 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Unconstrained Features: Neural Collapse for Shallow Neural Networks with General Data
Sep 03, 2024



Neural collapse (NC) is a phenomenon that emerges at the terminal phase of the training (TPT) of deep neural networks (DNNs). The features of the data in the same class collapse to their respective sample means and the sample means exhibit a simplex equiangular tight frame (ETF). In the past few years, there has been a surge of works that focus on explaining why the NC occurs and how it affects generalization. Since the DNNs are notoriously difficult to analyze, most works mainly focus on the unconstrained feature model (UFM). While the UFM explains the NC to some extent, it fails to provide a complete picture of how the network architecture and the dataset affect NC. In this work, we focus on shallow ReLU neural networks and try to understand how the width, depth, data dimension, and statistical property of the training dataset influence the neural collapse. We provide a complete characterization of when the NC occurs for two or three-layer neural networks. For two-layer ReLU neural networks, a sufficient condition on when the global minimizer of the regularized empirical risk function exhibits the NC configuration depends on the data dimension, sample size, and the signal-to-noise ratio in the data instead of the network width. For three-layer neural networks, we show that the NC occurs as long as the first layer is sufficiently wide. Regarding the connection between NC and generalization, we show the generalization heavily depends on the SNR (signal-to-noise ratio) in the data: even if the NC occurs, the generalization can still be bad provided that the SNR in the data is too low. Our results significantly extend the state-of-the-art theoretical analysis of the N C under the UFM by characterizing the emergence of the N C under shallow nonlinear networks and showing how it depends on data properties and network architecture.
Cross Entropy versus Label Smoothing: A Neural Collapse Perspective
Feb 07, 2024Label smoothing loss is a widely adopted technique to mitigate overfitting in deep neural networks. This paper studies label smoothing from the perspective of Neural Collapse (NC), a powerful empirical and theoretical framework which characterizes model behavior during the terminal phase of training. We first show empirically that models trained with label smoothing converge faster to neural collapse solutions and attain a stronger level of neural collapse. Additionally, we show that at the same level of NC1, models under label smoothing loss exhibit intensified NC2. These findings provide valuable insights into the performance benefits and enhanced model calibration under label smoothing loss. We then leverage the unconstrained feature model to derive closed-form solutions for the global minimizers for both loss functions and further demonstrate that models under label smoothing have a lower conditioning number and, therefore, theoretically converge faster. Our study, combining empirical evidence and theoretical results, not only provides nuanced insights into the differences between label smoothing and cross-entropy losses, but also serves as an example of how the powerful neural collapse framework can be used to improve our understanding of DNNs.
Neural Collapse for Unconstrained Feature Model under Cross-entropy Loss with Imbalanced Data
Sep 18, 2023



Recent years have witnessed the huge success of deep neural networks (DNNs) in various tasks of computer vision and text processing. Interestingly, these DNNs with massive number of parameters share similar structural properties on their feature representation and last-layer classifier at terminal phase of training (TPT). Specifically, if the training data are balanced (each class shares the same number of samples), it is observed that the feature vectors of samples from the same class converge to their corresponding in-class mean features and their pairwise angles are the same. This fascinating phenomenon is known as Neural Collapse (N C), first termed by Papyan, Han, and Donoho in 2019. Many recent works manage to theoretically explain this phenomenon by adopting so-called unconstrained feature model (UFM). In this paper, we study the extension of N C phenomenon to the imbalanced data under cross-entropy loss function in the context of unconstrained feature model. Our contribution is multi-fold compared with the state-of-the-art results: (a) we show that the feature vectors exhibit collapse phenomenon, i.e., the features within the same class collapse to the same mean vector; (b) the mean feature vectors no longer form an equiangular tight frame. Instead, their pairwise angles depend on the sample size; (c) we also precisely characterize the sharp threshold on which the minority collapse (the feature vectors of the minority groups collapse to one single vector) will take place; (d) finally, we argue that the effect of the imbalance in datasize diminishes as the sample size grows. Our results provide a complete picture of the N C under the cross-entropy loss for the imbalanced data. Numerical experiments confirm our theoretical analysis.
Improved theoretical guarantee for rank aggregation via spectral method
Sep 10, 2023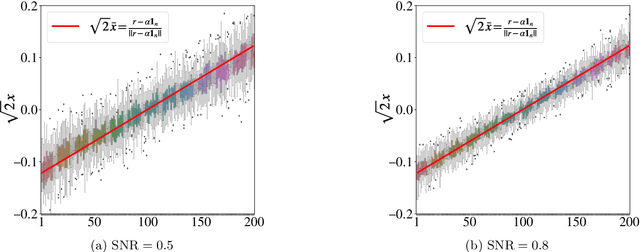
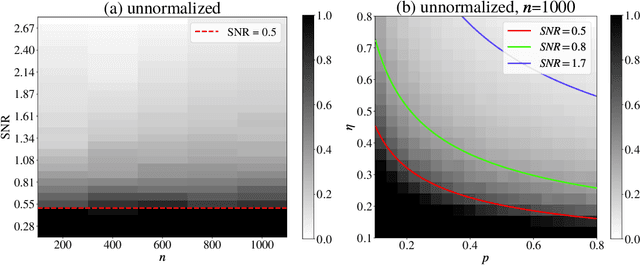
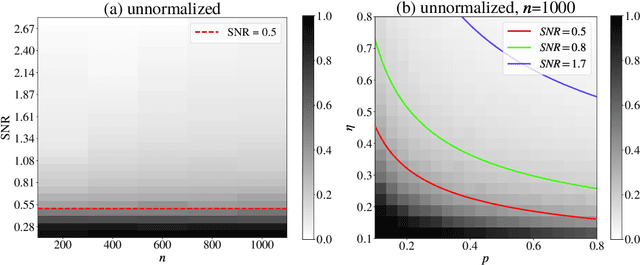
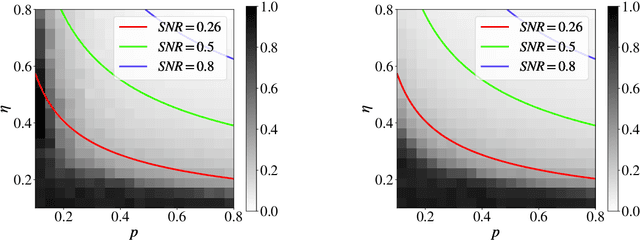
Given pairwise comparisons between multiple items, how to rank them so that the ranking matches the observations? This problem, known as rank aggregation, has found many applications in sports, recommendation systems, and other web applications. As it is generally NP-hard to find a global ranking that minimizes the mismatch (known as the Kemeny optimization), we focus on the Erd\"os-R\'enyi outliers (ERO) model for this ranking problem. Here, each pairwise comparison is a corrupted copy of the true score difference. We investigate spectral ranking algorithms that are based on unnormalized and normalized data matrices. The key is to understand their performance in recovering the underlying scores of each item from the observed data. This reduces to deriving an entry-wise perturbation error bound between the top eigenvectors of the unnormalized/normalized data matrix and its population counterpart. By using the leave-one-out technique, we provide a sharper $\ell_{\infty}$-norm perturbation bound of the eigenvectors and also derive an error bound on the maximum displacement for each item, with only $\Omega(n\log n)$ samples. Our theoretical analysis improves upon the state-of-the-art results in terms of sample complexity, and our numerical experiments confirm these theoretical findings.
Generalized Power Method for Generalized Orthogonal Procrustes Problem: Global Convergence and Optimization Landscape Analysis
Jun 29, 2021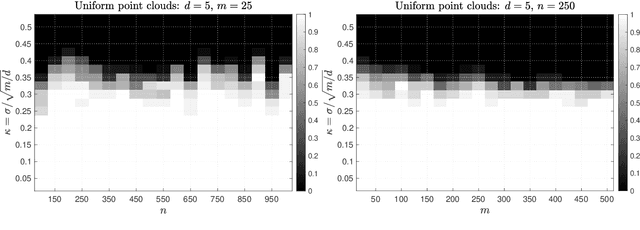
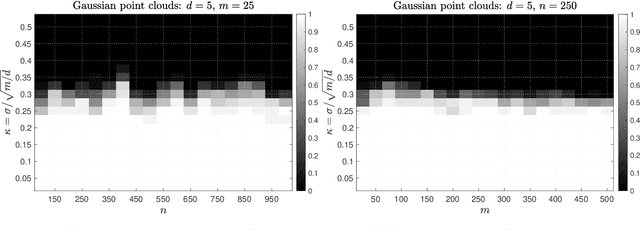
Given a set of multiple point clouds, how to find the rigid transformations (rotation, reflection, and shifting) such that these point clouds are well aligned? This problem, known as the generalized orthogonal Procrustes problem (GOPP), plays a fundamental role in several scientific disciplines including statistics, imaging science and computer vision. Despite its tremendous practical importance, it is still a challenging computational problem due to the inherent nonconvexity. In this paper, we study the semidefinite programming (SDP) relaxation of the generalized orthogonal Procrustes problems and prove that the tightness of the SDP relaxation holds, i.e., the SDP estimator exactly equals the least squares estimator, if the signal-to-noise ratio (SNR) is relatively large. We also prove that an efficient generalized power method with a proper initialization enjoys global linear convergence to the least squares estimator. In addition, we analyze the Burer-Monteiro factorization and show the corresponding optimization landscape is free of spurious local optima if the SNR is large. This explains why first-order Riemannian gradient methods with random initializations usually produce a satisfactory solution despite the nonconvexity. One highlight of our work is that the theoretical guarantees are purely algebraic and do not require any assumptions on the statistical property of the noise. Our results partially resolve one open problem posed in [Bandeira, Khoo, Singer, 2014] on the tightness of the SDP relaxation in solving the generalized orthogonal Procrustes problem. Numerical simulations are provided to complement our theoretical analysis.
Near-Optimal Performance Bounds for Orthogonal and Permutation Group Synchronization via Spectral Methods
Aug 21, 2020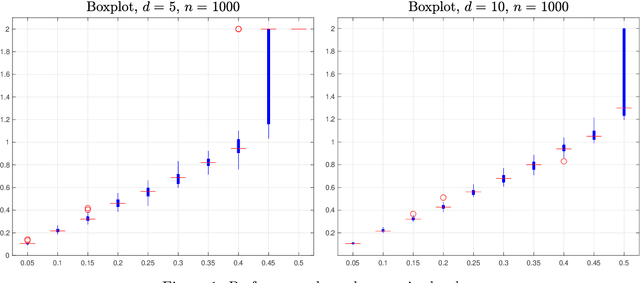
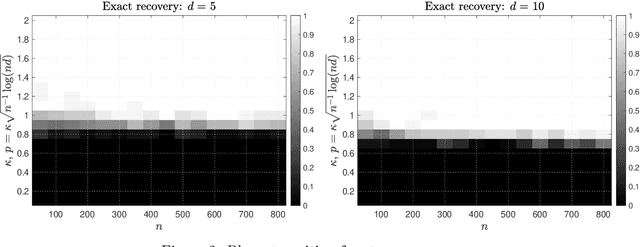
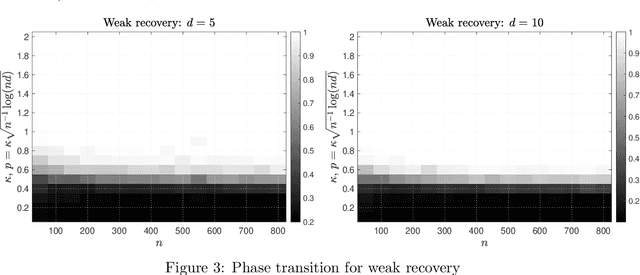
Group synchronization asks to recover group elements from their pairwise measurements. It has found numerous applications across various scientific disciplines. In this work, we focus on orthogonal and permutation group synchronization which are widely used in computer vision such as object matching and Structure from Motion. Among many available approaches, spectral methods have enjoyed great popularity due to its efficiency and convenience. We will study the performance guarantees of spectral methods in solving these two synchronization problems by investigating how well the computed eigenvectors approximate each group element individually. We establish our theory by applying the recent popular~\emph{leave-one-out} technique and derive a~\emph{block-wise} performance bound for the recovery of each group element via eigenvectors. In particular, for orthogonal group synchronization, we obtain a near-optimal performance bound for the group recovery in presence of Gaussian noise. For permutation group synchronization under random corruption, we show that the widely-used two-step procedure (spectral method plus rounding) can recover all the group elements exactly if the SNR (signal-to-noise ratio) is close to the information theoretical limit. Our numerical experiments confirm our theory and indicate a sharp phase transition for the exact group recovery.
Strong Consistency, Graph Laplacians, and the Stochastic Block Model
Apr 21, 2020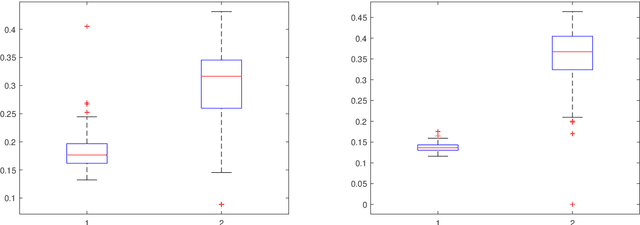
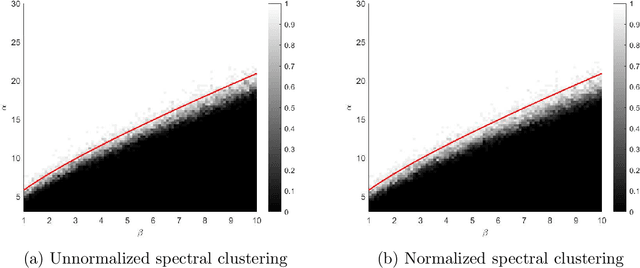
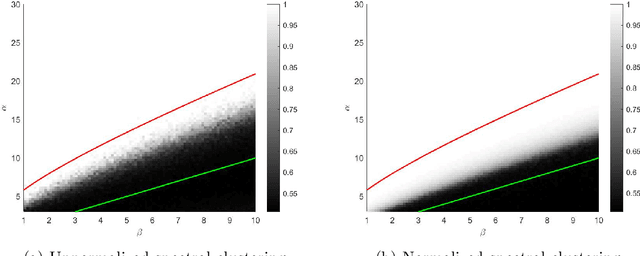
Spectral clustering has become one of the most popular algorithms in data clustering and community detection. We study the performance of classical two-step spectral clustering via the graph Laplacian to learn the stochastic block model. Our aim is to answer the following question: when is spectral clustering via the graph Laplacian able to achieve strong consistency, i.e., the exact recovery of the underlying hidden communities? Our work provides an entrywise analysis (an $\ell_{\infty}$-norm perturbation bound) of the Fielder eigenvector of both the unnormalized and the normalized Laplacian associated with the adjacency matrix sampled from the stochastic block model. We prove that spectral clustering is able to achieve exact recovery of the planted community structure under conditions that match the information-theoretic limits.
Certifying Global Optimality of Graph Cuts via Semidefinite Relaxation: A Performance Guarantee for Spectral Clustering
Jul 08, 2018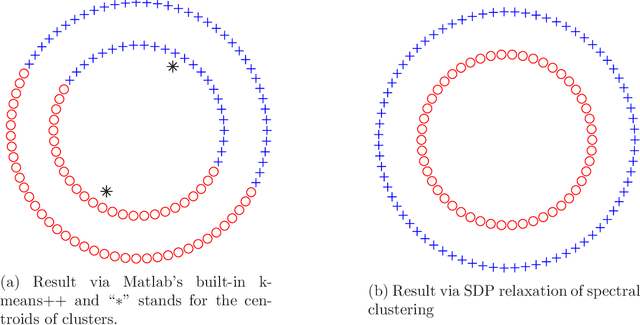
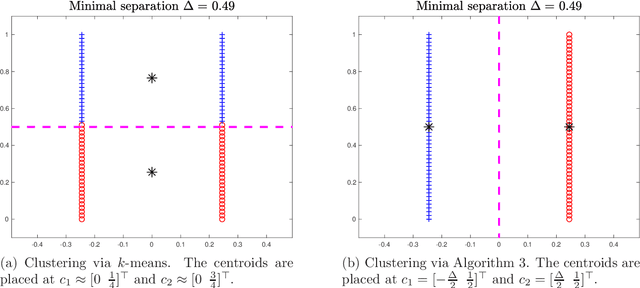
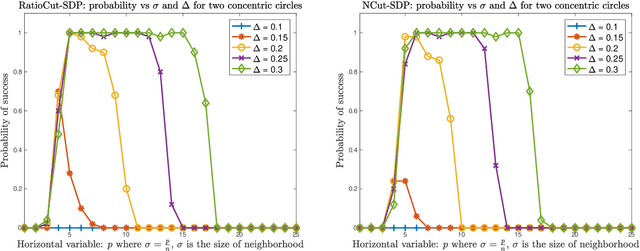
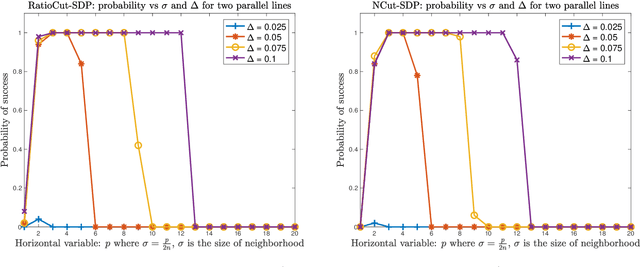
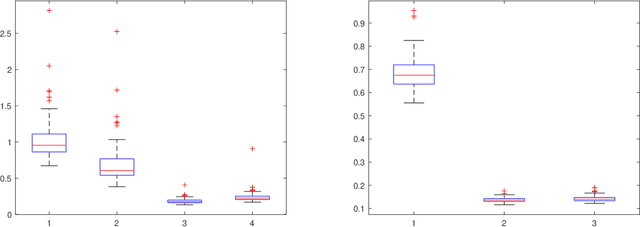
Spectral clustering has become one of the most widely used clustering techniques when the structure of the individual clusters is non-convex or highly anisotropic. Yet, despite its immense popularity, there exists fairly little theory about performance guarantees for spectral clustering. This issue is partly due to the fact that spectral clustering typically involves two steps which complicated its theoretical analysis: first, the eigenvectors of the associated graph Laplacian are used to embed the dataset, and second, k-means clustering algorithm is applied to the embedded dataset to get the labels. This paper is devoted to the theoretical foundations of spectral clustering and graph cuts. We consider a convex relaxation of graph cuts, namely ratio cuts and normalized cuts, that makes the usual two-step approach of spectral clustering obsolete and at the same time gives rise to a rigorous theoretical analysis of graph cuts and spectral clustering. We derive deterministic bounds for successful spectral clustering via a spectral proximity condition that naturally depends on the algebraic connectivity of each cluster and the inter-cluster connectivity. Moreover, we demonstrate by means of some popular examples that our bounds can achieve near-optimality. Our findings are also fundamental for the theoretical understanding of kernel k-means. Numerical simulations confirm and complement our analysis.