 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SwaNNFlight System: On-the-Fly Sim-to-Real Adaptation via Anchored Learning
Jan 17, 2023Reinforcement Learning (RL) agents trained in simulated environments and then deployed in the real world are often sensitive to the differences in dynamics presented, commonly termed the sim-to-real gap. With the goal of minimizing this gap on resource-constrained embedded systems, we train and live-adapt agents on quadrotors built from off-the-shelf hardware. In achieving this we developed three novel contributions. (i) SwaNNFlight, an open-source firmware enabling wireless data capture and transfer of agents' observations. Fine-tuning agents with new data, and receiving and swapping onboard NN controllers -- all while in flight. We also design SwaNNFlight System (SwaNNFS) allowing new research in training and live-adapting learning agents on similar systems. (ii) Multiplicative value composition, a technique for preserving the importance of each policy optimization criterion, improving training performance and variability in learnt behavior. And (iii) anchor critics to help stabilize the fine-tuning of agents during sim-to-real transfer, online learning from real data while retaining behavior optimized in simulation. We train consistently flight-worthy control policies in simulation and deploy them on real quadrotors. We then achieve live controller adaptation via over-the-air updates of the onboard control policy from a ground station. Our results indicate that live adaptation unlocks a near-50\% reduction in power consumption, attributed to the sim-to-real gap. Finally, we tackle the issues of catastrophic forgetting and controller instability, showing the effectiveness of our novel methods. Project Website: https://github.com/BU-Cyber-Physical-Systems-Lab/SwaNNFS
Designing Composites with Target Effective Young's Modulus using Reinforcement Learning
Oct 07, 2021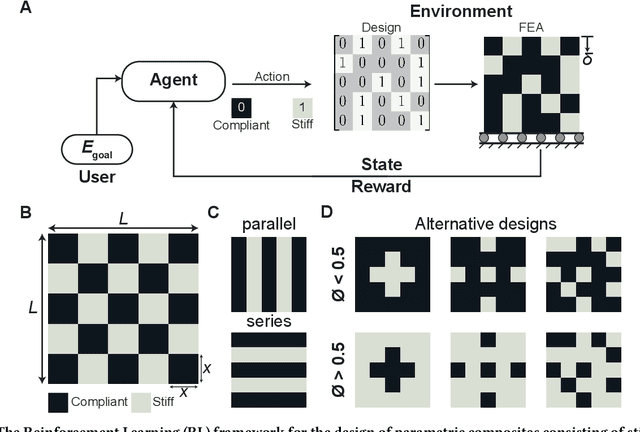
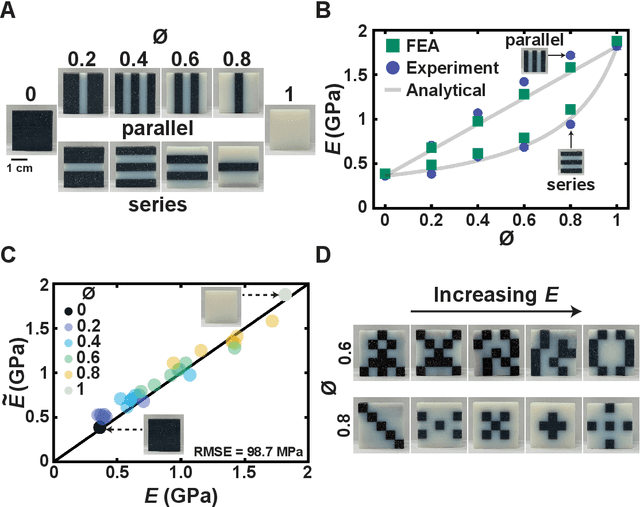
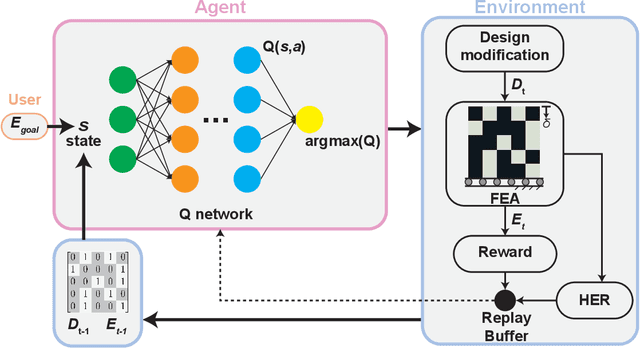

Advancements in additive manufacturing have enabled design and fabrication of materials and structures not previously realizable. In particular, the design space of composite materials and structures has vastly expanded, and the resulting size and complexity has challenged traditional design methodologies, such as brute force exploration and one factor at a time (OFAT) exploration, to find optimum or tailored designs. To address this challenge, supervised machine learning approaches have emerged to model the design space using curated training data; however, the selection of the training data is often determined by the user. In this work, we develop and utilize a Reinforcement learning (RL)-based framework for the design of composite structures which avoids the need for user-selected training data. For a 5 $\times$ 5 composite design space comprised of soft and compliant blocks of constituent material, we find that using this approach, the model can be trained using 2.78% of the total design space consists of $2^{25}$ design possibilities. Additionally, the developed RL-based framework is capable of finding designs at a success rate exceeding 90%. The success of this approach motivates future learning frameworks to utilize RL for the design of composites and other material systems.
Good Actors can come in Smaller Sizes: A Case Study on the Value of Actor-Critic Asymmetry
Feb 23, 2021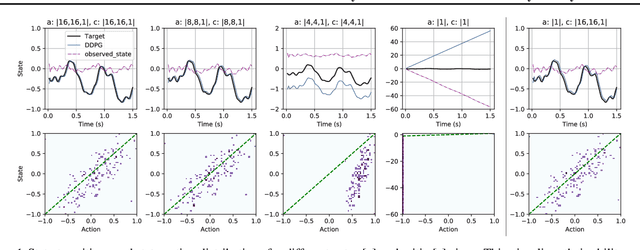
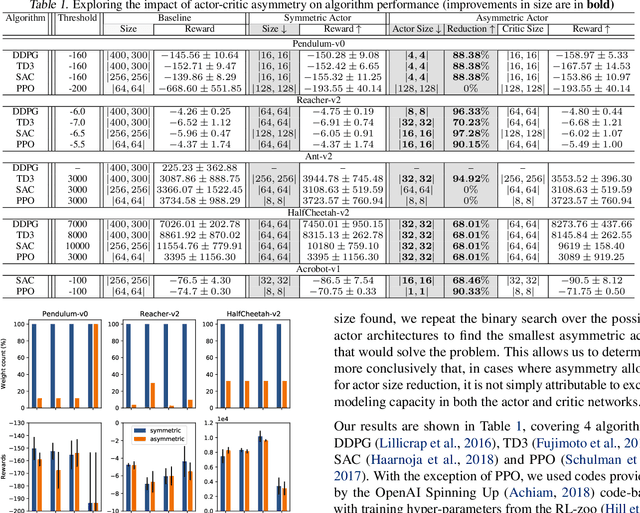
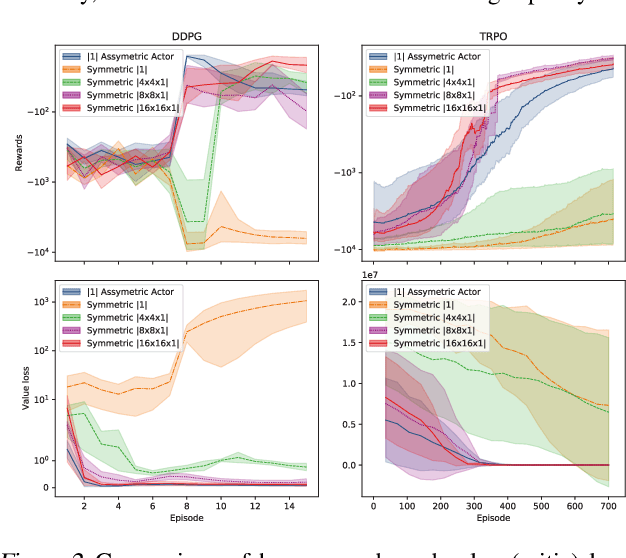
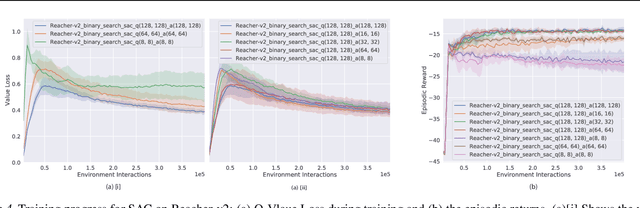
Actors and critics in actor-critic reinforcement learning algorithms are functionally separate, yet they often use the same network architectures. This case study explores the performance impact of network sizes when considering actor and critic architectures independently. By relaxing the assumption of architectural symmetry, it is often possible for smaller actors to achieve comparable policy performance to their symmetric counterparts. Our experiments show up to 97% reduction in the number of network weights with an average reduction of 64% over multiple algorithms on multiple tasks. Given the practical benefits of reducing actor complexity, we believe configurations of actors and critics are aspects of actor-critic design that deserve to be considered independently.
How to Train your Quadrotor: A Framework for Consistently Smooth and Responsive Flight Control via Reinforcement Learning
Dec 11, 2020
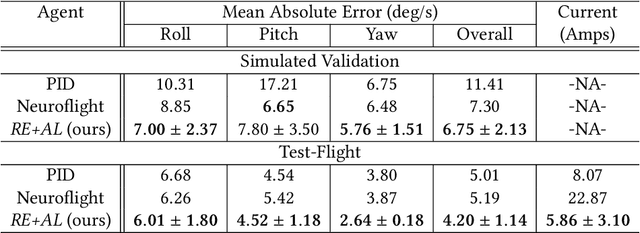
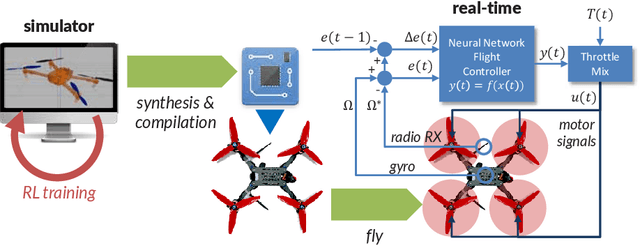
We focus on the problem of reliably training Reinforcement Learning (RL) models (agents) for stable low-level control in embedded systems and test our methods on a high-performance, custom-built quadrotor platform. A common but often under-studied problem in developing RL agents for continuous control is that the control policies developed are not always smooth. This lack of smoothness can be a major problem when learning controllers %intended for deployment on real hardware as it can result in control instability and hardware failure. Issues of noisy control are further accentuated when training RL agents in simulation due to simulators ultimately being imperfect representations of reality - what is known as the reality gap. To combat issues of instability in RL agents, we propose a systematic framework, `REinforcement-based transferable Agents through Learning' (RE+AL), for designing simulated training environments which preserve the quality of trained agents when transferred to real platforms. RE+AL is an evolution of the Neuroflight infrastructure detailed in technical reports prepared by members of our research group. Neuroflight is a state-of-the-art framework for training RL agents for low-level attitude control. RE+AL improves and completes Neuroflight by solving a number of important limitations that hindered the deployment of Neuroflight to real hardware. We benchmark RE+AL on the NF1 racing quadrotor developed as part of Neuroflight. We demonstrate that RE+AL significantly mitigates the previously observed issues of smoothness in RL agents. Additionally, RE+AL is shown to consistently train agents that are flight-capable and with minimal degradation in controller quality upon transfer. RE+AL agents also learn to perform better than a tuned PID controller, with better tracking errors, smoother control and reduced power consumption.
Regularizing Action Policies for Smooth Control with Reinforcement Learning
Dec 11, 2020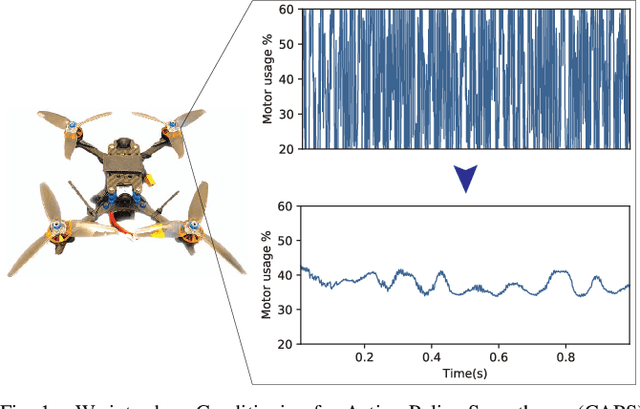
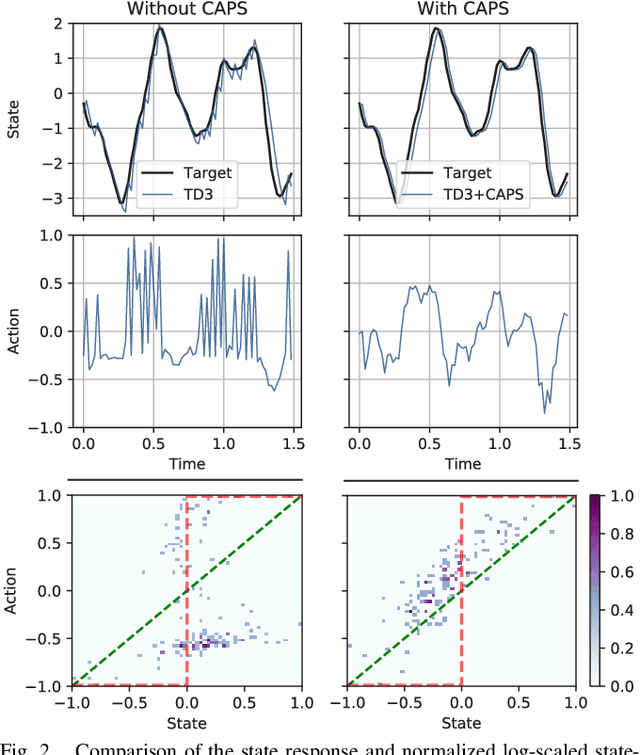
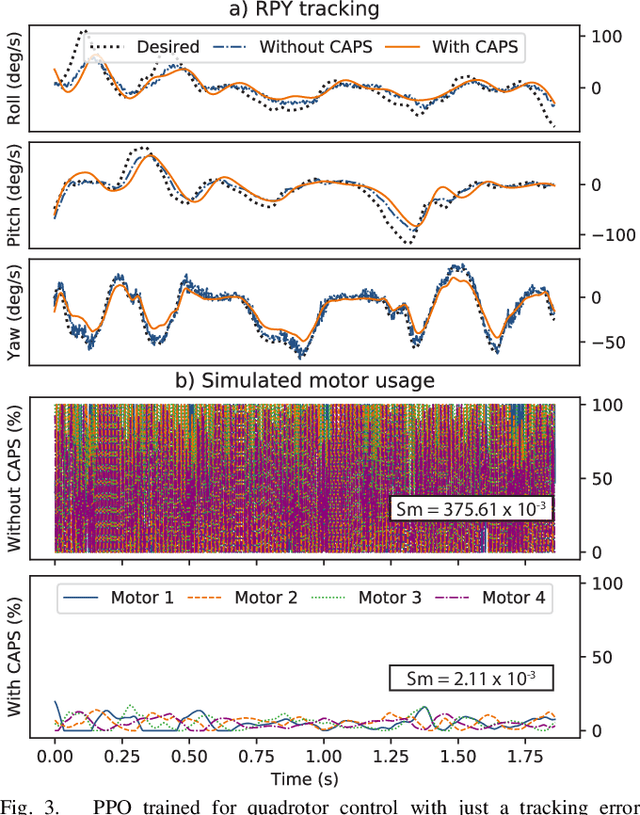
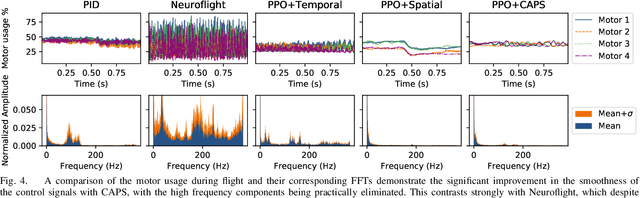
A critical problem with the practical utility of controllers trained with deep Reinforcement Learning (RL) is the notable lack of smoothness in the actions learned by the RL policies. This trend often presents itself in the form of control signal oscillation and can result in poor control, high power consumption, and undue system wear. We introduce Conditioning for Action Policy Smoothness (CAPS), an effective yet intuitive regularization on action policies, which offers consistent improvement in the smoothness of the learned state-to-action mappings of neural network controllers, reflected in the elimination of high-frequency components in the control signal. Tested on a real system, improvements in controller smoothness on a quadrotor drone resulted in an almost 80% reduction in power consumption while consistently training flight-worthy controllers. Project website: http://ai.bu.edu/caps