 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved FOX Optimization Algorithm
Apr 13, 2025Optimization algorithms are essential for solving many real-world problems. However, challenges such as premature convergence to local optima and the difficulty of effectively balancing exploration and exploitation often hinder their performance. To address these issues, this paper proposes an improved FOX optimization algorithm, Improved FOX (IFOX). The IFOX algorithm introduces a new adaptive mechanism for balancing exploration and exploitation based on fitness values. It also reduces the number of hyperparameters and simplifies the core equations of the original FOX. To evaluate its effectiveness, IFOX has been tested on classical uni-modal and multi-modal benchmark functions, as well as on benchmark sets from the Congress on Evolutionary Computation (CEC), in addition to two engineering design problems: Pressure Vessel Design and Economic Load Dispatch. The results show that IFOX outperforms existing optimization algorithms, achieving superior results on 51 benchmark functions. These findings underscore the strong potential of IFOX as a competitive and robust optimization algorithm for a wide range of applications.
Artificial Liver Classifier: A New Alternative to Conventional Machine Learning Models
Jan 14, 2025



Supervised machine learning classifiers often encounter challenges related to performance, accuracy, and overfitting. This paper introduces the Artificial Liver Classifier (ALC), a novel supervised learning classifier inspired by the human liver's detoxification function. The ALC is characterized by its simplicity, speed, hyperparameters-free, ability to reduce overfitting, and effectiveness in addressing multi-classification problems through straightforward mathematical operations. To optimize the ALC's parameters, an improved FOX optimization algorithm (IFOX) is employed as the training method. The proposed ALC was evaluated on five benchmark machine learning datasets: Iris Flower, Breast Cancer Wisconsin, Wine, Voice Gender, and MNIST. The results demonstrated competitive performance, with the ALC achieving 100% accuracy on the Iris dataset, surpassing logistic regression, multilayer perceptron, and support vector machine. Similarly, on the Breast Cancer dataset, it achieved 99.12% accuracy, outperforming XGBoost and logistic regression. Across all datasets, the ALC consistently exhibited lower overfitting gaps and loss compared to conventional classifiers. These findings highlight the potential of leveraging biological process simulations to develop efficient machine learning models and open new avenues for innovation in the field.
FOXANN: A Method for Boosting Neural Network Performance
Jun 29, 2024



Artificial neural networks play a crucial role in machine learning and there is a need to improve their performance. This paper presents FOXANN, a novel classification model that combines the recently developed Fox optimizer with ANN to solve ML problems. Fox optimizer replaces the backpropagation algorithm in ANN; optimizes synaptic weights; and achieves high classification accuracy with a minimum loss, improved model generalization, and interpretability. The performance of FOXANN is evaluated on three standard datasets: Iris Flower, Breast Cancer Wisconsin, and Wine. The results presented in this paper are derived from 100 epochs using 10-fold cross-validation, ensuring that all dataset samples are involved in both the training and validation stages. Moreover, the results show that FOXANN outperforms traditional ANN and logistic regression methods as well as other models proposed in the literature such as ABC-ANN, ABC-MNN, CROANN, and PSO-DNN, achieving a higher accuracy of 0.9969 and a lower validation loss of 0.0028. These results demonstrate that FOXANN is more effective than traditional methods and other proposed models across standard datasets. Thus, FOXANN effectively addresses the challenges in ML algorithms and improves classification performance.
Q-FOX Learning: Breaking Tradition in Reinforcement Learning
Feb 26, 2024Reinforcement learning (RL) is a subset of artificial intelligence (AI) where agents learn the best action by interacting with the environment, making it suitable for tasks that do not require labeled data or direct supervision. Hyperparameters (HP) tuning refers to choosing the best parameter that leads to optimal solutions in RL algorithms. Manual or random tuning of the HP may be a crucial process because variations in this parameter lead to changes in the overall learning aspects and different rewards. In this paper, a novel and automatic HP-tuning method called Q-FOX is proposed. This uses both the FOX optimizer, a new optimization method inspired by nature that mimics red foxes' hunting behavior, and the commonly used, easy-to-implement RL Q-learning algorithm to solve the problem of HP tuning. Moreover, a new objective function is proposed which prioritizes the reward over the mean squared error (MSE) and learning time (steps). Q-FOX has been evaluated on two OpenAI Gym environment control tasks: Cart Pole and Frozen Lake. It exposed greater cumulative rewards than HP tuning with other optimizers, such as PSO, GA, Bee, or randomly selected HP. The cumulative reward for the Cart Pole task was 32.08, and for the Frozen Lake task was 0.95. Despite the robustness of Q-FOX, it has limitations. It cannot be used directly in real-word problems before choosing the HP in a simulation environment because its processes work iteratively, making it time-consuming. The results indicate that Q-FOX has played an essential role in HP tuning for RL algorithms to effectively solve different control tasks.
BCDDO: Binary Child Drawing Development Optimization
Aug 03, 2023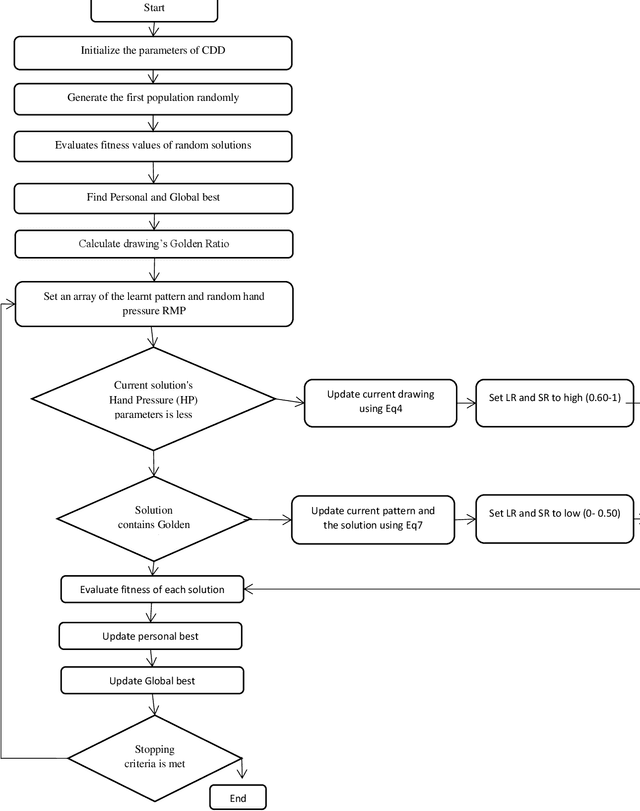



A lately created metaheuristic algorithm called Child Drawing Development Optimization (CDDO) has proven to be effective in a number of benchmark tests. A Binary Child Drawing Development Optimization (BCDDO) is suggested for choosing the wrapper features in this study. To achieve the best classification accuracy, a subset of crucial features is selected using the suggested BCDDO. The proposed feature selection technique's efficiency and effectiveness are assessed using the Harris Hawk, Grey Wolf, Salp, and Whale optimization algorithms. The suggested approach has significantly outperformed the previously discussed techniques in the area of feature selection to increase classification accuracy. Moderate COVID, breast cancer, and big COVID are the three datasets utilized in this study. The classification accuracy for each of the three datasets was (98.75, 98.83%, and 99.36) accordingly.