 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-of-Constraints Model Predictive Control for Reactive Multi-agent Task and Motion Planning
Mar 19, 2026Sequences of interdependent geometric constraints are central to many multi-agent Task and Motion Planning (TAMP) problems. However, existing methods for handling such constraint sequences struggle with partially ordered tasks and dynamic agent assignments. They typically assume static assignments and cannot adapt when disturbances alter task allocations. To overcome these limitations, we introduce Graph-of-Constraints Model Predictive Control (GoC-MPC), a generalized sequence-of-constraints framework integrated with MPC. GoC-MPC naturally supports partially ordered tasks, dynamic agent coordination, and disturbance recovery. By defining constraints over tracked 3D keypoints, our method robustly solves diverse multi-agent manipulation tasks-coordinating agents and adapting online from visual observations alone, without relying on training data or environment models. Experiments demonstrate that GoC-MPC achieves higher success rates, significantly faster TAMP computation, and shorter overall paths compared to recent baselines, establishing it as an efficient and robust solution for multi-agent manipulation under real-world disturbances. Our supplementary video and code can be found at https://sites.google.com/view/goc-mpc/home .
A Framework for Learning Scoring Rules in Autonomous Driving Planning Systems
Feb 17, 2025



In autonomous driving systems, motion planning is commonly implemented as a two-stage process: first, a trajectory proposer generates multiple candidate trajectories, then a scoring mechanism selects the most suitable trajectory for execution. For this critical selection stage, rule-based scoring mechanisms are particularly appealing as they can explicitly encode driving preferences, safety constraints, and traffic regulations in a formalized, human-understandable format. However, manually crafting these scoring rules presents significant challenges: the rules often contain complex interdependencies, require careful parameter tuning, and may not fully capture the nuances present in real-world driving data. This work introduces FLoRA, a novel framework that bridges this gap by learning interpretable scoring rules represented in temporal logic. Our method features a learnable logic structure that captures nuanced relationships across diverse driving scenarios, optimizing both rules and parameters directly from real-world driving demonstrations collected in NuPlan. Our approach effectively learns to evaluate driving behavior even though the training data only contains positive examples (successful driving demonstrations). Evaluations in closed-loop planning simulations demonstrate that our learned scoring rules outperform existing techniques, including expert-designed rules and neural network scoring models, while maintaining interpretability. This work introduces a data-driven approach to enhance the scoring mechanism in autonomous driving systems, designed as a plug-in module to seamlessly integrate with various trajectory proposers. Our video and code are available on xiong.zikang.me/FLoRA.
Scaling Safe Multi-Agent Control for Signal Temporal Logic Specifications
Jan 10, 2025



Existing methods for safe multi-agent control using logic specifications like Signal Temporal Logic (STL) often face scalability issues. This is because they rely either on single-agent perspectives or on Mixed Integer Linear Programming (MILP)-based planners, which are complex to optimize. These methods have proven to be computationally expensive and inefficient when dealing with a large number of agents. To address these limitations, we present a new scalable approach to multi-agent control in this setting. Our method treats the relationships between agents using a graph structure rather than in terms of a single-agent perspective. Moreover, it combines a multi-agent collision avoidance controller with a Graph Neural Network (GNN) based planner, models the system in a decentralized fashion, and trains on STL-based objectives to generate safe and efficient plans for multiple agents, thereby optimizing the satisfaction of complex temporal specifications while also facilitating multi-agent collision avoidance. Our experiments show that our approach significantly outperforms existing methods that use a state-of-the-art MILP-based planner in terms of scalability and performance. The project website is https://jeappen.com/mastl-gcbf-website/ and the code is at https://github.com/jeappen/mastl-gcbf .
SELP: Generating Safe and Efficient Task Plans for Robot Agents with Large Language Models
Sep 28, 2024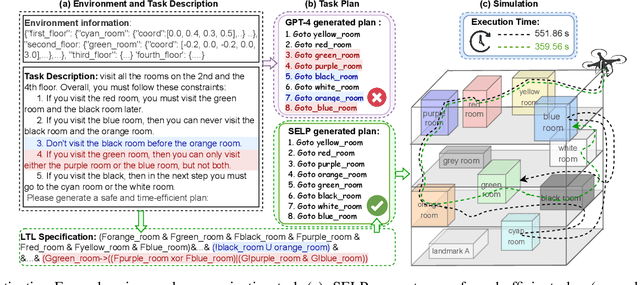
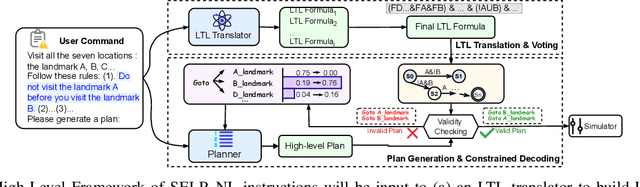
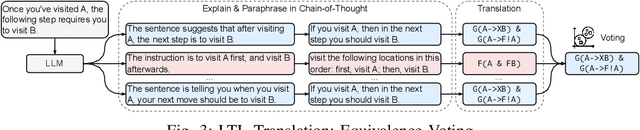

Despite significant advancements in large language models (LLMs) that enhance robot agents' understanding and execution of natural language (NL) commands, ensuring the agents adhere to user-specified constraints remains challenging, particularly for complex commands and long-horizon tasks. To address this challenge, we present three key insights, equivalence voting, constrained decoding, and domain-specific fine-tuning, which significantly enhance LLM planners' capability in handling complex tasks. Equivalence voting ensures consistency by generating and sampling multiple Linear Temporal Logic (LTL) formulas from NL commands, grouping equivalent LTL formulas, and selecting the majority group of formulas as the final LTL formula. Constrained decoding then uses the generated LTL formula to enforce the autoregressive inference of plans, ensuring the generated plans conform to the LTL. Domain-specific fine-tuning customizes LLMs to produce safe and efficient plans within specific task domains. Our approach, Safe Efficient LLM Planner (SELP), combines these insights to create LLM planners to generate plans adhering to user commands with high confidence. We demonstrate the effectiveness and generalizability of SELP across different robot agents and tasks, including drone navigation and robot manipulation. For drone navigation tasks, SELP outperforms state-of-the-art planners by 10.8% in safety rate (i.e., finishing tasks conforming to NL commands) and by 19.8% in plan efficiency. For robot manipulation tasks, SELP achieves 20.4% improvement in safety rate. Our datasets for evaluating NL-to-LTL and robot task planning will be released in github.com/lt-asset/selp.
Manipulating Neural Path Planners via Slight Perturbations
Mar 27, 2024



Data-driven neural path planners are attracting increasing interest in the robotics community. However, their neural network components typically come as black boxes, obscuring their underlying decision-making processes. Their black-box nature exposes them to the risk of being compromised via the insertion of hidden malicious behaviors. For example, an attacker may hide behaviors that, when triggered, hijack a delivery robot by guiding it to a specific (albeit wrong) destination, trapping it in a predefined region, or inducing unnecessary energy expenditure by causing the robot to repeatedly circle a region. In this paper, we propose a novel approach to specify and inject a range of hidden malicious behaviors, known as backdoors, into neural path planners. Our approach provides a concise but flexible way to define these behaviors, and we show that hidden behaviors can be triggered by slight perturbations (e.g., inserting a tiny unnoticeable object), that can nonetheless significantly compromise their integrity. We also discuss potential techniques to identify these backdoors aimed at alleviating such risks. We demonstrate our approach on both sampling-based and search-based neural path planners.
Co-learning Planning and Control Policies Using Differentiable Formal Task Constraints
Mar 02, 2023This paper presents a hierarchical reinforcement learning algorithm constrained by differentiable signal temporal logic. Previous work on logic-constrained reinforcement learning consider encoding these constraints with a reward function, constraining policy updates with a sample-based policy gradient. However, such techniques oftentimes tend to be inefficient because of the significant number of samples required to obtain accurate policy gradients. In this paper, instead of implicitly constraining policy search with sample-based policy gradients, we directly constrain policy search by backpropagating through formal constraints, enabling training hierarchical policies with substantially fewer training samples. The use of hierarchical policies is recognized as a crucial component of reinforcement learning with task constraints. We show that we can stably constrain policy updates, thus enabling different levels of the policy to be learned simultaneously, yielding superior performance compared with training them separately. Experiment results on several simulated high-dimensional robot dynamics and a real-world differential drive robot (TurtleBot3) demonstrate the effectiveness of our approach on five different types of task constraints. Demo videos, code, and models can be found at our project website: https://sites.google.com/view/dscrl
DistSPECTRL: Distributing Specifications in Multi-Agent Reinforcement Learning Systems
Jun 28, 2022
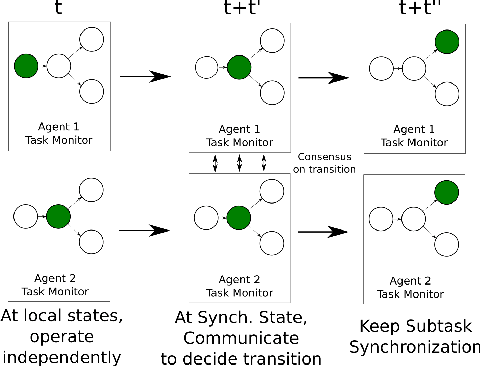
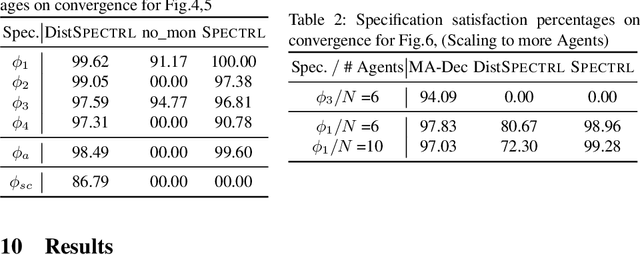
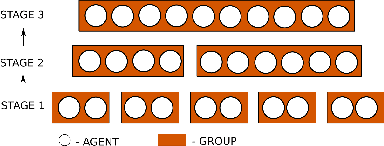
While notable progress has been made in specifying and learning objectives for general cyber-physical systems, applying these methods to distributed multi-agent systems still pose significant challenges. Among these are the need to (a) craft specification primitives that allow expression and interplay of both local and global objectives, (b) tame explosion in the state and action spaces to enable effective learning, and (c) minimize coordination frequency and the set of engaged participants for global objectives. To address these challenges, we propose a novel specification framework that allows natural composition of local and global objectives used to guide training of a multi-agent system. Our technique enables learning expressive policies that allow agents to operate in a coordination-free manner for local objectives, while using a decentralized communication protocol for enforcing global ones. Experimental results support our claim that sophisticated multi-agent distributed planning problems can be effectively realized using specification-guided learning.
Defending Observation Attacks in Deep Reinforcement Learning via Detection and Denoising
Jun 14, 2022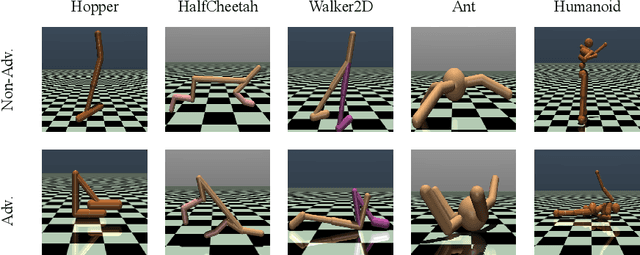
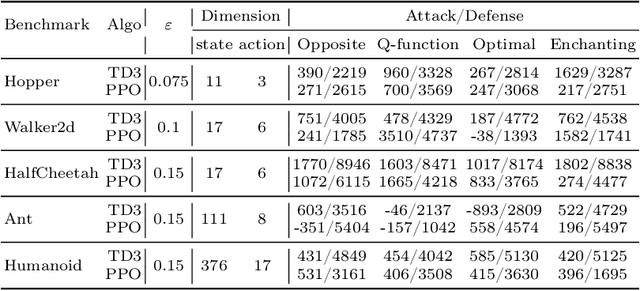
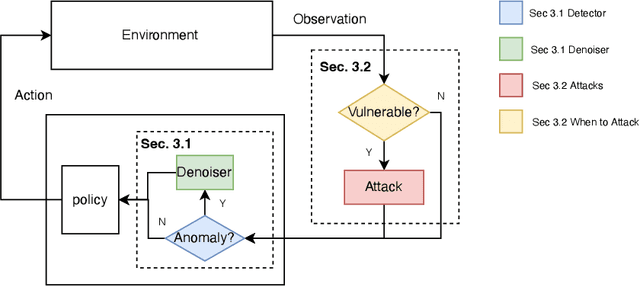
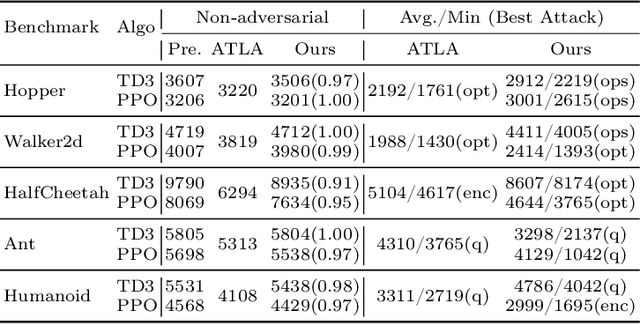
Neural network policies trained using Deep Reinforcement Learning (DRL) are well-known to be susceptible to adversarial attacks. In this paper, we consider attacks manifesting as perturbations in the observation space managed by the external environment. These attacks have been shown to downgrade policy performance significantly. We focus our attention on well-trained deterministic and stochastic neural network policies in the context of continuous control benchmarks subject to four well-studied observation space adversarial attacks. To defend against these attacks, we propose a novel defense strategy using a detect-and-denoise schema. Unlike previous adversarial training approaches that sample data in adversarial scenarios, our solution does not require sampling data in an environment under attack, thereby greatly reducing risk during training. Detailed experimental results show that our technique is comparable with state-of-the-art adversarial training approaches.
Model-free Neural Lyapunov Control for Safe Robot Navigation
Mar 02, 2022
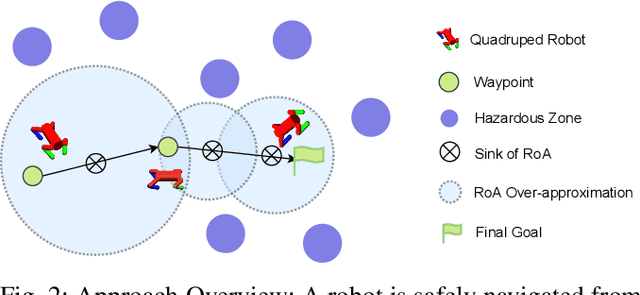
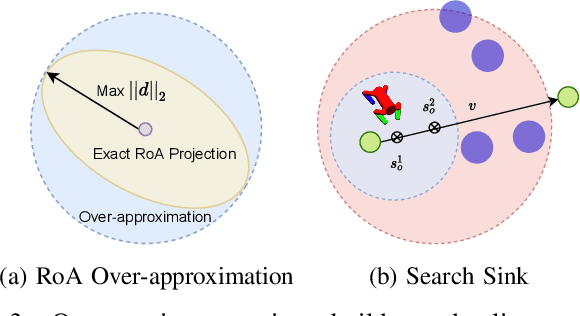
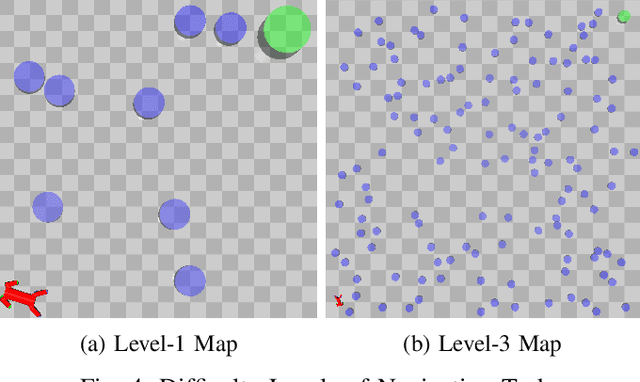
Model-free Deep Reinforcement Learning (DRL) controllers have demonstrated promising results on various challenging non-linear control tasks. While a model-free DRL algorithm can solve unknown dynamics and high-dimensional problems, it lacks safety assurance. Although safety constraints can be encoded as part of a reward function, there still exists a large gap between an RL controller trained with this modified reward and a safe controller. In contrast, instead of implicitly encoding safety constraints with rewards, we explicitly co-learn a Twin Neural Lyapunov Function (TNLF) with the control policy in the DRL training loop and use the learned TNLF to build a runtime monitor. Combined with the path generated from a planner, the monitor chooses appropriate waypoints that guide the learned controller to provide collision-free control trajectories. Our approach inherits the scalability advantages from DRL while enhancing safety guarantees. Our experimental evaluation demonstrates the effectiveness of our approach compared to DRL with augmented rewards and constrained DRL methods over a range of high-dimensional safety-sensitive navigation tasks.
Scalable Synthesis of Verified Controllers in Deep Reinforcement Learning
Apr 20, 2021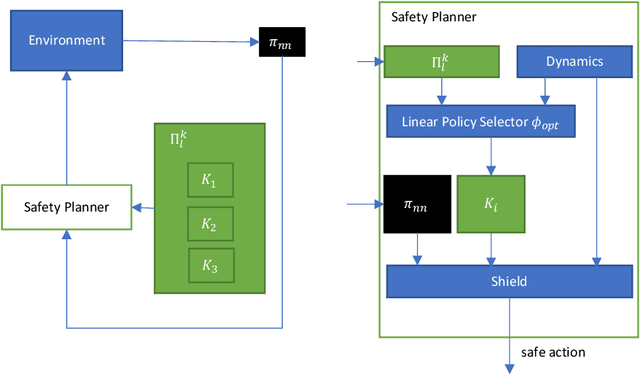


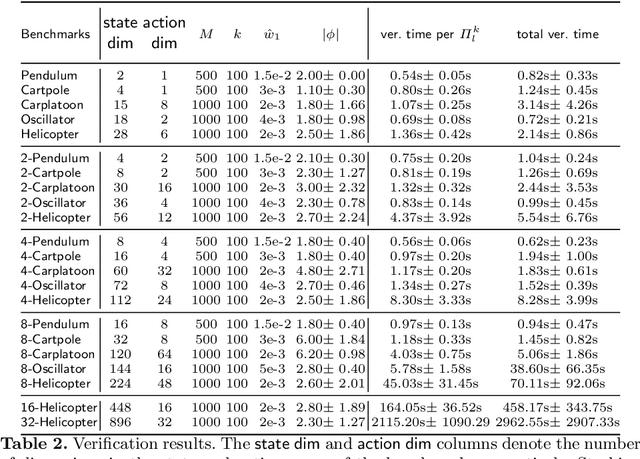
There has been significant recent interest in devising verification techniques for learning-enabled controllers (LECs) that manage safety-critical systems. Given the opacity and lack of interpretability of the neural policies that govern the behavior of such controllers, many existing approaches enforce safety properties through the use of shields, a dynamic monitoring and repair mechanism that ensures a LEC does not emit actions that would violate desired safety conditions. These methods, however, have shown to have significant scalability limitations because verification costs grow as problem dimensionality and objective complexity increase. In this paper, we propose a new automated verification pipeline capable of synthesizing high-quality safety shields even when the problem domain involves hundreds of dimensions, or when the desired objective involves stochastic perturbations, liveness considerations, and other complex non-functional properties. Our key insight involves separating safety verification from neural controller, using pre-computed verified safety shields to constrain neural controller training which does not only focus on safety. Experimental results over a range of realistic high-dimensional deep RL benchmarks demonstrate the effectiveness of our approach.