 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Forgery Detection for Surveillance Cameras: A Review
May 04, 2025



The widespread availability of video recording through smartphones and digital devices has made video-based evidence more accessible than ever. Surveillance footage plays a crucial role in security, law enforcement, and judicial processes. However, with the rise of advanced video editing tools, tampering with digital recordings has become increasingly easy, raising concerns about their authenticity. Ensuring the integrity of surveillance videos is essential, as manipulated footage can lead to misinformation and undermine judicial decisions. This paper provides a comprehensive review of existing forensic techniques used to detect video forgery, focusing on their effectiveness in verifying the authenticity of surveillance recordings. Various methods, including compression-based analysis, frame duplication detection, and machine learning-based approaches, are explored. The findings highlight the growing necessity for more robust forensic techniques to counteract evolving forgery methods. Strengthening video forensic capabilities will ensure that surveillance recordings remain credible and admissible as legal evidence.
Speaker Diarization for Low-Resource Languages Through Wav2vec Fine-Tuning
Apr 23, 2025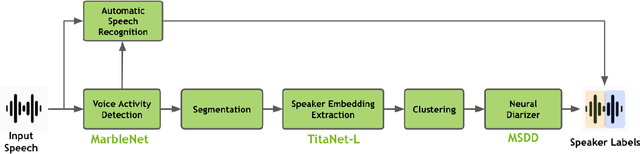


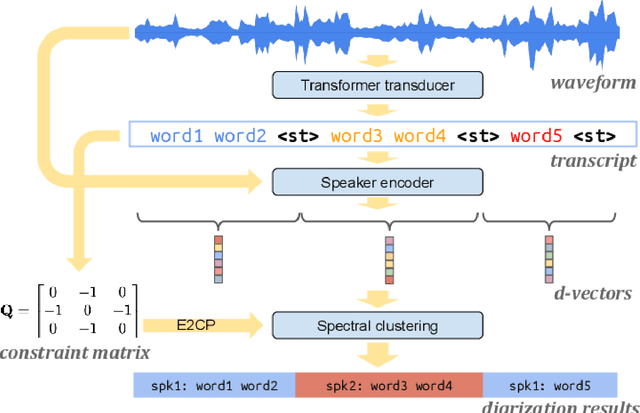
Speaker diarization is a fundamental task in speech processing that involves dividing an audio stream by speaker. Although state-of-the-art models have advanced performance in high-resource languages, low-resource languages such as Kurdish pose unique challenges due to limited annotated data, multiple dialects and frequent code-switching. In this study, we address these issues by training the Wav2Vec 2.0 self-supervised learning model on a dedicated Kurdish corpus. By leveraging transfer learning, we adapted multilingual representations learned from other languages to capture the phonetic and acoustic characteristics of Kurdish speech. Relative to a baseline method, our approach reduced the diarization error rate by seven point two percent and improved cluster purity by thirteen percent. These findings demonstrate that enhancements to existing models can significantly improve diarization performance for under-resourced languages. Our work has practical implications for developing transcription services for Kurdish-language media and for speaker segmentation in multilingual call centers, teleconferencing and video-conferencing systems. The results establish a foundation for building effective diarization systems in other understudied languages, contributing to greater equity in speech technology.
From Dialect Gaps to Identity Maps: Tackling Variability in Speaker Verification
Apr 21, 2025The complexity and difficulties of Kurdish speaker detection among its several dialects are investigated in this work. Because of its great phonetic and lexical differences, Kurdish with several dialects including Kurmanji, Sorani, and Hawrami offers special challenges for speaker recognition systems. The main difficulties in building a strong speaker identification system capable of precisely identifying speakers across several dialects are investigated in this work. To raise the accuracy and dependability of these systems, it also suggests solutions like sophisticated machine learning approaches, data augmentation tactics, and the building of thorough dialect-specific corpus. The results show that customized strategies for every dialect together with cross-dialect training greatly enhance recognition performance.
Improved FOX Optimization Algorithm
Apr 13, 2025Optimization algorithms are essential for solving many real-world problems. However, challenges such as premature convergence to local optima and the difficulty of effectively balancing exploration and exploitation often hinder their performance. To address these issues, this paper proposes an improved FOX optimization algorithm, Improved FOX (IFOX). The IFOX algorithm introduces a new adaptive mechanism for balancing exploration and exploitation based on fitness values. It also reduces the number of hyperparameters and simplifies the core equations of the original FOX. To evaluate its effectiveness, IFOX has been tested on classical uni-modal and multi-modal benchmark functions, as well as on benchmark sets from the Congress on Evolutionary Computation (CEC), in addition to two engineering design problems: Pressure Vessel Design and Economic Load Dispatch. The results show that IFOX outperforms existing optimization algorithms, achieving superior results on 51 benchmark functions. These findings underscore the strong potential of IFOX as a competitive and robust optimization algorithm for a wide range of applications.
Multi-objective Cat Swarm Optimization Algorithm based on a Grid System
Feb 22, 2025



This paper presents a multi-objective version of the Cat Swarm Optimization Algorithm called the Grid-based Multi-objective Cat Swarm Optimization Algorithm (GMOCSO). Convergence and diversity preservation are the two main goals pursued by modern multi-objective algorithms to yield robust results. To achieve these goals, we first replace the roulette wheel method of the original CSO algorithm with a greedy method. Then, two key concepts from Pareto Archived Evolution Strategy Algorithm (PAES) are adopted: the grid system and double archive strategy. Several test functions and a real-world scenario called the Pressure vessel design problem are used to evaluate the proposed algorithm's performance. In the experiment, the proposed algorithm is compared with other well-known algorithms using different metrics such as Reversed Generational Distance, Spacing metric, and Spread metric. The optimization results show the robustness of the proposed algorithm, and the results are further confirmed using statistical methods and graphs. Finally, conclusions and future directions were presented..
Artificial Liver Classifier: A New Alternative to Conventional Machine Learning Models
Jan 14, 2025



Supervised machine learning classifiers often encounter challenges related to performance, accuracy, and overfitting. This paper introduces the Artificial Liver Classifier (ALC), a novel supervised learning classifier inspired by the human liver's detoxification function. The ALC is characterized by its simplicity, speed, hyperparameters-free, ability to reduce overfitting, and effectiveness in addressing multi-classification problems through straightforward mathematical operations. To optimize the ALC's parameters, an improved FOX optimization algorithm (IFOX) is employed as the training method. The proposed ALC was evaluated on five benchmark machine learning datasets: Iris Flower, Breast Cancer Wisconsin, Wine, Voice Gender, and MNIST. The results demonstrated competitive performance, with the ALC achieving 100% accuracy on the Iris dataset, surpassing logistic regression, multilayer perceptron, and support vector machine. Similarly, on the Breast Cancer dataset, it achieved 99.12% accuracy, outperforming XGBoost and logistic regression. Across all datasets, the ALC consistently exhibited lower overfitting gaps and loss compared to conventional classifiers. These findings highlight the potential of leveraging biological process simulations to develop efficient machine learning models and open new avenues for innovation in the field.
Foxtsage vs. Adam: Revolution or Evolution in Optimization?
Dec 20, 2024Optimization techniques are pivotal in neural network training, shaping both predictive performance and convergence efficiency. This study introduces Foxtsage, a novel hybrid optimisation approach that integrates the Hybrid FOX-TSA with Stochastic Gradient Descent for training Multi-Layer Perceptron models. The proposed Foxtsage method is benchmarked against the widely adopted Adam optimizer across multiple standard datasets, focusing on key performance metrics such as training loss, accuracy, precision, recall, F1-score, and computational time. Experimental results demonstrate that Foxtsage achieves a 42.03% reduction in loss mean (Foxtsage: 9.508, Adam: 16.402) and a 42.19% improvement in loss standard deviation (Foxtsage: 20.86, Adam: 36.085), reflecting enhanced consistency and robustness. Modest improvements in accuracy mean (0.78%), precision mean (0.91%), recall mean (1.02%), and F1-score mean (0.89%) further underscore its predictive performance. However, these gains are accompanied by an increased computational cost, with a 330.87% rise in time mean (Foxtsage: 39.541 seconds, Adam: 9.177 seconds). By effectively combining the global search capabilities of FOX-TSA with the stability and adaptability of SGD, Foxtsage presents itself as a robust and viable alternative for neural network optimization tasks.
Decoding Drug Discovery: Exploring A-to-Z In silico Methods for Beginners
Dec 15, 2024The drug development process is a critical challenge in the pharmaceutical industry due to its time-consuming nature and the need to discover new drug potentials to address various ailments. The initial step in drug development, drug target identification, often consumes considerable time. While valid, traditional methods such as in vivo and in vitro approaches are limited in their ability to analyze vast amounts of data efficiently, leading to wasteful outcomes. To expedite and streamline drug development, an increasing reliance on computer-aided drug design (CADD) approaches has merged. These sophisticated in silico methods offer a promising avenue for efficiently identifying viable drug candidates, thus providing pharmaceutical firms with significant opportunities to uncover new prospective drug targets. The main goal of this work is to review in silico methods used in the drug development process with a focus on identifying therapeutic targets linked to specific diseases at the genetic or protein level. This article thoroughly discusses A-to-Z in silico techniques, which are essential for identifying the targets of bioactive compounds and their potential therapeutic effects. This review intends to improve drug discovery processes by illuminating the state of these cutting-edge approaches, thereby maximizing the effectiveness and duration of clinical trials for novel drug target investigation.
NER- RoBERTa: Fine-Tuning RoBERTa for Named Entity Recognition (NER) within low-resource languages
Dec 15, 2024



Nowadays, Natural Language Processing (NLP) is an important tool for most people's daily life routines, ranging from understanding speech, translation, named entity recognition (NER), and text categorization, to generative text models such as ChatGPT. Due to the existence of big data and consequently large corpora for widely used languages like English, Spanish, Turkish, Persian, and many more, these applications have been developed accurately. However, the Kurdish language still requires more corpora and large datasets to be included in NLP applications. This is because Kurdish has a rich linguistic structure, varied dialects, and a limited dataset, which poses unique challenges for Kurdish NLP (KNLP) application development. While several studies have been conducted in KNLP for various applications, Kurdish NER (KNER) remains a challenge for many KNLP tasks, including text analysis and classification. In this work, we address this limitation by proposing a methodology for fine-tuning the pre-trained RoBERTa model for KNER. To this end, we first create a Kurdish corpus, followed by designing a modified model architecture and implementing the training procedures. To evaluate the trained model, a set of experiments is conducted to demonstrate the performance of the KNER model using different tokenization methods and trained models. The experimental results show that fine-tuned RoBERTa with the SentencePiece tokenization method substantially improves KNER performance, achieving a 12.8% improvement in F1-score compared to traditional models, and consequently establishes a new benchmark for KNLP.
Central Kurdish Text-to-Speech Synthesis with Novel End-to-End Transformer Training
Aug 06, 2024



Recent advancements in text-to-speech (TTS) models have aimed to streamline the two-stage process into a single-stage training approach. However, many single-stage models still lag behind in audio quality, particularly when handling Kurdish text and speech. There is a critical need to enhance text-to-speech conversion for the Kurdish language, particularly for the Sorani dialect, which has been relatively neglected and is underrepresented in recent text-to-speech advancements. This study introduces an end-to-end TTS model for efficiently generating high-quality Kurdish audio. The proposed method leverages a variational autoencoder (VAE) that is pre-trained for audio waveform reconstruction and is augmented by adversarial training. This involves aligning the prior distribution established by the pre-trained encoder with the posterior distribution of the text encoder within latent variables. Additionally, a stochastic duration predictor is incorporated to imbue synthesized Kurdish speech with diverse rhythms. By aligning latent distributions and integrating the stochastic duration predictor, the proposed method facilitates the real-time generation of natural Kurdish speech audio, offering flexibility in pitches and rhythms. Empirical evaluation via the mean opinion score (MOS) on a custom dataset confirms the superior performance of our approach (MOS of 3.94) compared with that of a one-stage system and other two-staged systems as assessed through a subjective human evaluation.