 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Safe Multi-Agent Control for Signal Temporal Logic Specifications
Jan 10, 2025



Existing methods for safe multi-agent control using logic specifications like Signal Temporal Logic (STL) often face scalability issues. This is because they rely either on single-agent perspectives or on Mixed Integer Linear Programming (MILP)-based planners, which are complex to optimize. These methods have proven to be computationally expensive and inefficient when dealing with a large number of agents. To address these limitations, we present a new scalable approach to multi-agent control in this setting. Our method treats the relationships between agents using a graph structure rather than in terms of a single-agent perspective. Moreover, it combines a multi-agent collision avoidance controller with a Graph Neural Network (GNN) based planner, models the system in a decentralized fashion, and trains on STL-based objectives to generate safe and efficient plans for multiple agents, thereby optimizing the satisfaction of complex temporal specifications while also facilitating multi-agent collision avoidance. Our experiments show that our approach significantly outperforms existing methods that use a state-of-the-art MILP-based planner in terms of scalability and performance. The project website is https://jeappen.com/mastl-gcbf-website/ and the code is at https://github.com/jeappen/mastl-gcbf .
Co-learning Planning and Control Policies Using Differentiable Formal Task Constraints
Mar 02, 2023This paper presents a hierarchical reinforcement learning algorithm constrained by differentiable signal temporal logic. Previous work on logic-constrained reinforcement learning consider encoding these constraints with a reward function, constraining policy updates with a sample-based policy gradient. However, such techniques oftentimes tend to be inefficient because of the significant number of samples required to obtain accurate policy gradients. In this paper, instead of implicitly constraining policy search with sample-based policy gradients, we directly constrain policy search by backpropagating through formal constraints, enabling training hierarchical policies with substantially fewer training samples. The use of hierarchical policies is recognized as a crucial component of reinforcement learning with task constraints. We show that we can stably constrain policy updates, thus enabling different levels of the policy to be learned simultaneously, yielding superior performance compared with training them separately. Experiment results on several simulated high-dimensional robot dynamics and a real-world differential drive robot (TurtleBot3) demonstrate the effectiveness of our approach on five different types of task constraints. Demo videos, code, and models can be found at our project website: https://sites.google.com/view/dscrl
DistSPECTRL: Distributing Specifications in Multi-Agent Reinforcement Learning Systems
Jun 28, 2022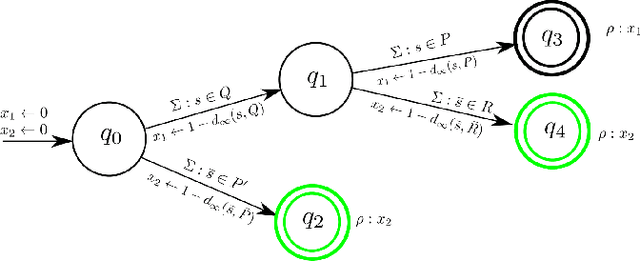
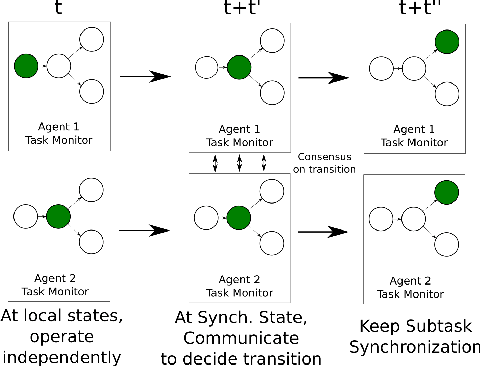
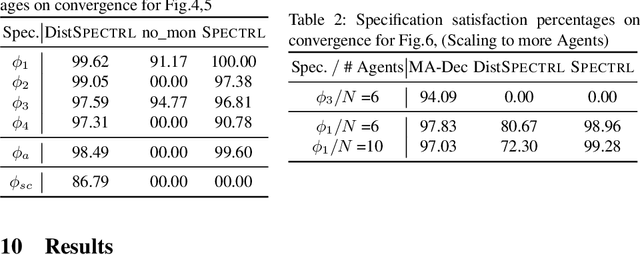
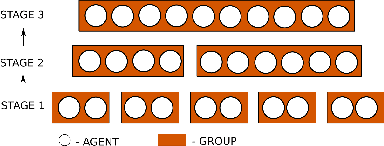
While notable progress has been made in specifying and learning objectives for general cyber-physical systems, applying these methods to distributed multi-agent systems still pose significant challenges. Among these are the need to (a) craft specification primitives that allow expression and interplay of both local and global objectives, (b) tame explosion in the state and action spaces to enable effective learning, and (c) minimize coordination frequency and the set of engaged participants for global objectives. To address these challenges, we propose a novel specification framework that allows natural composition of local and global objectives used to guide training of a multi-agent system. Our technique enables learning expressive policies that allow agents to operate in a coordination-free manner for local objectives, while using a decentralized communication protocol for enforcing global ones. Experimental results support our claim that sophisticated multi-agent distributed planning problems can be effectively realized using specification-guided learning.
Defending Observation Attacks in Deep Reinforcement Learning via Detection and Denoising
Jun 14, 2022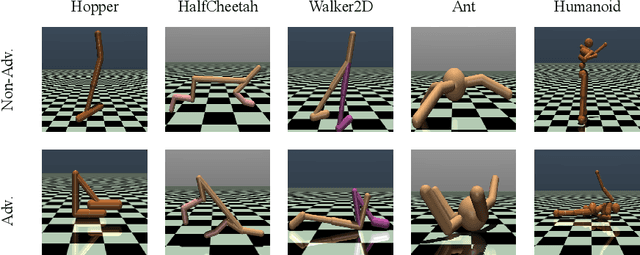
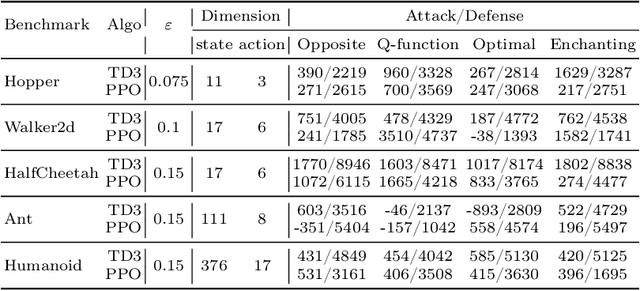
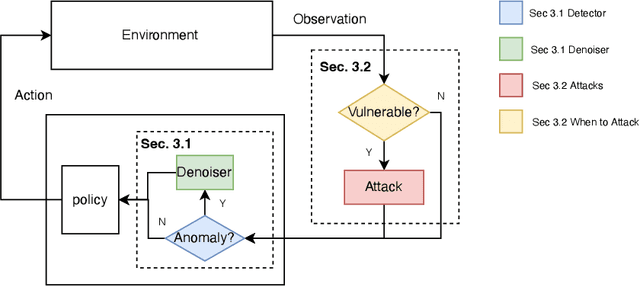
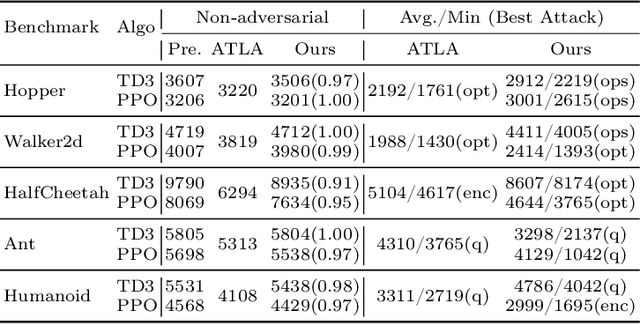
Neural network policies trained using Deep Reinforcement Learning (DRL) are well-known to be susceptible to adversarial attacks. In this paper, we consider attacks manifesting as perturbations in the observation space managed by the external environment. These attacks have been shown to downgrade policy performance significantly. We focus our attention on well-trained deterministic and stochastic neural network policies in the context of continuous control benchmarks subject to four well-studied observation space adversarial attacks. To defend against these attacks, we propose a novel defense strategy using a detect-and-denoise schema. Unlike previous adversarial training approaches that sample data in adversarial scenarios, our solution does not require sampling data in an environment under attack, thereby greatly reducing risk during training. Detailed experimental results show that our technique is comparable with state-of-the-art adversarial training approaches.
Model-free Neural Lyapunov Control for Safe Robot Navigation
Mar 02, 2022
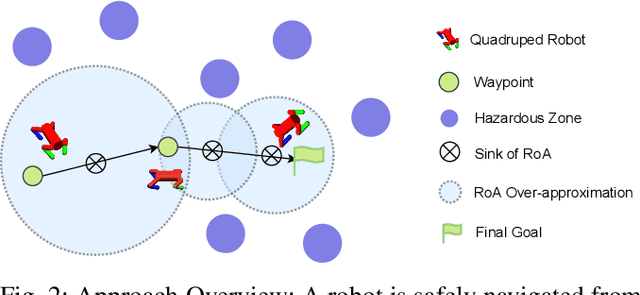
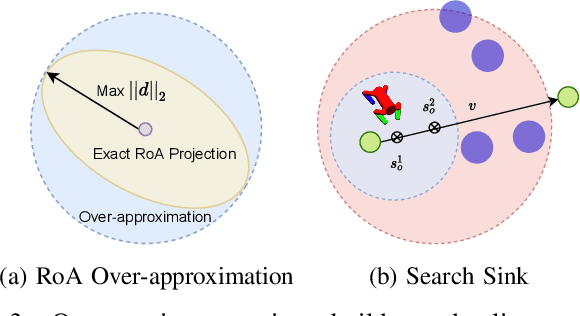
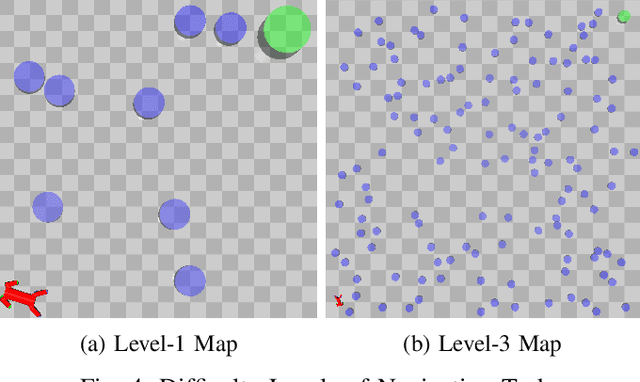
Model-free Deep Reinforcement Learning (DRL) controllers have demonstrated promising results on various challenging non-linear control tasks. While a model-free DRL algorithm can solve unknown dynamics and high-dimensional problems, it lacks safety assurance. Although safety constraints can be encoded as part of a reward function, there still exists a large gap between an RL controller trained with this modified reward and a safe controller. In contrast, instead of implicitly encoding safety constraints with rewards, we explicitly co-learn a Twin Neural Lyapunov Function (TNLF) with the control policy in the DRL training loop and use the learned TNLF to build a runtime monitor. Combined with the path generated from a planner, the monitor chooses appropriate waypoints that guide the learned controller to provide collision-free control trajectories. Our approach inherits the scalability advantages from DRL while enhancing safety guarantees. Our experimental evaluation demonstrates the effectiveness of our approach compared to DRL with augmented rewards and constrained DRL methods over a range of high-dimensional safety-sensitive navigation tasks.
Robustness to Adversarial Attacks in Learning-Enabled Controllers
Jun 11, 2020

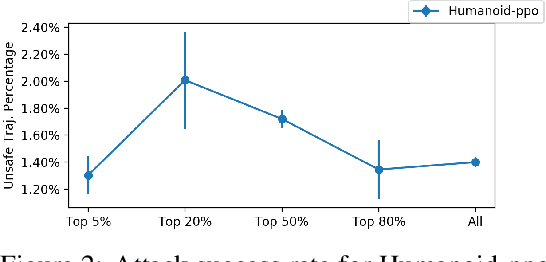

Learning-enabled controllers used in cyber-physical systems (CPS) are known to be susceptible to adversarial attacks. Such attacks manifest as perturbations to the states generated by the controller's environment in response to its actions. We consider state perturbations that encompass a wide variety of adversarial attacks and describe an attack scheme for discovering adversarial states. To be useful, these attacks need to be natural, yielding states in which the controller can be reasonably expected to generate a meaningful response. We consider shield-based defenses as a means to improve controller robustness in the face of such perturbations. Our defense strategy allows us to treat the controller and environment as black-boxes with unknown dynamics. We provide a two-stage approach to construct this defense and show its effectiveness through a range of experiments on realistic continuous control domains such as the navigation control-loop of an F16 aircraft and the motion control system of humanoid robots.