 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-S$^4$: Language-Guided Self-Supervised Semantic Segmentation
May 01, 2023



Existing semantic segmentation approaches are often limited by costly pixel-wise annotations and predefined classes. In this work, we present CLIP-S$^4$ that leverages self-supervised pixel representation learning and vision-language models to enable various semantic segmentation tasks (e.g., unsupervised, transfer learning, language-driven segmentation) without any human annotations and unknown class information. We first learn pixel embeddings with pixel-segment contrastive learning from different augmented views of images. To further improve the pixel embeddings and enable language-driven semantic segmentation, we design two types of consistency guided by vision-language models: 1) embedding consistency, aligning our pixel embeddings to the joint feature space of a pre-trained vision-language model, CLIP; and 2) semantic consistency, forcing our model to make the same predictions as CLIP over a set of carefully designed target classes with both known and unknown prototypes. Thus, CLIP-S$^4$ enables a new task of class-free semantic segmentation where no unknown class information is needed during training. As a result, our approach shows consistent and substantial performance improvement over four popular benchmarks compared with the state-of-the-art unsupervised and language-driven semantic segmentation methods. More importantly, our method outperforms these methods on unknown class recognition by a large margin.
Interactive Visual Study of Multiple Attributes Learning Model of X-Ray Scattering Images
Sep 03, 2020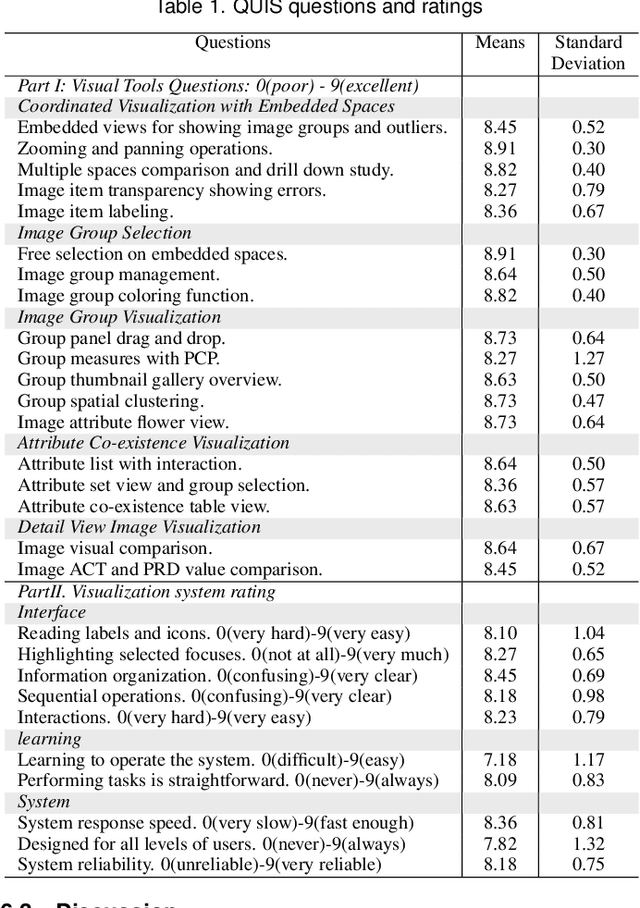
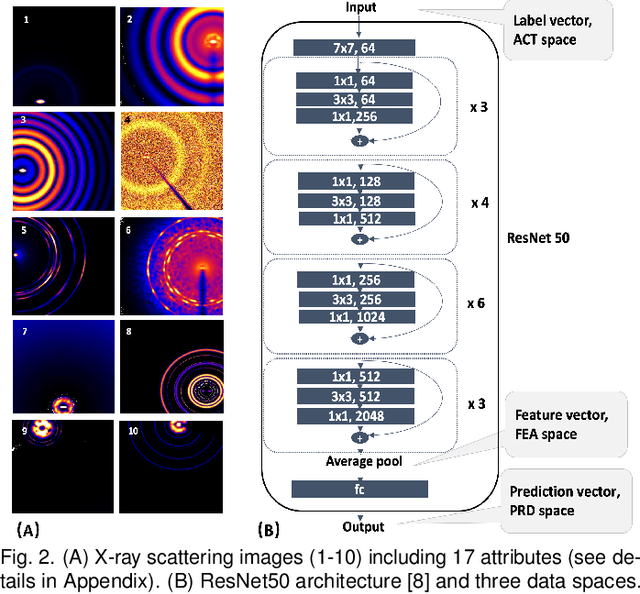
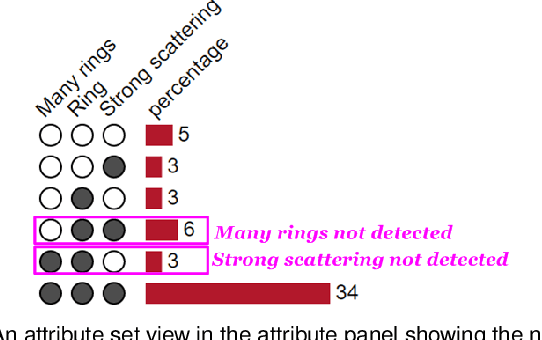
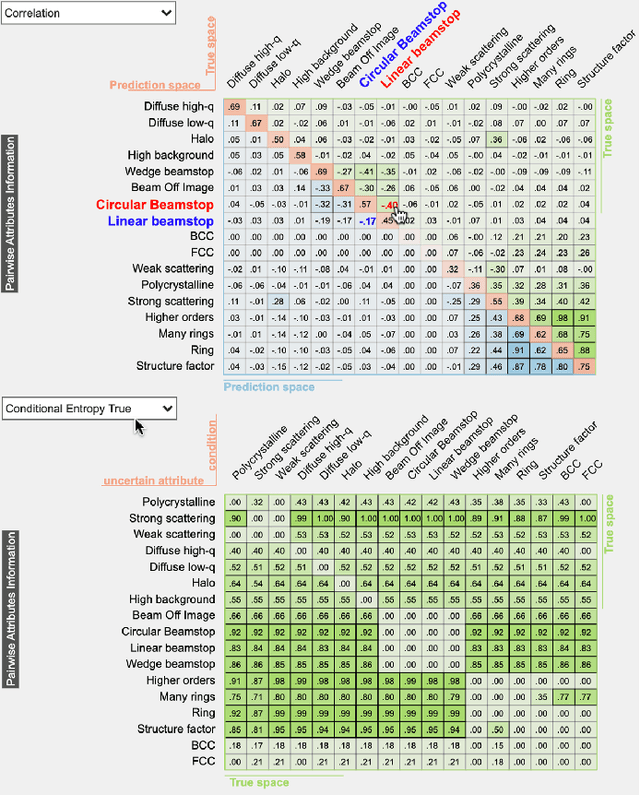
Existing interactive visualization tools for deep learning are mostly applied to the training, debugging, and refinement of neural network models working on natural images. However, visual analytics tools are lacking for the specific application of x-ray image classification with multiple structural attributes. In this paper, we present an interactive system for domain scientists to visually study the multiple attributes learning models applied to x-ray scattering images. It allows domain scientists to interactively explore this important type of scientific images in embedded spaces that are defined on the model prediction output, the actual labels, and the discovered feature space of neural networks. Users are allowed to flexibly select instance images, their clusters, and compare them regarding the specified visual representation of attributes. The exploration is guided by the manifestation of model performance related to mutual relationships among attributes, which often affect the learning accuracy and effectiveness. The system thus supports domain scientists to improve the training dataset and model, find questionable attributes labels, and identify outlier images or spurious data clusters. Case studies and scientists feedback demonstrate its functionalities and usefulness.
* IEEE SciVis Conference 2020
Visual Understanding of Multiple Attributes Learning Model of X-Ray Scattering Images
Oct 10, 2019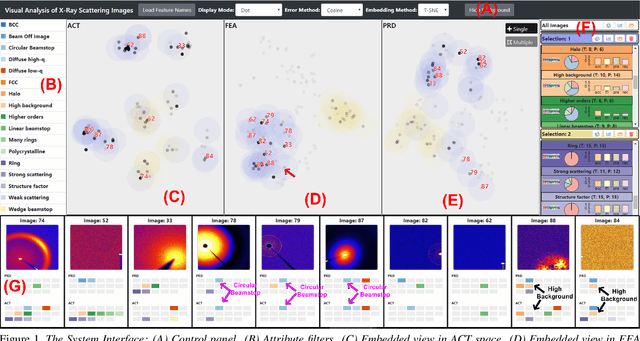

This extended abstract presents a visualization system, which is designed for domain scientists to visually understand their deep learning model of extracting multiple attributes in x-ray scattering images. The system focuses on studying the model behaviors related to multiple structural attributes. It allows users to explore the images in the feature space, the classification output of different attributes, with respect to the actual attributes labelled by domain scientists. Abundant interactions allow users to flexibly select instance images, their clusters, and compare them visually in details. Two preliminary case studies demonstrate its functionalities and usefulness.