 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Forgery Detection for Surveillance Cameras: A Review
May 04, 2025



The widespread availability of video recording through smartphones and digital devices has made video-based evidence more accessible than ever. Surveillance footage plays a crucial role in security, law enforcement, and judicial processes. However, with the rise of advanced video editing tools, tampering with digital recordings has become increasingly easy, raising concerns about their authenticity. Ensuring the integrity of surveillance videos is essential, as manipulated footage can lead to misinformation and undermine judicial decisions. This paper provides a comprehensive review of existing forensic techniques used to detect video forgery, focusing on their effectiveness in verifying the authenticity of surveillance recordings. Various methods, including compression-based analysis, frame duplication detection, and machine learning-based approaches, are explored. The findings highlight the growing necessity for more robust forensic techniques to counteract evolving forgery methods. Strengthening video forensic capabilities will ensure that surveillance recordings remain credible and admissible as legal evidence.
From Dialect Gaps to Identity Maps: Tackling Variability in Speaker Verification
Apr 21, 2025The complexity and difficulties of Kurdish speaker detection among its several dialects are investigated in this work. Because of its great phonetic and lexical differences, Kurdish with several dialects including Kurmanji, Sorani, and Hawrami offers special challenges for speaker recognition systems. The main difficulties in building a strong speaker identification system capable of precisely identifying speakers across several dialects are investigated in this work. To raise the accuracy and dependability of these systems, it also suggests solutions like sophisticated machine learning approaches, data augmentation tactics, and the building of thorough dialect-specific corpus. The results show that customized strategies for every dialect together with cross-dialect training greatly enhance recognition performance.
Multi-objective Cat Swarm Optimization Algorithm based on a Grid System
Feb 22, 2025



This paper presents a multi-objective version of the Cat Swarm Optimization Algorithm called the Grid-based Multi-objective Cat Swarm Optimization Algorithm (GMOCSO). Convergence and diversity preservation are the two main goals pursued by modern multi-objective algorithms to yield robust results. To achieve these goals, we first replace the roulette wheel method of the original CSO algorithm with a greedy method. Then, two key concepts from Pareto Archived Evolution Strategy Algorithm (PAES) are adopted: the grid system and double archive strategy. Several test functions and a real-world scenario called the Pressure vessel design problem are used to evaluate the proposed algorithm's performance. In the experiment, the proposed algorithm is compared with other well-known algorithms using different metrics such as Reversed Generational Distance, Spacing metric, and Spread metric. The optimization results show the robustness of the proposed algorithm, and the results are further confirmed using statistical methods and graphs. Finally, conclusions and future directions were presented..
Decoding Drug Discovery: Exploring A-to-Z In silico Methods for Beginners
Dec 15, 2024The drug development process is a critical challenge in the pharmaceutical industry due to its time-consuming nature and the need to discover new drug potentials to address various ailments. The initial step in drug development, drug target identification, often consumes considerable time. While valid, traditional methods such as in vivo and in vitro approaches are limited in their ability to analyze vast amounts of data efficiently, leading to wasteful outcomes. To expedite and streamline drug development, an increasing reliance on computer-aided drug design (CADD) approaches has merged. These sophisticated in silico methods offer a promising avenue for efficiently identifying viable drug candidates, thus providing pharmaceutical firms with significant opportunities to uncover new prospective drug targets. The main goal of this work is to review in silico methods used in the drug development process with a focus on identifying therapeutic targets linked to specific diseases at the genetic or protein level. This article thoroughly discusses A-to-Z in silico techniques, which are essential for identifying the targets of bioactive compounds and their potential therapeutic effects. This review intends to improve drug discovery processes by illuminating the state of these cutting-edge approaches, thereby maximizing the effectiveness and duration of clinical trials for novel drug target investigation.
From A-to-Z Review of Clustering Validation Indices
Jul 18, 2024



Data clustering involves identifying latent similarities within a dataset and organizing them into clusters or groups. The outcomes of various clustering algorithms differ as they are susceptible to the intrinsic characteristics of the original dataset, including noise and dimensionality. The effectiveness of such clustering procedures directly impacts the homogeneity of clusters, underscoring the significance of evaluating algorithmic outcomes. Consequently, the assessment of clustering quality presents a significant and complex endeavor. A pivotal aspect affecting clustering validation is the cluster validity metric, which aids in determining the optimal number of clusters. The main goal of this study is to comprehensively review and explain the mathematical operation of internal and external cluster validity indices, but not all, to categorize these indices and to brainstorm suggestions for future advancement of clustering validation research. In addition, we review and evaluate the performance of internal and external clustering validation indices on the most common clustering algorithms, such as the evolutionary clustering algorithm star (ECA*). Finally, we suggest a classification framework for examining the functionality of both internal and external clustering validation measures regarding their ideal values, user-friendliness, responsiveness to input data, and appropriateness across various fields. This classification aids researchers in selecting the appropriate clustering validation measure to suit their specific requirements.
Ontology Learning Using Formal Concept Analysis and WordNet
Nov 10, 2023Manual ontology construction takes time, resources, and domain specialists. Supporting a component of this process for automation or semi-automation would be good. This project and dissertation provide a Formal Concept Analysis and WordNet framework for learning concept hierarchies from free texts. The process has steps. First, the document is Part-Of-Speech labeled, then parsed to produce sentence parse trees. Verb/noun dependencies are derived from parse trees next. After lemmatizing, pruning, and filtering the word pairings, the formal context is created. The formal context may contain some erroneous and uninteresting pairs because the parser output may be erroneous, not all derived pairs are interesting, and it may be large due to constructing it from a large free text corpus. Deriving lattice from the formal context may take longer, depending on the size and complexity of the data. Thus, decreasing formal context may eliminate erroneous and uninteresting pairs and speed up idea lattice derivation. WordNet-based and Frequency-based approaches are tested. Finally, we compute formal idea lattice and create a classical concept hierarchy. The reduced concept lattice is compared to the original to evaluate the outcomes. Despite several system constraints and component discrepancies that may prevent logical conclusion, the following data imply idea hierarchies in this project and dissertation are promising. First, the reduced idea lattice and original concept have commonalities. Second, alternative language or statistical methods can reduce formal context size. Finally, WordNet-based and Frequency-based approaches reduce formal context differently, and the order of applying them is examined to reduce context efficiently.
An Improved Deep Convolutional Neural Network by Using Hybrid Optimization Algorithms to Detect and Classify Brain Tumor Using Augmented MRI Images
Jun 08, 2022Automated brain tumor detection is becoming a highly considerable medical diagnosis research. In recent medical diagnoses, detection and classification are highly considered to employ machine learning and deep learning techniques. Nevertheless, the accuracy and performance of current models need to be improved for suitable treatments. In this paper, an improvement in deep convolutional learning is ensured by adopting enhanced optimization algorithms, Thus, Deep Convolutional Neural Network (DCNN) based on improved Harris Hawks Optimization (HHO), called G-HHO has been considered. This hybridization features Grey Wolf Optimization (GWO) and HHO to give better results, limiting the convergence rate and enhancing performance. Moreover, Otsu thresholding is adopted to segment the tumor portion that emphasizes brain tumor detection. Experimental studies are conducted to validate the performance of the suggested method on a total number of 2073 augmented MRI images. The technique's performance was ensured by comparing it with the nine existing algorithms on huge augmented MRI images in terms of accuracy, precision, recall, f-measure, execution time, and memory usage. The performance comparison shows that the DCNN-G-HHO is much more successful than existing methods, especially on a scoring accuracy of 97%. Additionally, the statistical performance analysis indicates that the suggested approach is faster and utilizes less memory at identifying and categorizing brain tumor cancers on the MR images. The implementation of this validation is conducted on the Python platform. The relevant codes for the proposed approach are available at: https://github.com/bryarahassan/DCNN-G-HHO.
Current Studies and Applications of Shuffled Frog Leaping Algorithm: A Review
Jan 27, 2022Shuffled Frog Leaping Algorithm (SFLA) is one of the most widespread algorithms. It was developed by Eusuff and Lansey in 2006. SFLA is a population-based metaheuristic algorithm that combines the benefits of memetics with particle swarm optimization. It has been used in various areas, especially in engineering problems due to its implementation easiness and limited variables. Many improvements have been made to the algorithm to alleviate its drawbacks, whether they were achieved through modifications or hybridizations with other well-known algorithms. This paper reviews the most relevant works on this algorithm. An overview of the SFLA is first conducted, followed by the algorithm's most recent modifications and hybridizations. Next, recent applications of the algorithm are discussed. Then, an operational framework of SLFA and its variants is proposed to analyze their uses on different cohorts of applications. Finally, future improvements to the algorithm are suggested. The main incentive to conduct this survey to provide useful information about the SFLA to researchers interested in working on the algorithm's enhancement or application
* 28 pages
A Novel Cluster Detection of COVID-19 Patients and Medical Disease Conditions Using Improved Evolutionary Clustering Algorithm Star
Sep 20, 2021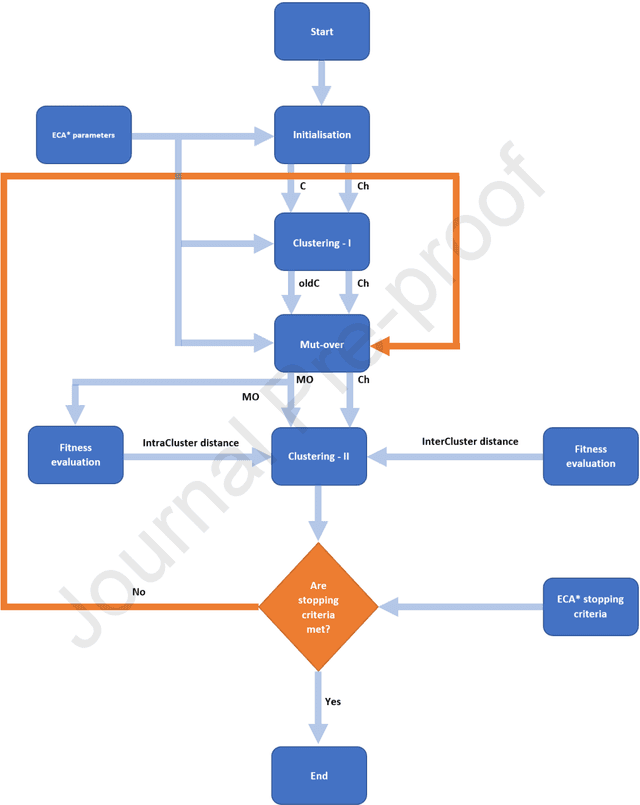
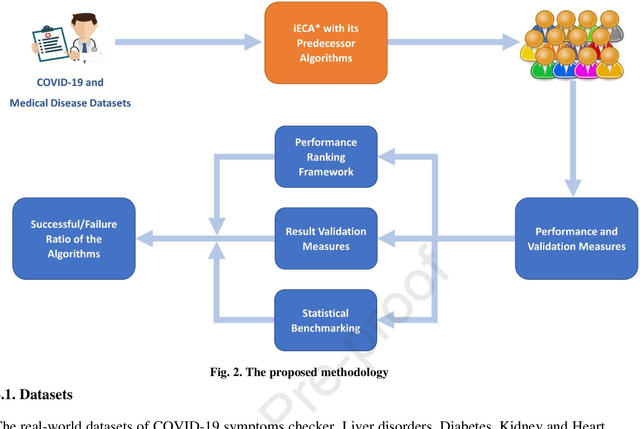
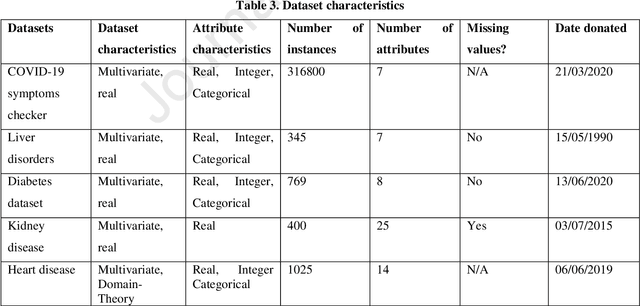
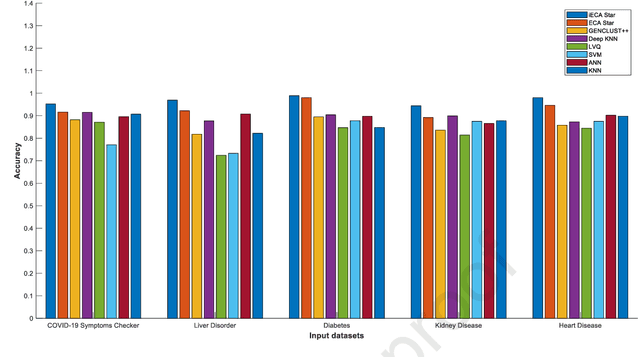
With the increasing number of samples, the manual clustering of COVID-19 and medical disease data samples becomes time-consuming and requires highly skilled labour. Recently, several algorithms have been used for clustering medical datasets deterministically; however, these definitions have not been effective in grouping and analysing medical diseases. The use of evolutionary clustering algorithms may help to effectively cluster these diseases. On this presumption, we improved the current evolutionary clustering algorithm star (ECA*), called iECA*, in three manners: (i) utilising the elbow method to find the correct number of clusters; (ii) cleaning and processing data as part of iECA* to apply it to multivariate and domain-theory datasets; (iii) using iECA* for real-world applications in clustering COVID-19 and medical disease datasets. Experiments were conducted to examine the performance of iECA* against state-of-the-art algorithms using performance and validation measures (validation measures, statistical benchmarking, and performance ranking framework). The results demonstrate three primary findings. First, iECA* was more effective than other algorithms in grouping the chosen medical disease datasets according to the cluster validation criteria. Second, iECA* exhibited the lower execution time and memory consumption for clustering all the datasets, compared to the current clustering methods analysed. Third, an operational framework was proposed to rate the effectiveness of iECA* against other algorithms in the datasets analysed, and the results indicated that iECA* exhibited the best performance in clustering all medical datasets. Further research is required on real-world multi-dimensional data containing complex knowledge fields for experimental verification of iECA* compared to evolutionary algorithms.
Artificial Intelligence Algorithms for Natural Language Processing and the Semantic Web Ontology Learning
Aug 31, 2021Evolutionary clustering algorithms have considered as the most popular and widely used evolutionary algorithms for minimising optimisation and practical problems in nearly all fields. In this thesis, a new evolutionary clustering algorithm star (ECA*) is proposed. Additionally, a number of experiments were conducted to evaluate ECA* against five state-of-the-art approaches. For this, 32 heterogeneous and multi-featured datasets were used to examine their performance using internal and external clustering measures, and to measure the sensitivity of their performance towards dataset features in the form of operational framework. The results indicate that ECA* overcomes its competitive techniques in terms of the ability to find the right clusters. Based on its superior performance, exploiting and adapting ECA* on the ontology learning had a vital possibility. In the process of deriving concept hierarchies from corpora, generating formal context may lead to a time-consuming process. Therefore, formal context size reduction results in removing uninterested and erroneous pairs, taking less time to extract the concept lattice and concept hierarchies accordingly. In this premise, this work aims to propose a framework to reduce the ambiguity of the formal context of the existing framework using an adaptive version of ECA*. In turn, an experiment was conducted by applying 385 sample corpora from Wikipedia on the two frameworks to examine the reduction of formal context size, which leads to yield concept lattice and concept hierarchy. The resulting lattice of formal context was evaluated to the original one using concept lattice-invariants. Accordingly, the homomorphic between the two lattices preserves the quality of resulting concept hierarchies by 89% in contrast to the basic ones, and the reduced concept lattice inherits the structural relation of the original one.