 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Action Policies for Smooth Control with Reinforcement Learning
Paper and Code
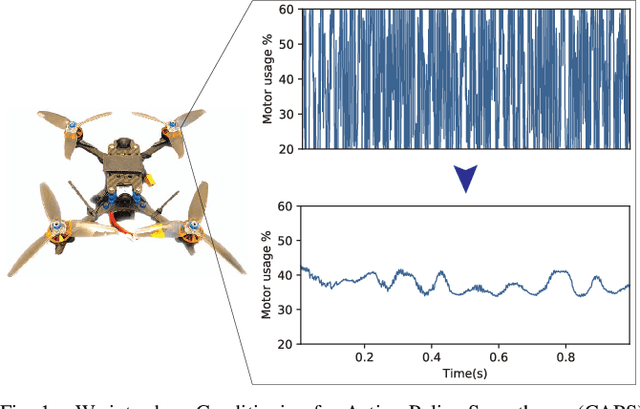
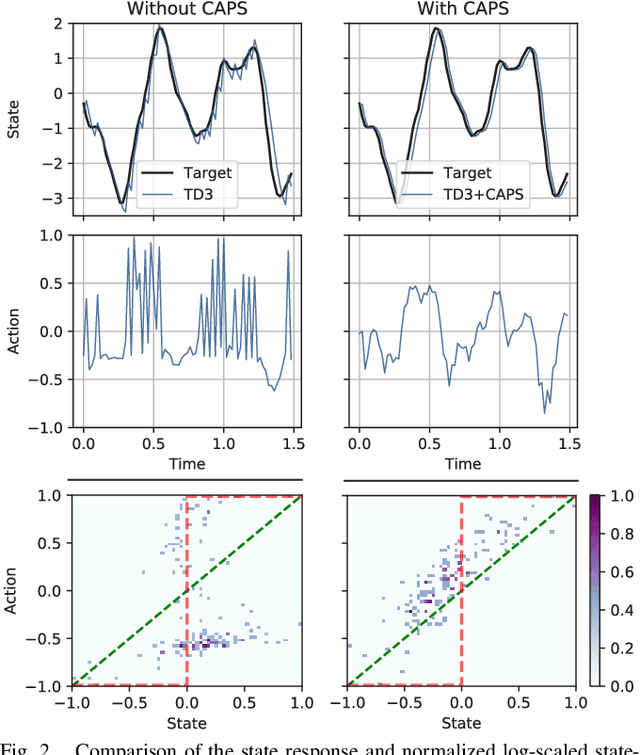
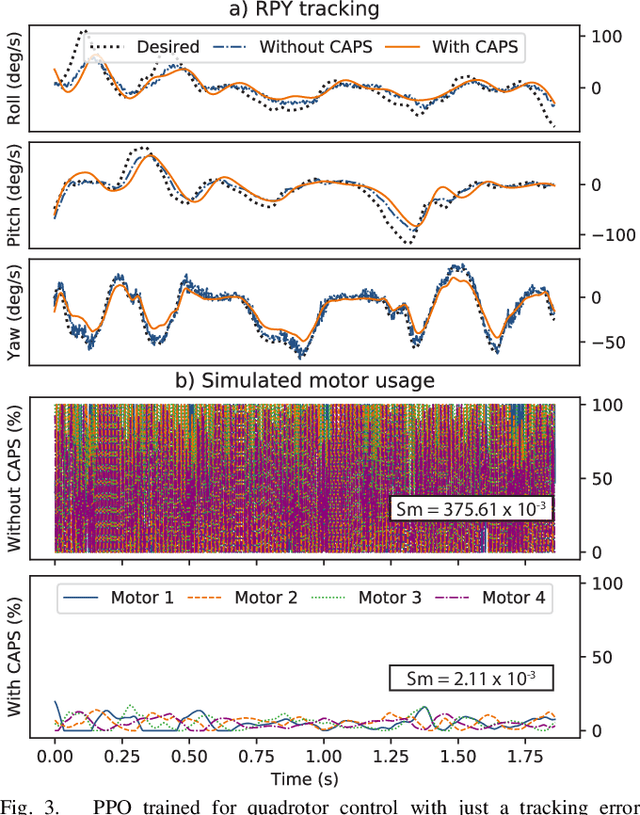
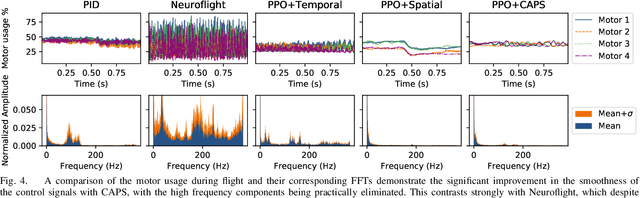
A critical problem with the practical utility of controllers trained with deep Reinforcement Learning (RL) is the notable lack of smoothness in the actions learned by the RL policies. This trend often presents itself in the form of control signal oscillation and can result in poor control, high power consumption, and undue system wear. We introduce Conditioning for Action Policy Smoothness (CAPS), an effective yet intuitive regularization on action policies, which offers consistent improvement in the smoothness of the learned state-to-action mappings of neural network controllers, reflected in the elimination of high-frequency components in the control signal. Tested on a real system, improvements in controller smoothness on a quadrotor drone resulted in an almost 80% reduction in power consumption while consistently training flight-worthy controllers. Project website: http://ai.bu.edu/caps