 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
Jul 17, 2024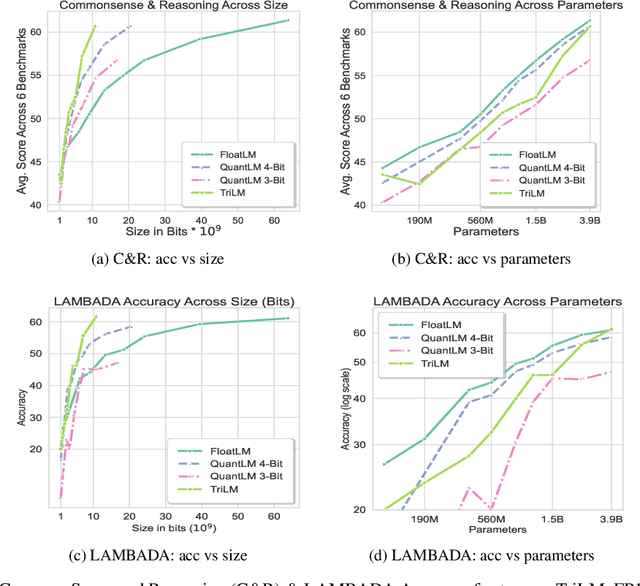

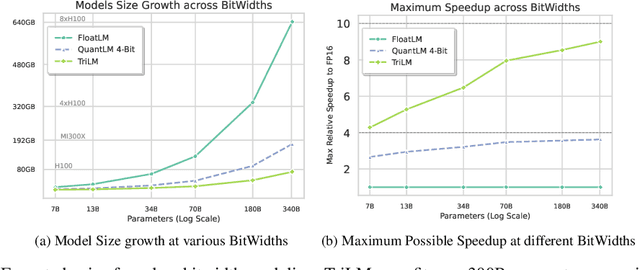
Post-training quantization is the leading method for addressing memory-related bottlenecks in LLM inference, but unfortunately, it suffers from significant performance degradation below 4-bit precision. An alternative approach involves training compressed models directly at a low bitwidth (e.g., binary or ternary models). However, the performance, training dynamics, and scaling trends of such models are not yet well understood. To address this issue, we train and openly release the Spectra LLM suite consisting of 54 language models ranging from 99M to 3.9B parameters, trained on 300B tokens. Spectra includes FloatLMs, post-training quantized QuantLMs (3, 4, 6, and 8 bits), and ternary LLMs (TriLMs) - our improved architecture for ternary language modeling, which significantly outperforms previously proposed ternary models of a given size (in bits), matching half-precision models at scale. For example, TriLM 3.9B is (bit-wise) smaller than the half-precision FloatLM 830M, but matches half-precision FloatLM 3.9B in commonsense reasoning and knowledge benchmarks. However, TriLM 3.9B is also as toxic and stereotyping as FloatLM 3.9B, a model six times larger in size. Additionally, TriLM 3.9B lags behind FloatLM in perplexity on validation splits and web-based corpora but performs better on less noisy datasets like Lambada and PennTreeBank. To enhance understanding of low-bitwidth models, we are releasing 500+ intermediate checkpoints of the Spectra suite at \href{https://github.com/NolanoOrg/SpectraSuite}{https://github.com/NolanoOrg/SpectraSuite}.
LORD: Low Rank Decomposition Of Monolingual Code LLMs For One-Shot Compression
Sep 25, 2023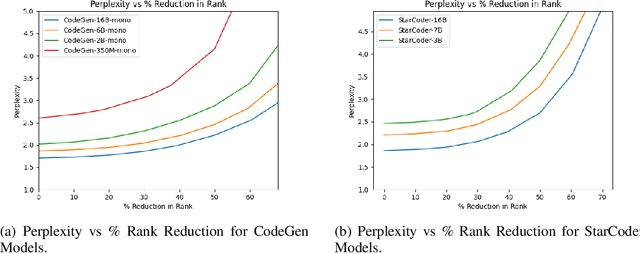
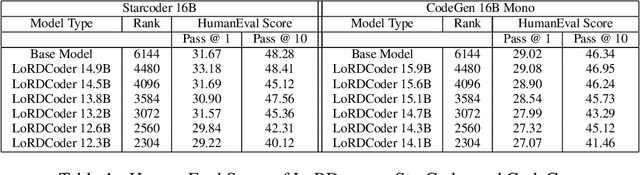
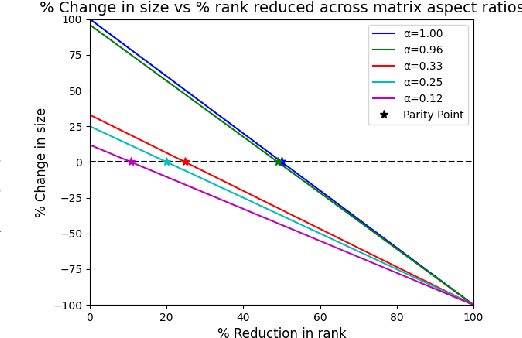
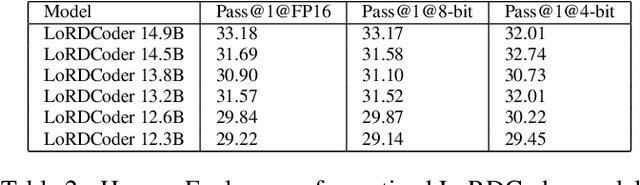
Low Rank Decomposition of matrix - splitting a large matrix into a product of two smaller matrix offers a means for compression that reduces the parameters of a model without sparsification, and hence delivering more speedup on modern hardware. Moreover, unlike quantization, the compressed linear layers remain fully differentiable and all the parameters trainable, while being able to leverage the existing highly efficient kernels over floating point matrices. We study the potential to compress Large Language Models (LLMs) for monolingual Code generation via Low Rank Decomposition (LoRD) and observe that ranks for the linear layers in these models can be reduced by upto 39.58% with less than 1% increase in perplexity. We then use Low Rank Decomposition (LoRD) to compress StarCoder 16B to 13.2B parameter with no drop and to 12.3B with minimal drop in HumanEval Pass@1 score, in less than 10 minutes on a single A100. The compressed models speeds up inference by up to 22.35% with just a single line of change in code over huggingface's implementation with pytorch backend. Low Rank Decomposition (LoRD) models remain compatible with state of the art near-lossless quantization method such as SpQR, which allows leveraging further compression gains of quantization. Lastly, QLoRA over Low Rank Decomposition (LoRD) model further reduces memory requirements by as much as 21.2% over vanilla QLoRA while offering similar gains from parameter efficient fine tuning. Our work shows Low Rank Decomposition (LoRD) as a promising new paradigm for LLM compression.
Logical Fallacy Detection
Feb 28, 2022
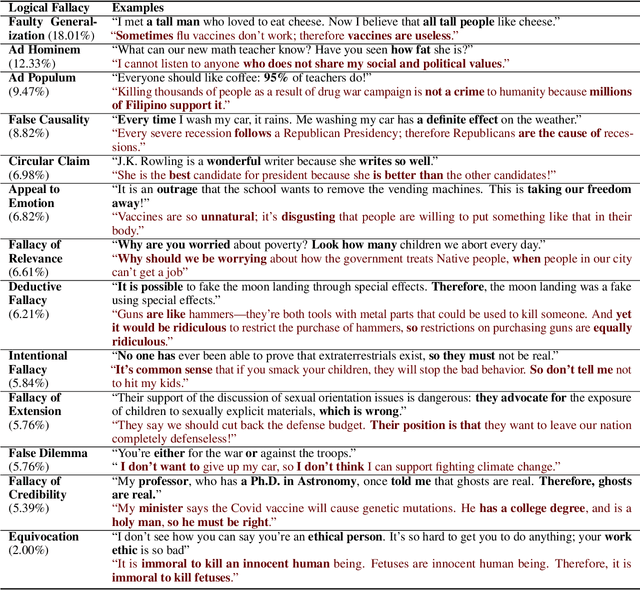
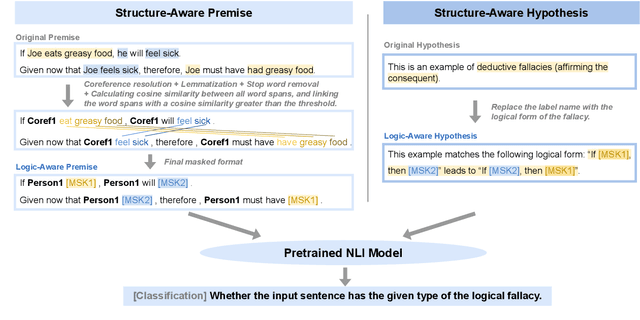
Reasoning is central to human intelligence. However, fallacious arguments are common, and some exacerbate problems such as spreading misinformation about climate change. In this paper, we propose the task of logical fallacy detection, and provide a new dataset (Logic) of logical fallacies generally found in text, together with an additional challenge set for detecting logical fallacies in climate change claims (LogicClimate). Detecting logical fallacies is a hard problem as the model must understand the underlying logical structure of the argument. We find that existing pretrained large language models perform poorly on this task. In contrast, we show that a simple structure-aware classifier outperforms the best language model by 5.46% on Logic and 3.86% on LogicClimate. We encourage future work to explore this task as (a) it can serve as a new reasoning challenge for language models, and (b) it can have potential applications in tackling the spread of misinformation.
Causal Direction of Data Collection Matters: Implications of Causal and Anticausal Learning for NLP
Oct 19, 2021
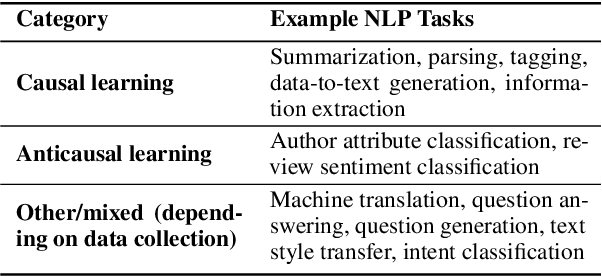
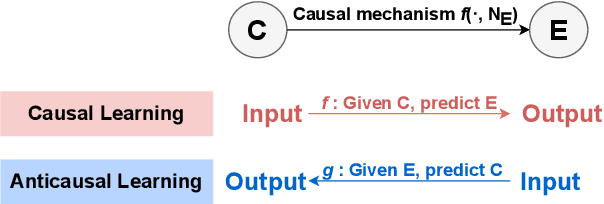
The principle of independent causal mechanisms (ICM) states that generative processes of real world data consist of independent modules which do not influence or inform each other. While this idea has led to fruitful developments in the field of causal inference, it is not widely-known in the NLP community. In this work, we argue that the causal direction of the data collection process bears nontrivial implications that can explain a number of published NLP findings, such as differences in semi-supervised learning (SSL) and domain adaptation (DA) performance across different settings. We categorize common NLP tasks according to their causal direction and empirically assay the validity of the ICM principle for text data using minimum description length. We conduct an extensive meta-analysis of over 100 published SSL and 30 DA studies, and find that the results are consistent with our expectations based on causal insights. This work presents the first attempt to analyze the ICM principle in NLP, and provides constructive suggestions for future modeling choices. Code available at https://github.com/zhijing-jin/icm4nlp
Hostility Detection in Hindi leveraging Pre-Trained Language Models
Jan 14, 2021
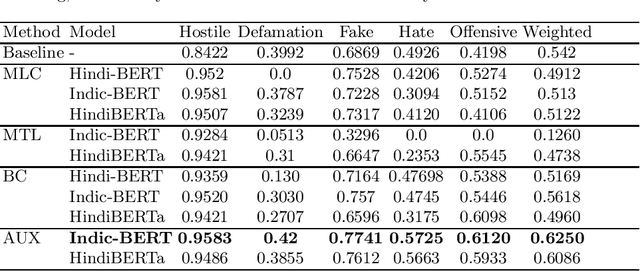
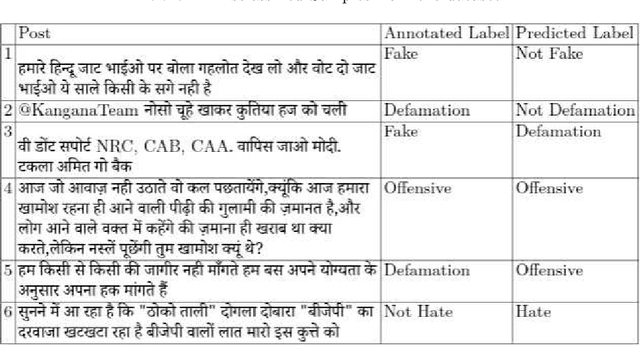
Hostile content on social platforms is ever increasing. This has led to the need for proper detection of hostile posts so that appropriate action can be taken to tackle them. Though a lot of work has been done recently in the English Language to solve the problem of hostile content online, similar works in Indian Languages are quite hard to find. This paper presents a transfer learning based approach to classify social media (i.e Twitter, Facebook, etc.) posts in Hindi Devanagari script as Hostile or Non-Hostile. Hostile posts are further analyzed to determine if they are Hateful, Fake, Defamation, and Offensive. This paper harnesses attention based pre-trained models fine-tuned on Hindi data with Hostile-Non hostile task as Auxiliary and fusing its features for further sub-tasks classification. Through this approach, we establish a robust and consistent model without any ensembling or complex pre-processing. We have presented the results from our approach in CONSTRAINT-2021 Shared Task on hostile post detection where our model performs extremely well with 3rd runner up in terms of Weighted Fine-Grained F1 Score.
Domain specific BERT representation for Named Entity Recognition of lab protocol
Dec 21, 2020
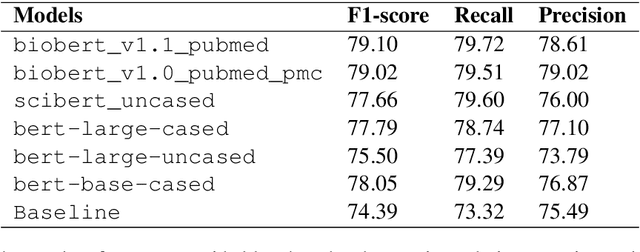
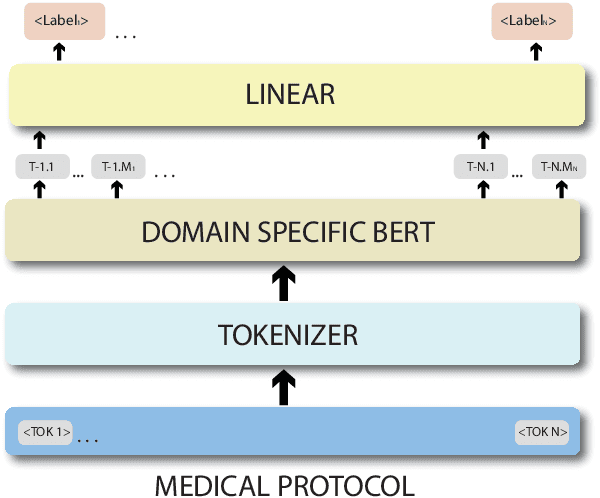

Supervised models trained to predict properties from representations have been achieving high accuracy on a variety of tasks. For instance, the BERT family seems to work exceptionally well on the downstream task from NER tagging to the range of other linguistic tasks. But the vocabulary used in the medical field contains a lot of different tokens used only in the medical industry such as the name of different diseases, devices, organisms, medicines, etc. that makes it difficult for traditional BERT model to create contextualized embedding. In this paper, we are going to illustrate the System for Named Entity Tagging based on Bio-Bert. Experimental results show that our model gives substantial improvements over the baseline and stood the fourth runner up in terms of F1 score, and first runner up in terms of Recall with just 2.21 F1 score behind the best one.
Leveraging Event Specific and Chunk Span features to Extract COVID Events from tweets
Dec 18, 2020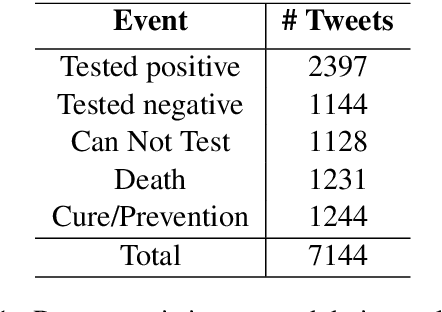


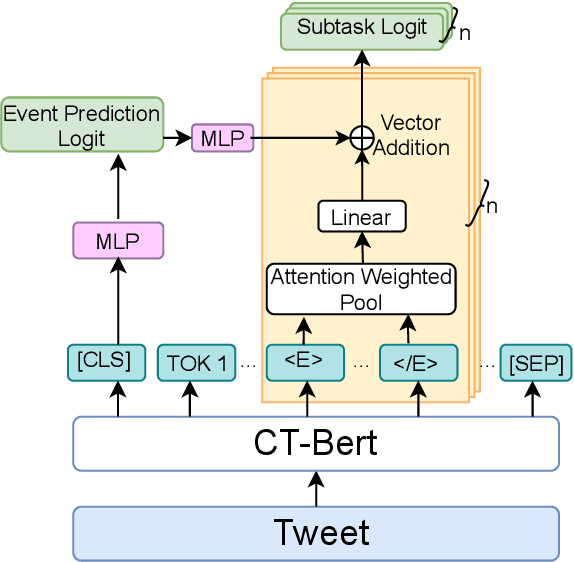
Twitter has acted as an important source of information during disasters and pandemic, especially during the times of COVID-19. In this paper, we describe our system entry for WNUT 2020 Shared Task-3. The task was aimed at automating the extraction of a variety of COVID-19 related events from Twitter, such as individuals who recently contracted the virus, someone with symptoms who were denied testing and believed remedies against the infection. The system consists of separate multi-task models for slot-filling subtasks and sentence-classification subtasks while leveraging the useful sentence-level information for the corresponding event. The system uses COVID-Twitter-Bert with attention-weighted pooling of candidate slot-chunk features to capture the useful information chunks. The system ranks 1st at the leader-board with F1 of 0.6598, without using any ensembles or additional datasets. The code and trained models are available at this https URL.