 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comprehensive review and evaluation on text predictive and entertainment systems
Jan 08, 2022One of the most important ways to experience communication and interact with the systems is by handling the prediction of the most likely words to happen after typing letters or words. It is helpful for people with disabilities due to disabling people who could type or enter texts at a limited slow speed. Also, it is beneficial for people with dyslexia and those people who are not well with spells of words. Though, an input technology, for instance, the next word suggestion facilitates the typing process in smartphones as an example. This means that when a user types a word, then the system suggests the next words to be chosen in which the necessary word by the user. Besides, it can be used in entertainment as a gam, for example, to determine a target word and reach it or tackle it within 10 attempts of prediction. Generally, the systems depend on a text corpus, which was provided in the system to conduct the prediction. Writing every single word is time-consuming, therefore, it is vitally important to decrease time consumption by reducing efforts to input texts in the systems by offering most probable words for the user to select, this could be done via next word prediction systems. There are several techniques can be found in literature, which is utilized to conduct a variety of next word prediction systems by using different approaches. In this paper, a survey of miscellaneous techniques towards the next word prediction systems will be addressed. Besides, the evaluation of the prediction systems will be discussed. Then, a modal technique will be determined to be utilized for the next word prediction system from the perspective of easiness of implementation and obtaining a good result.
* 42 pages
A Novel Cluster Detection of COVID-19 Patients and Medical Disease Conditions Using Improved Evolutionary Clustering Algorithm Star
Sep 20, 2021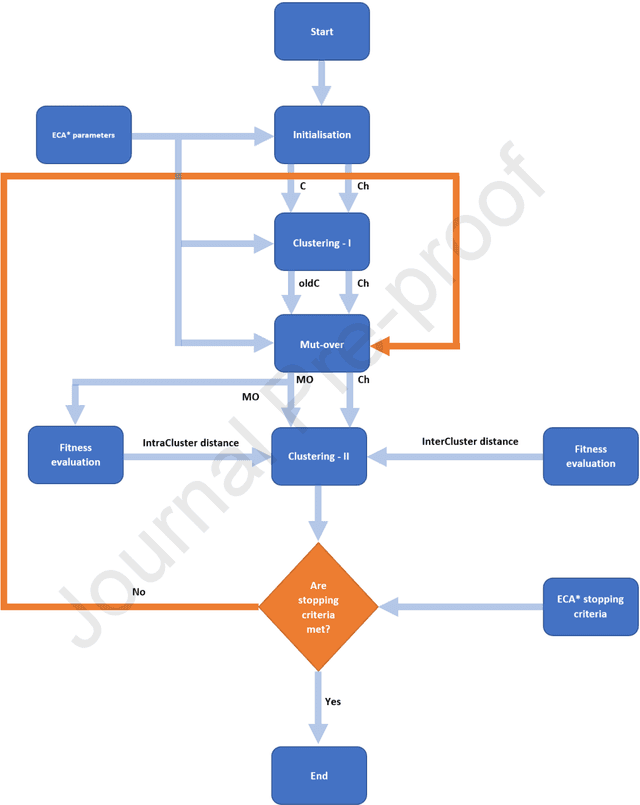
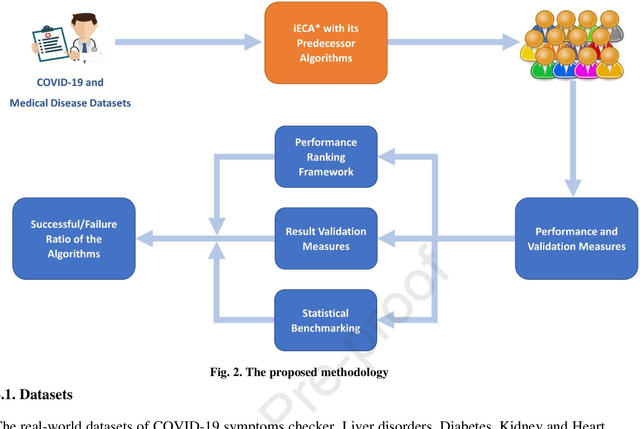
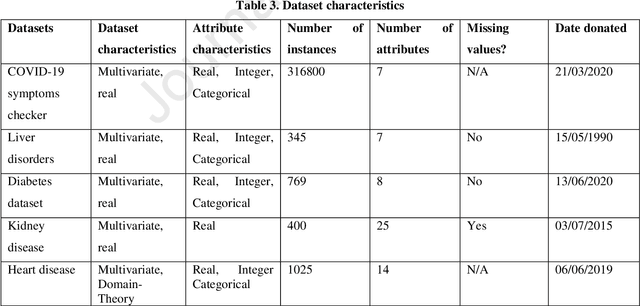
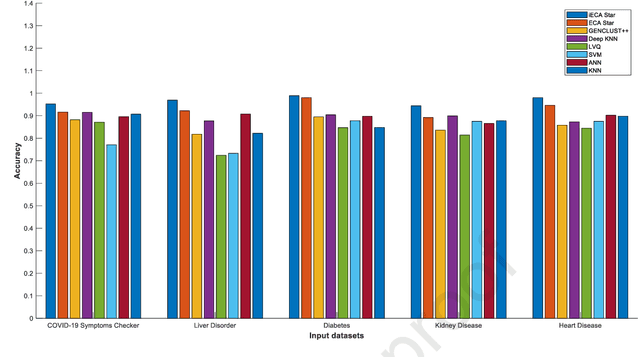
With the increasing number of samples, the manual clustering of COVID-19 and medical disease data samples becomes time-consuming and requires highly skilled labour. Recently, several algorithms have been used for clustering medical datasets deterministically; however, these definitions have not been effective in grouping and analysing medical diseases. The use of evolutionary clustering algorithms may help to effectively cluster these diseases. On this presumption, we improved the current evolutionary clustering algorithm star (ECA*), called iECA*, in three manners: (i) utilising the elbow method to find the correct number of clusters; (ii) cleaning and processing data as part of iECA* to apply it to multivariate and domain-theory datasets; (iii) using iECA* for real-world applications in clustering COVID-19 and medical disease datasets. Experiments were conducted to examine the performance of iECA* against state-of-the-art algorithms using performance and validation measures (validation measures, statistical benchmarking, and performance ranking framework). The results demonstrate three primary findings. First, iECA* was more effective than other algorithms in grouping the chosen medical disease datasets according to the cluster validation criteria. Second, iECA* exhibited the lower execution time and memory consumption for clustering all the datasets, compared to the current clustering methods analysed. Third, an operational framework was proposed to rate the effectiveness of iECA* against other algorithms in the datasets analysed, and the results indicated that iECA* exhibited the best performance in clustering all medical datasets. Further research is required on real-world multi-dimensional data containing complex knowledge fields for experimental verification of iECA* compared to evolutionary algorithms.
Next word prediction based on the N-gram model for Kurdish Sorani and Kurmanji
Jul 27, 2020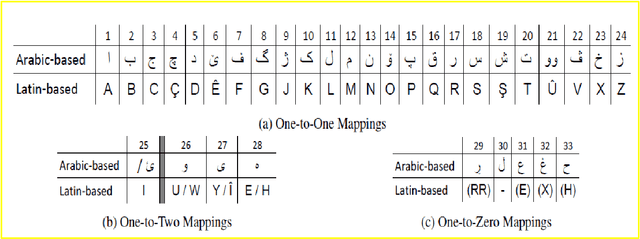

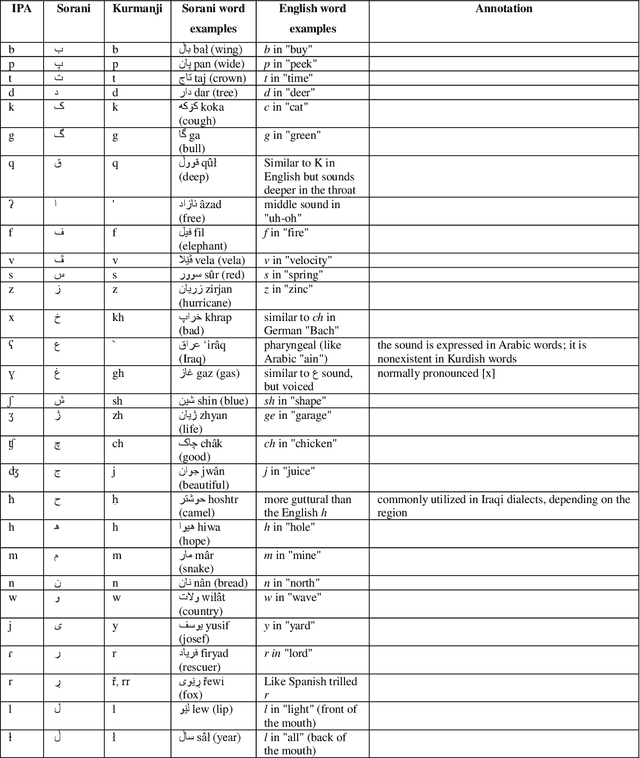
Next word prediction is an input technology that simplifies the process of typing by suggesting the next word to a user to select, as typing in a conversation consumes time. A few previous studies have focused on the Kurdish language, including the use of next word prediction. However, the lack of a Kurdish text corpus presents a challenge. Moreover, the lack of a sufficient number of N-grams for the Kurdish language, for instance, five grams, is the reason for the rare use of next Kurdish word prediction. Furthermore, the improper display of several Kurdish letters in the Rstudio software is another problem. This paper provides a Kurdish corpus, creates five, and presents a unique research work on next word prediction for Kurdish Sorani and Kurmanji. The N-gram model has been used for next word prediction to reduce the amount of time while typing in the Kurdish language. In addition, little work has been conducted on next Kurdish word prediction; thus, the N-gram model is utilized to suggest text accurately. To do so, R programming and RStudio are used to build the application. The model is 96.3% accurate.
* 37 pages