 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame Theoretic Decision Making by Actively Learning Human Intentions Applied on Autonomous Driving
Jan 22, 2023The ability to estimate human intentions and interact with human drivers intelligently is crucial for autonomous vehicles to successfully achieve their objectives. In this paper, we propose a game theoretic planning algorithm that models human opponents with an iterative reasoning framework and estimates human latent cognitive states through probabilistic inference and active learning. By modeling the interaction as a partially observable Markov decision process with adaptive state and action spaces, our algorithm is able to accomplish real-time lane changing tasks in a realistic driving simulator. We compare our algorithm's lane changing performance in dense traffic with a state-of-the-art autonomous lane changing algorithm to show the advantage of iterative reasoning and active learning in terms of avoiding overly conservative behaviors and achieving the driving objective successfully.
Automatic Curricula via Expert Demonstrations
Jun 16, 2021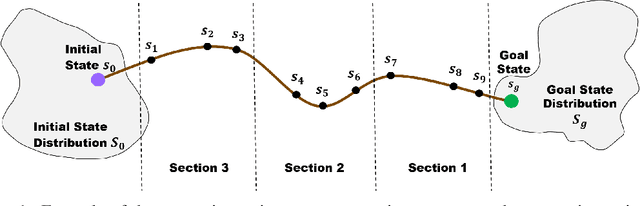
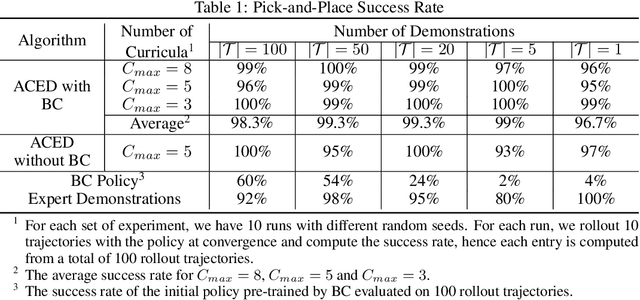
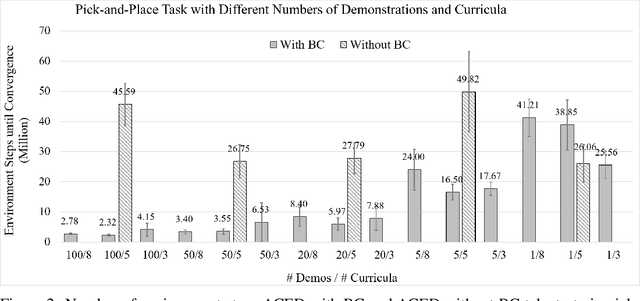
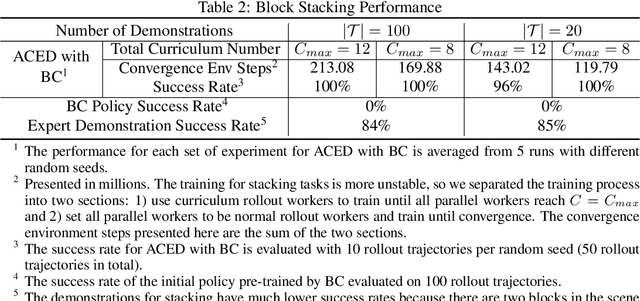
We propose Automatic Curricula via Expert Demonstrations (ACED), a reinforcement learning (RL) approach that combines the ideas of imitation learning and curriculum learning in order to solve challenging robotic manipulation tasks with sparse reward functions. Curriculum learning solves complicated RL tasks by introducing a sequence of auxiliary tasks with increasing difficulty, yet how to automatically design effective and generalizable curricula remains a challenging research problem. ACED extracts curricula from a small amount of expert demonstration trajectories by dividing demonstrations into sections and initializing training episodes to states sampled from different sections of demonstrations. Through moving the reset states from the end to the beginning of demonstrations as the learning agent improves its performance, ACED not only learns challenging manipulation tasks with unseen initializations and goals, but also discovers novel solutions that are distinct from the demonstrations. In addition, ACED can be naturally combined with other imitation learning methods to utilize expert demonstrations in a more efficient manner, and we show that a combination of ACED with behavior cloning allows pick-and-place tasks to be learned with as few as 1 demonstration and block stacking tasks to be learned with 20 demonstrations.
Fast-reactive probabilistic motion planning for high-dimensional robots
Dec 03, 2020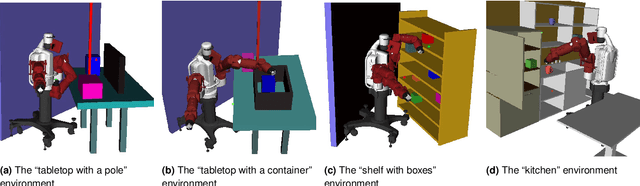
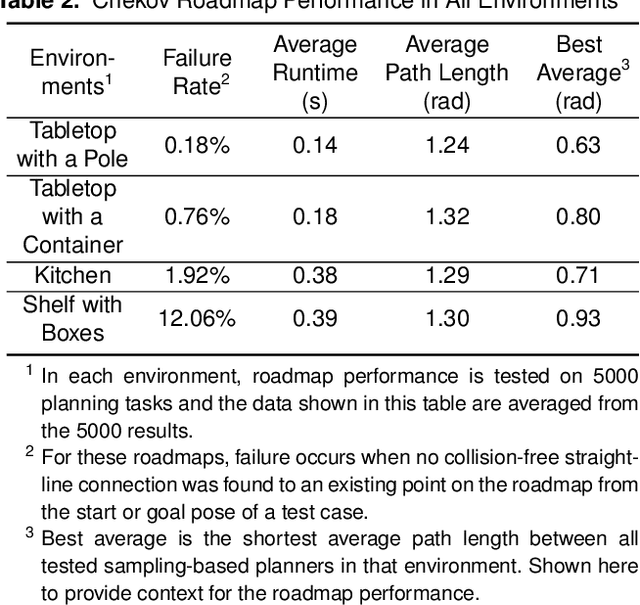
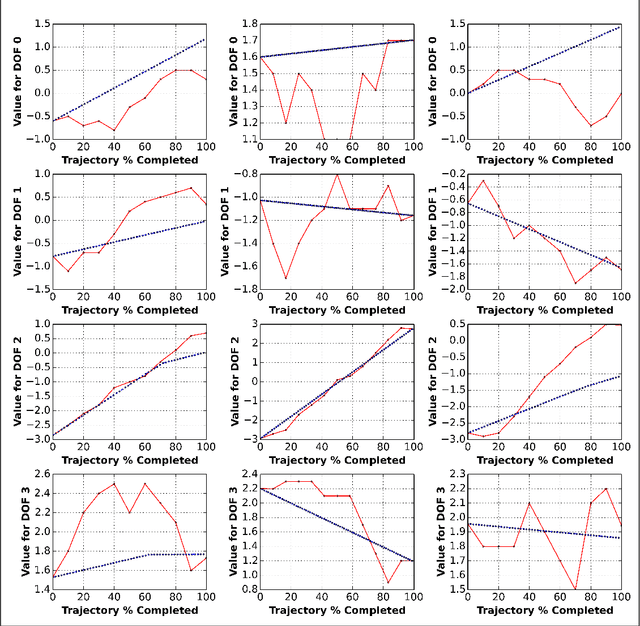
Many real-world robotic operations that involve high-dimensional humanoid robots require fast-reaction to plan disturbances and probabilistic guarantees over collision risks, whereas most probabilistic motion planning approaches developed for car-like robots can not be directly applied to high-dimensional robots. In this paper, we present probabilistic Chekov (p-Chekov), a fast-reactive motion planning system that can provide safety guarantees for high-dimensional robots suffering from process noises and observation noises. Leveraging recent advances in machine learning as well as our previous work in deterministic motion planning that integrated trajectory optimization into a sparse roadmap framework, p-Chekov demonstrates its superiority in terms of collision avoidance ability and planning speed in high-dimensional robotic motion planning tasks in complex environments without the convexification of obstacles. Comprehensive theoretical and empirical analysis provided in this paper shows that p-Chekov can effectively satisfy user-specified chance constraints over collision risk in practical robotic manipulation tasks.
An Empowerment-based Solution to Robotic Manipulation Tasks with Sparse Rewards
Oct 15, 2020
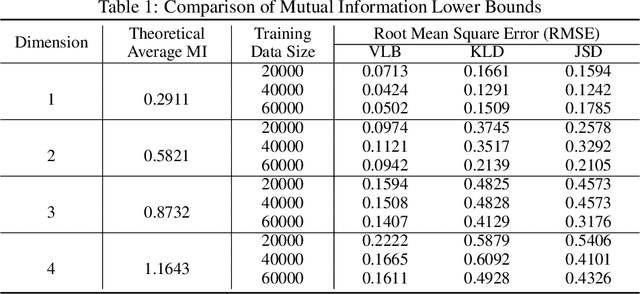
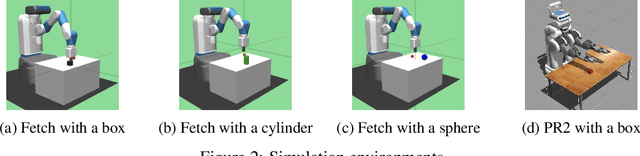
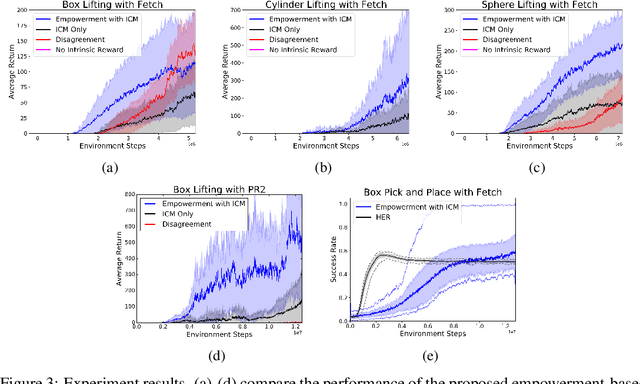
In order to provide adaptive and user-friendly solutions to robotic manipulation, it is important that the agent can learn to accomplish tasks even if they are only provided with very sparse instruction signals. To address the issues reinforcement learning algorithms face when task rewards are sparse, this paper proposes a novel form of intrinsic motivation that can allow robotic manipulators to learn useful manipulation skills with only sparse extrinsic rewards. Through integrating and balancing empowerment and curiosity, this approach shows superior performance compared to other existing intrinsic exploration approaches during extensive empirical testing. Qualitative analysis also shows that when combined with diversity-driven intrinsic motivations, this approach can help manipulators learn a set of diverse skills which could potentially be applied to other more complicated manipulation tasks and accelerate their learning process.
Chance Constrained Motion Planning for High-Dimensional Robots
Nov 07, 2018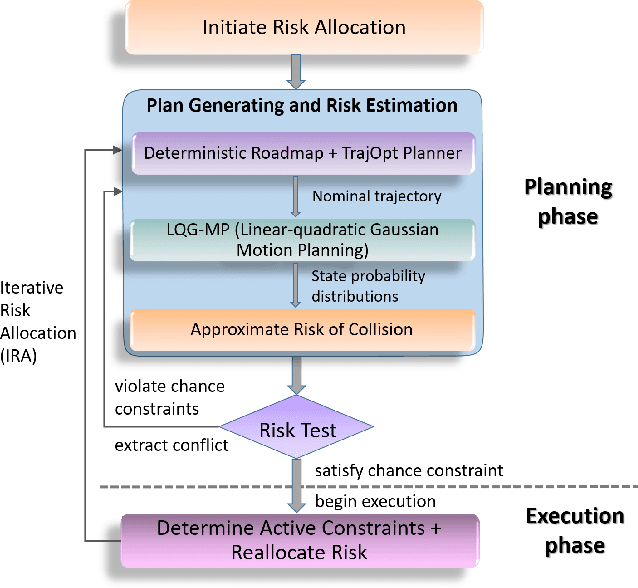
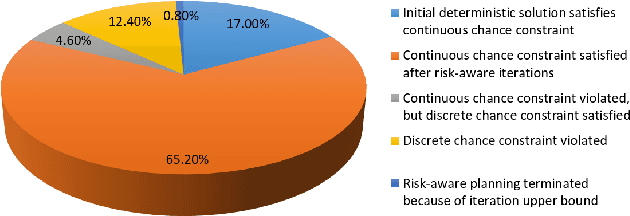
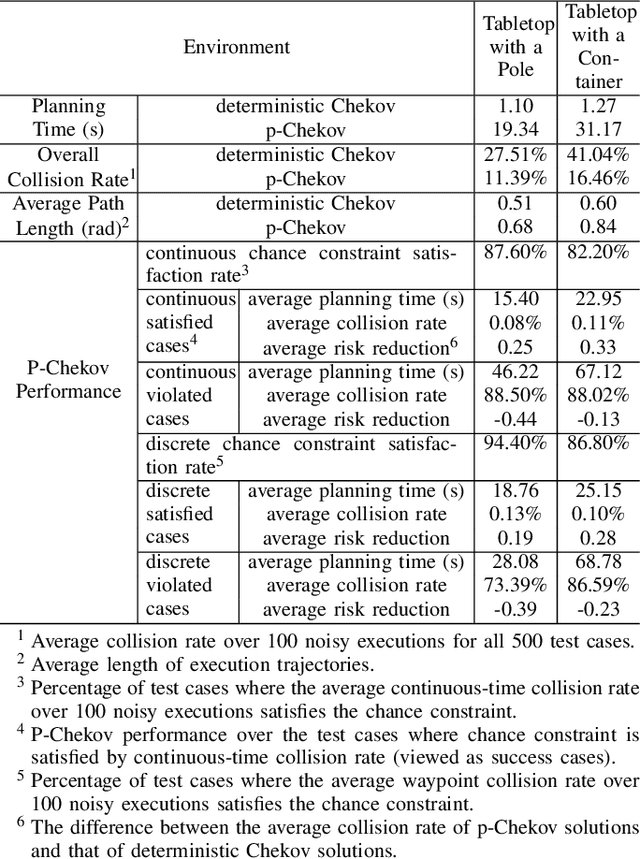
This paper introduces Probabilistic Chekov (p-Chekov), a chance-constrained motion planning system that can be applied to high degree-of-freedom (DOF) robots under motion uncertainty and imperfect state information. Given process and observation noise models, it can find feasible trajectories which satisfy a user-specified bound over the probability of collision. Leveraging our previous work in deterministic motion planning which integrated trajectory optimization into a sparse roadmap framework, p-Chekov shows superiority in its planning speed for high-dimensional tasks. P-Chekov incorporates a linear-quadratic Gaussian motion planning approach into the estimation of the robot state probability distribution, applies quadrature theories to waypoint collision risk estimation, and adapts risk allocation approaches to assign allowable probabilities of failure among waypoints. Unlike other existing risk-aware planners, p-Chekov can be applied to high-DOF robotic planning tasks without the convexification of the environment. The experiment results in this paper show that this p-Chekov system can effectively reduce collision risk and satisfy user-specified chance constraints in typical real-world planning scenarios for high-DOF robots.
Improving Trajectory Optimization using a Roadmap Framework
Nov 05, 2018

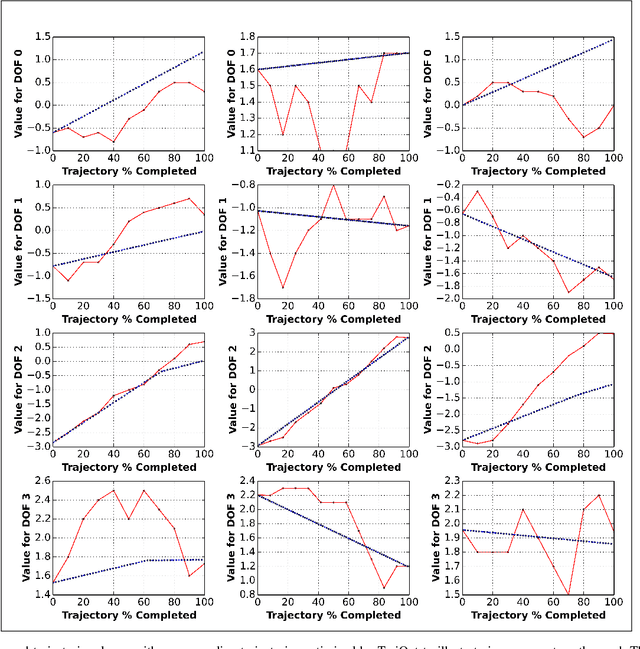
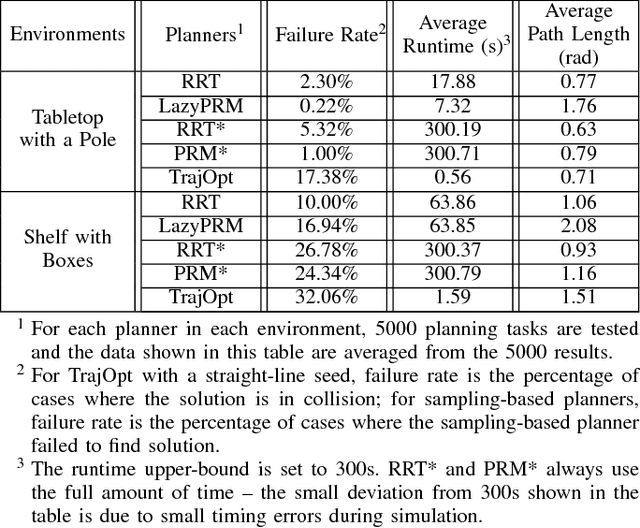
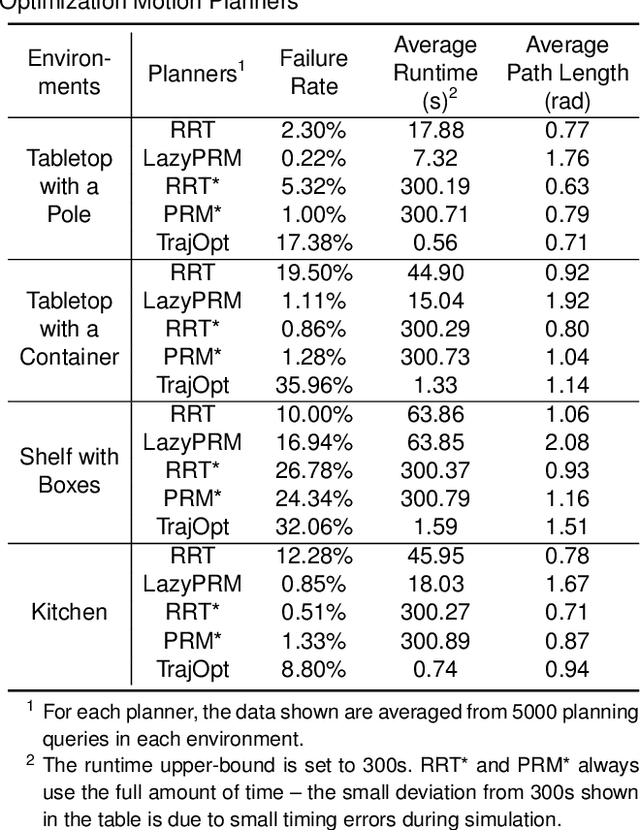
We present an evaluation of several representative sampling-based and optimization-based motion planners, and then introduce an integrated motion planning system which incorporates recent advances in trajectory optimization into a sparse roadmap framework. Through experiments in 4 common application scenarios with 5000 test cases each, we show that optimization-based or sampling-based planners alone are not effective for realistic problems where fast planning times are required. To the best of our knowledge, this is the first work that presents such a systematic and comprehensive evaluation of state-of-the-art motion planners, which are based on a significant amount of experiments. We then combine different stand-alone planners with trajectory optimization. The results show that the combination of our sparse roadmap and trajectory optimization provides superior performance over other standard sampling-based planners combinations. By using a multi-query roadmap instead of generating completely new trajectories for each planning problem, our approach allows for extensions such as persistent control policy information associated with a trajectory across planning problems. Also, the sub-optimality resulting from the sparsity of roadmap, as well as the unexpected disturbances from the environment, can both be overcome by the real-time trajectory optimization process.