 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Anomaly Detection methods on Edge Device using Knowledge Distillation and Quantization
Jul 03, 2024



With the rapid advances in deep learning and smart manufacturing in Industry 4.0, there is an imperative for high-throughput, high-performance, and fully integrated visual inspection systems. Most anomaly detection approaches using defect detection datasets, such as MVTec AD, employ one-class models that require fitting separate models for each class. On the contrary, unified models eliminate the need for fitting separate models for each class and significantly reduce cost and memory requirements. Thus, in this work, we experiment with considering a unified multi-class setup. Our experimental study shows that multi-class models perform at par with one-class models for the standard MVTec AD dataset. Hence, this indicates that there may not be a need to learn separate object/class-wise models when the object classes are significantly different from each other, as is the case of the dataset considered. Furthermore, we have deployed three different unified lightweight architectures on the CPU and an edge device (NVIDIA Jetson Xavier NX). We analyze the quantized multi-class anomaly detection models in terms of latency and memory requirements for deployment on the edge device while comparing quantization-aware training (QAT) and post-training quantization (PTQ) for performance at different precision widths. In addition, we explored two different methods of calibration required in post-training scenarios and show that one of them performs notably better, highlighting its importance for unsupervised tasks. Due to quantization, the performance drop in PTQ is further compensated by QAT, which yields at par performance with the original 32-bit Floating point in two of the models considered.
Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
May 10, 2024



Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the "cross-class interference" problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.
Source Printer Identification using Printer Specific Pooling of Letter Descriptors
Sep 23, 2021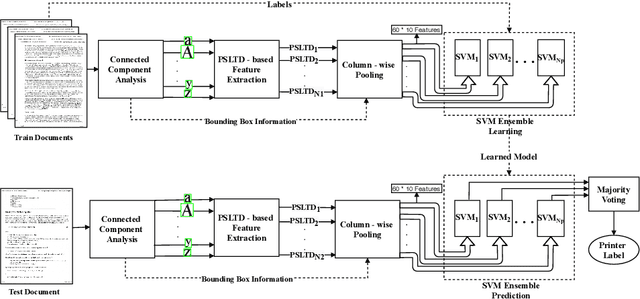
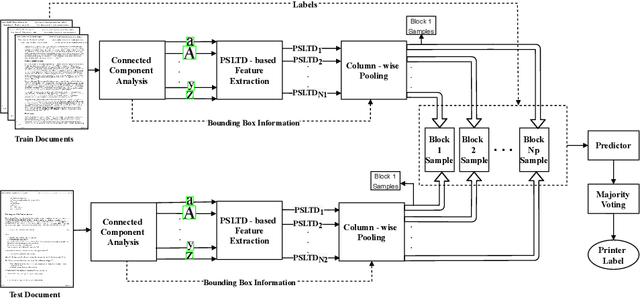
The digital revolution has replaced the use of printed documents with their digital counterparts. However, many applications require the use of both due to several factors, including challenges of digital security, installation costs, ease of use, and lack of digital expertise. Technological developments in the digital domain have also resulted in the easy availability of high-quality scanners, printers, and image editing software at lower prices. Miscreants leverage such technology to develop forged documents that may go undetected in vast volumes of printed documents. These developments mandate the research on creating fast and accurate digital systems for source printer identification of printed documents. We extensively analyze and propose a printer-specific pooling that improves the performance of printer-specific local texture descriptor on two datasets. The proposed pooling performs well using a simple correlation-based prediction instead of a complex machine learning-based classifier achieving improved performance under cross-font scenarios. The proposed system achieves an average classification accuracy of 93.5%, 94.3%, and 60.3% on documents printed in Arial, Times New Roman, and Comic Sans font types respectively, when documents printed in only Cambria font are available for training.
Empirical Evaluation of PRNU Fingerprint Variation for Mismatched Imaging Pipelines
Apr 04, 2020
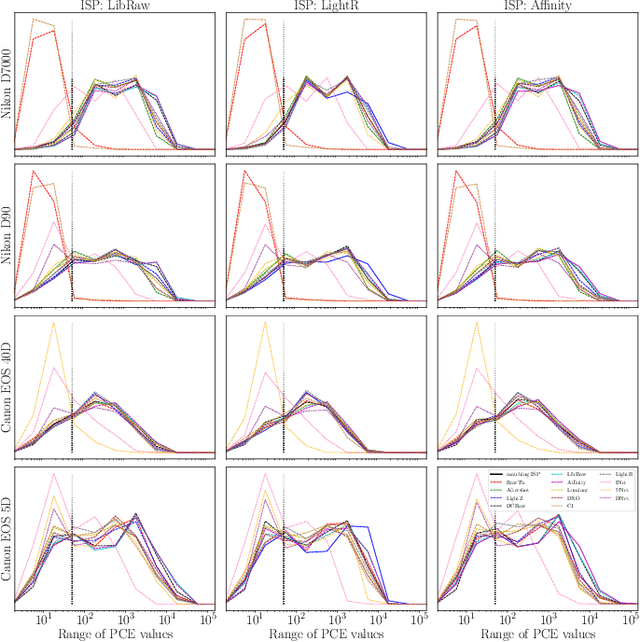
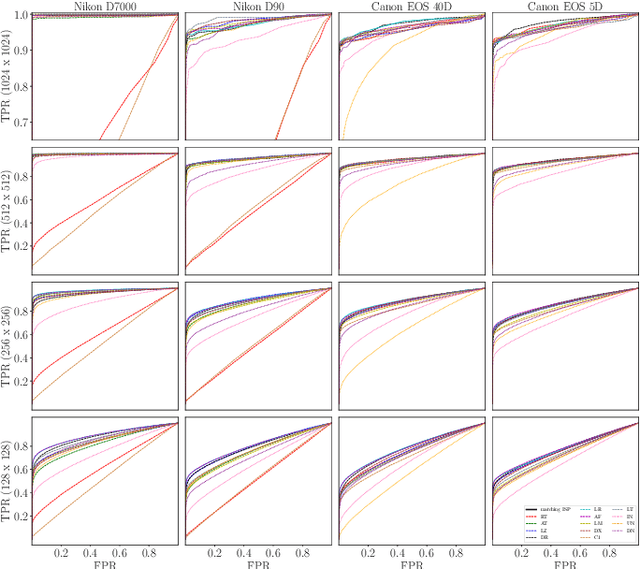

We assess the variability of PRNU-based camera fingerprints with mismatched imaging pipelines (e.g., different camera ISP or digital darkroom software). We show that camera fingerprints exhibit non-negligible variations in this setup, which may lead to unexpected degradation of detection statistics in real-world use-cases. We tested 13 different pipelines, including standard digital darkroom software and recent neural-networks. We observed that correlation between fingerprints from mismatched pipelines drops on average to 0.38 and the PCE detection statistic drops by over 40%. The degradation in error rates is the strongest for small patches commonly used in photo manipulation detection, and when neural networks are used for photo development. At a fixed 0.5% FPR setting, the TPR drops by 17 ppt (percentage points) for 128 px and 256 px patches.
Source Printer Identification from Document Images Acquired using Smartphone
Mar 27, 2020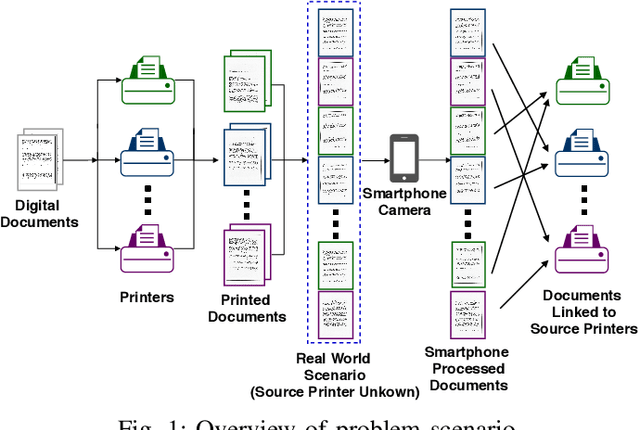


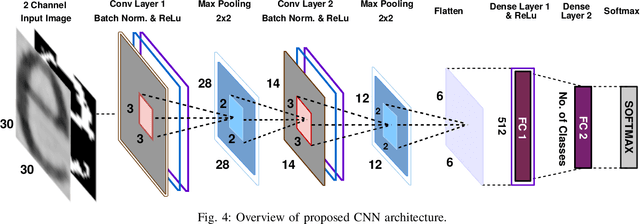
Vast volumes of printed documents continue to be used for various important as well as trivial applications. Such applications often rely on the information provided in the form of printed text documents whose integrity verification poses a challenge due to time constraints and lack of resources. Source printer identification provides essential information about the origin and integrity of a printed document in a fast and cost-effective manner. Even when fraudulent documents are identified, information about their origin can help stop future frauds. If a smartphone camera replaces scanner for the document acquisition process, document forensics would be more economical, user-friendly, and even faster in many applications where remote and distributed analysis is beneficial. Building on existing methods, we propose to learn a single CNN model from the fusion of letter images and their printer-specific noise residuals. In the absence of any publicly available dataset, we created a new dataset consisting of 2250 document images of text documents printed by eighteen printers and acquired by a smartphone camera at five acquisition settings. The proposed method achieves 98.42% document classification accuracy using images of letter 'e' under a 5x2 cross-validation approach. Further, when tested using about half a million letters of all types, it achieves 90.33% and 98.01% letter and document classification accuracies, respectively, thus highlighting the ability to learn a discriminative model without dependence on a single letter type. Also, classification accuracies are encouraging under various acquisition settings, including low illumination and change in angle between the document and camera planes.
First Steps Toward CNN based Source Classification of Document Images Shared Over Messaging App
Aug 17, 2018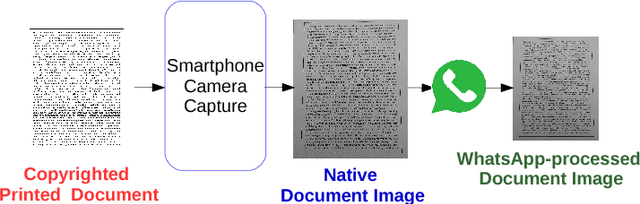
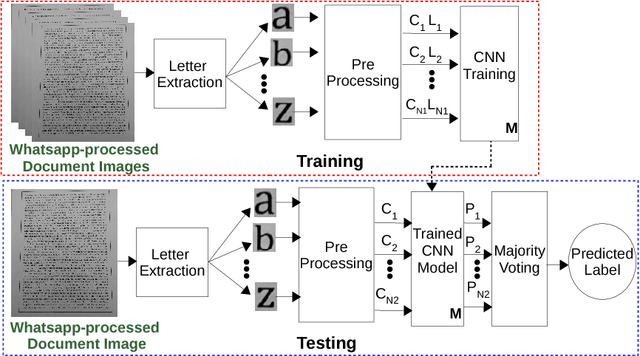

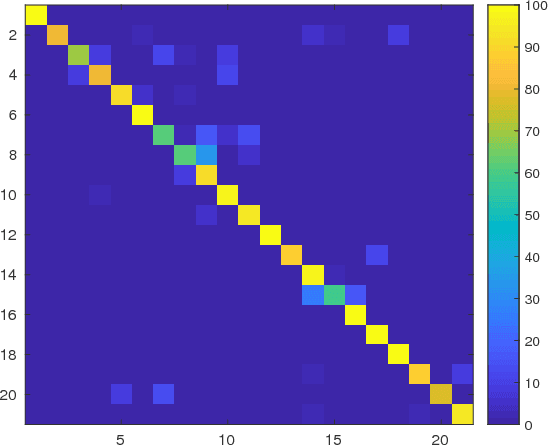
Knowledge of source smartphone corresponding to a document image can be helpful in a variety of applications including copyright infringement, ownership attribution, leak identification and usage restriction. In this letter, we investigate a convolutional neural network-based approach to solve source smartphone identification problem for printed text documents which have been captured by smartphone cameras and shared over messaging platform. In absence of any publicly available dataset addressing this problem, we introduce a new image dataset consisting of 315 images of documents printed in three different fonts, captured using 21 smartphones and shared over WhatsApp. Experiments conducted on this dataset demonstrate that, in all scenarios, the proposed system performs as well as or better than the state-of-the-art system based on handcrafted features and classification of letters extracted from document images. The new dataset and code of the proposed system will be made publicly available along with this letter's publication, presently they are submitted for review.
Single Classifier-based Passive System for Source Printer Classification using Local Texture Features
Jun 22, 2017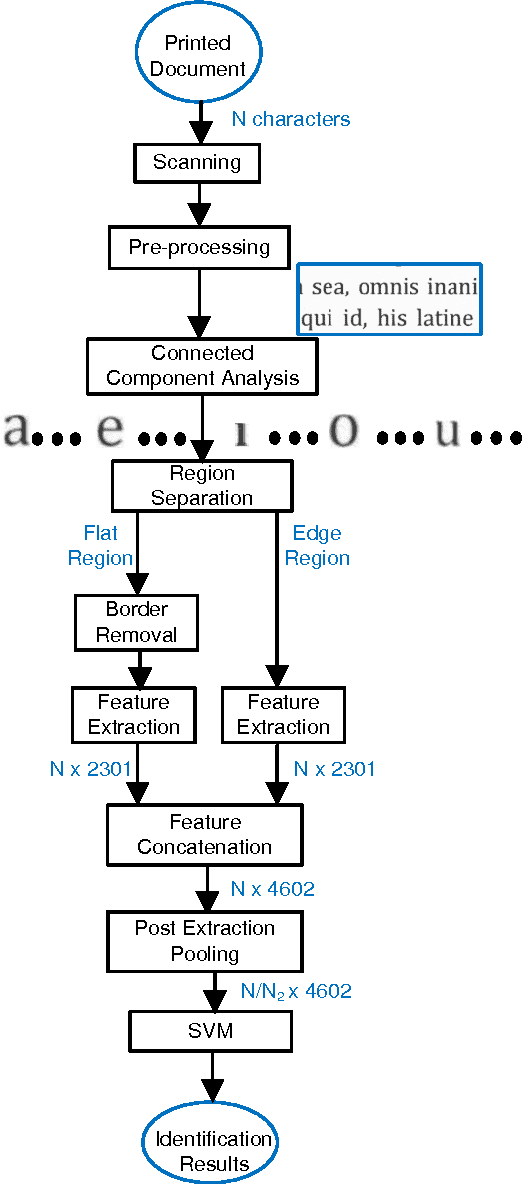


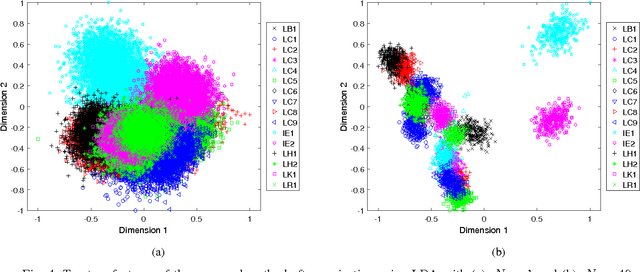
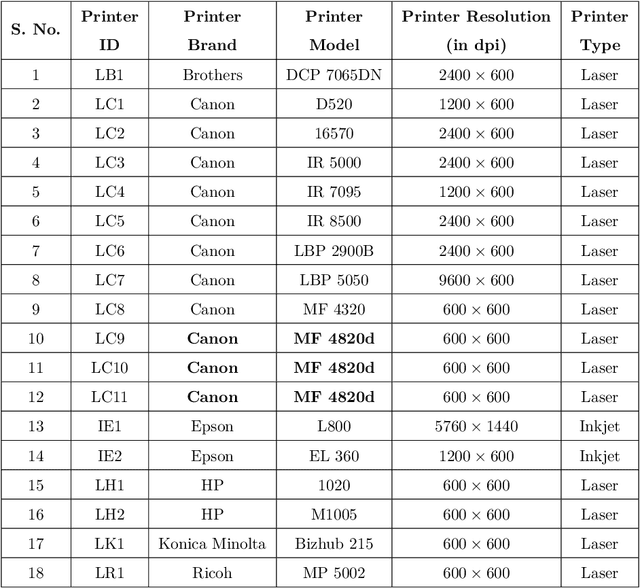
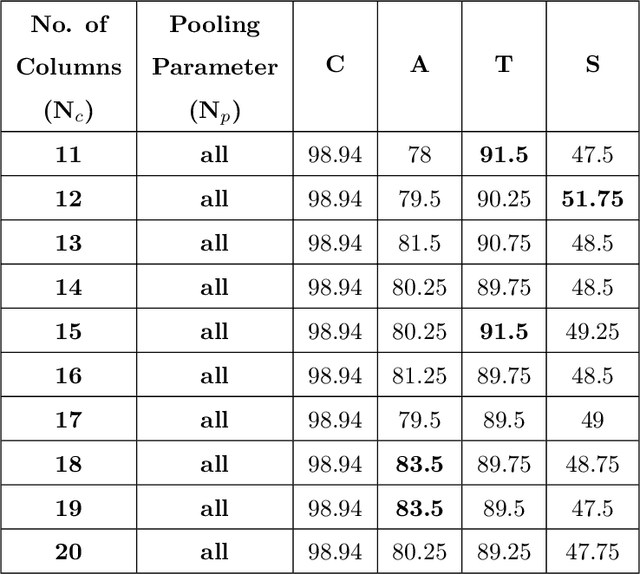
An important aspect of examining printed documents for potential forgeries and copyright infringement is the identification of source printer as it can be helpful for ascertaining the leak and detecting forged documents. This paper proposes a system for classification of source printer from scanned images of printed documents using all the printed letters simultaneously. This system uses local texture patterns based features and a single classifier for classifying all the printed letters. Letters are extracted from scanned images using connected component analysis followed by morphological filtering without the need of using an OCR. Each letter is sub-divided into a flat region and an edge region, and local tetra patterns are estimated separately for these two regions. A strategically constructed pooling technique is used to extract the final feature vectors. The proposed method has been tested on both a publicly available dataset of 10 printers and a new dataset of 18 printers scanned at a resolution of 600 dpi as well as 300 dpi printed in four different fonts. The results indicate shape independence property in the proposed method as using a single classifier it outperforms existing handcrafted feature-based methods and needs much smaller number of training pages by using all the printed letters.
Passive Classification of Source Printer using Text-line-level Geometric Distortion Signatures from Scanned Images of Printed Documents
Jun 20, 2017
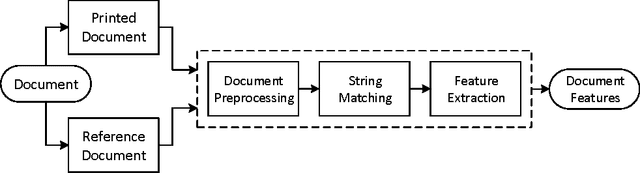
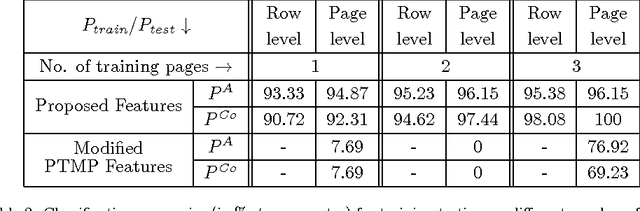

In this digital era, one thing that still holds the convention is a printed archive. Printed documents find their use in many critical domains such as contract papers, legal tenders and proof of identity documents. As more advanced printing, scanning and image editing techniques are becoming available, forgeries on these legal tenders pose a serious threat. Ability to easily and reliably identify source printer of a printed document can help a lot in reducing this menace. During printing procedure, printer hardware introduces certain distortions in printed characters' locations and shapes which are invisible to naked eyes. These distortions are referred as geometric distortions, their profile (or signature) is generally unique for each printer and can be used for printer classification purpose. This paper proposes a set of features for characterizing text-line-level geometric distortions, referred as geometric distortion signatures and presents a novel system to use them for identification of the origin of a printed document. Detailed experiments performed on a set of thirteen printers demonstrate that the proposed system achieves state of the art performance and gives much higher accuracy under small training size constraint. For four training and six test pages of three different fonts, the proposed method gives 99\% classification accuracy.