 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Printer Identification from Document Images Acquired using Smartphone
Mar 27, 2020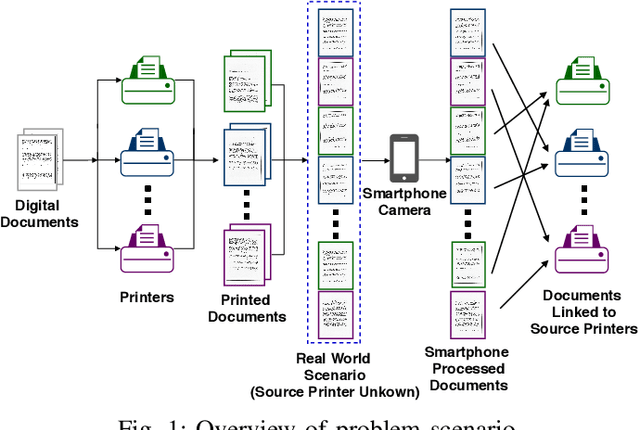


Vast volumes of printed documents continue to be used for various important as well as trivial applications. Such applications often rely on the information provided in the form of printed text documents whose integrity verification poses a challenge due to time constraints and lack of resources. Source printer identification provides essential information about the origin and integrity of a printed document in a fast and cost-effective manner. Even when fraudulent documents are identified, information about their origin can help stop future frauds. If a smartphone camera replaces scanner for the document acquisition process, document forensics would be more economical, user-friendly, and even faster in many applications where remote and distributed analysis is beneficial. Building on existing methods, we propose to learn a single CNN model from the fusion of letter images and their printer-specific noise residuals. In the absence of any publicly available dataset, we created a new dataset consisting of 2250 document images of text documents printed by eighteen printers and acquired by a smartphone camera at five acquisition settings. The proposed method achieves 98.42% document classification accuracy using images of letter 'e' under a 5x2 cross-validation approach. Further, when tested using about half a million letters of all types, it achieves 90.33% and 98.01% letter and document classification accuracies, respectively, thus highlighting the ability to learn a discriminative model without dependence on a single letter type. Also, classification accuracies are encouraging under various acquisition settings, including low illumination and change in angle between the document and camera planes.
First Steps Toward CNN based Source Classification of Document Images Shared Over Messaging App
Aug 17, 2018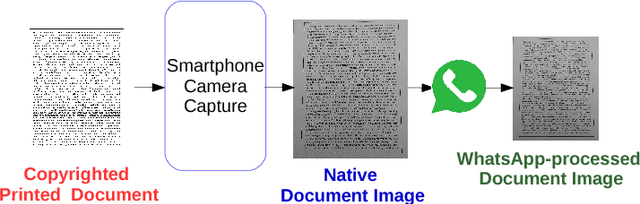
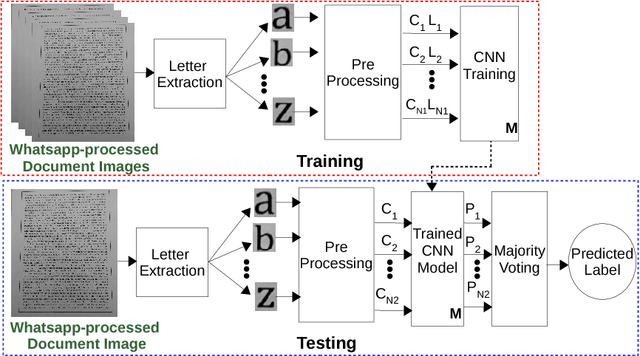

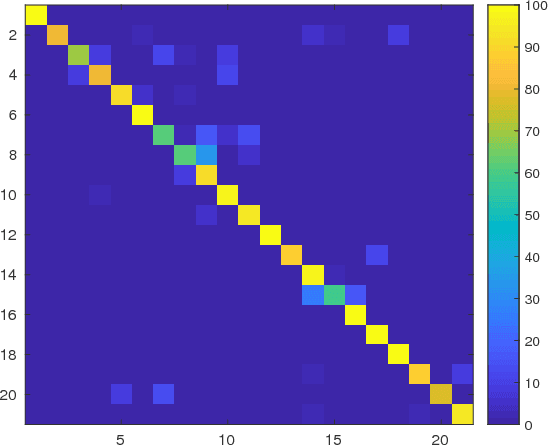
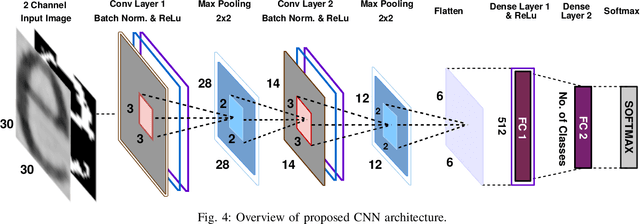
Knowledge of source smartphone corresponding to a document image can be helpful in a variety of applications including copyright infringement, ownership attribution, leak identification and usage restriction. In this letter, we investigate a convolutional neural network-based approach to solve source smartphone identification problem for printed text documents which have been captured by smartphone cameras and shared over messaging platform. In absence of any publicly available dataset addressing this problem, we introduce a new image dataset consisting of 315 images of documents printed in three different fonts, captured using 21 smartphones and shared over WhatsApp. Experiments conducted on this dataset demonstrate that, in all scenarios, the proposed system performs as well as or better than the state-of-the-art system based on handcrafted features and classification of letters extracted from document images. The new dataset and code of the proposed system will be made publicly available along with this letter's publication, presently they are submitted for review.