling images. With all the improvements, we achieve generative performance comparable with many deep parametric generative models on both conditional and unconditional tasks in a purely nonparametric fashion, demonstrating its great potential.
D4FT: A Deep Learning Approach to Kohn-Sham Density Functional Theory
Mar 01, 2023



Kohn-Sham Density Functional Theory (KS-DFT) has been traditionally solved by the Self-Consistent Field (SCF) method. Behind the SCF loop is the physics intuition of solving a system of non-interactive single-electron wave functions under an effective potential. In this work, we propose a deep learning approach to KS-DFT. First, in contrast to the conventional SCF loop, we propose to directly minimize the total energy by reparameterizing the orthogonal constraint as a feed-forward computation. We prove that such an approach has the same expressivity as the SCF method, yet reduces the computational complexity from O(N^4) to O(N^3). Second, the numerical integration which involves a summation over the quadrature grids can be amortized to the optimization steps. At each step, stochastic gradient descent (SGD) is performed with a sampled minibatch of the grids. Extensive experiments are carried out to demonstrate the advantage of our approach in terms of efficiency and stability. In addition, we show that our approach enables us to explore more complex neural-based wave functions.
Mitigating Performance Saturation in Neural Marked Point Processes: Architectures and Loss Functions
Jul 07, 2021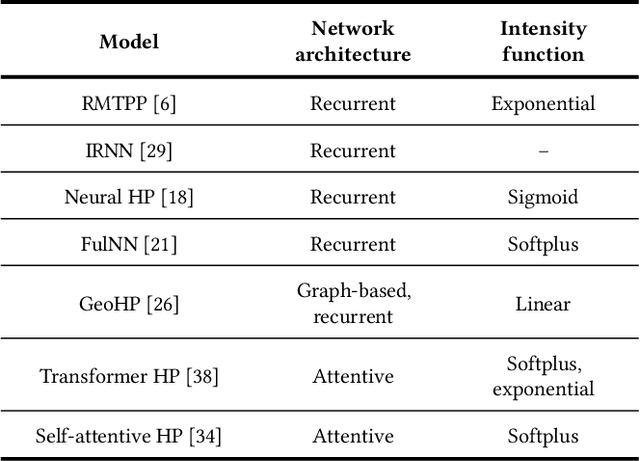


Attributed event sequences are commonly encountered in practice. A recent research line focuses on incorporating neural networks with the statistical model -- marked point processes, which is the conventional tool for dealing with attributed event sequences. Neural marked point processes possess good interpretability of probabilistic models as well as the representational power of neural networks. However, we find that performance of neural marked point processes is not always increasing as the network architecture becomes more complicated and larger, which is what we call the performance saturation phenomenon. This is due to the fact that the generalization error of neural marked point processes is determined by both the network representational ability and the model specification at the same time. Therefore we can draw two major conclusions: first, simple network structures can perform no worse than complicated ones for some cases; second, using a proper probabilistic assumption is as equally, if not more, important as improving the complexity of the network. Based on this observation, we propose a simple graph-based network structure called GCHP, which utilizes only graph convolutional layers, thus it can be easily accelerated by the parallel mechanism. We directly consider the distribution of interarrival times instead of imposing a specific assumption on the conditional intensity function, and propose to use a likelihood ratio loss with a moment matching mechanism for optimization and model selection. Experimental results show that GCHP can significantly reduce training time and the likelihood ratio loss with interarrival time probability assumptions can greatly improve the model performance.