 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Steps Toward CNN based Source Classification of Document Images Shared Over Messaging App
Paper and Code
Aug 17, 2018
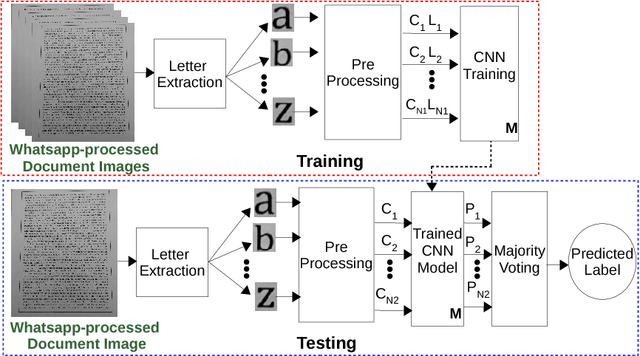

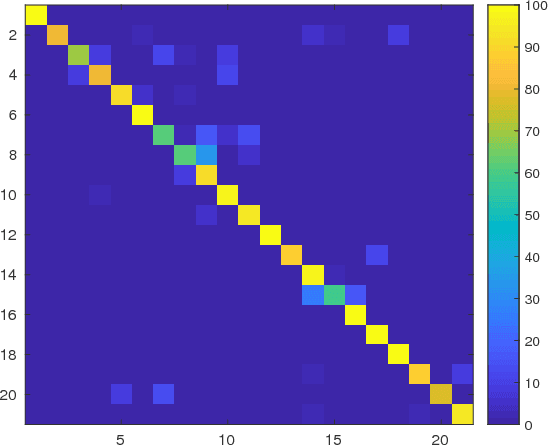
Knowledge of source smartphone corresponding to a document image can be helpful in a variety of applications including copyright infringement, ownership attribution, leak identification and usage restriction. In this letter, we investigate a convolutional neural network-based approach to solve source smartphone identification problem for printed text documents which have been captured by smartphone cameras and shared over messaging platform. In absence of any publicly available dataset addressing this problem, we introduce a new image dataset consisting of 315 images of documents printed in three different fonts, captured using 21 smartphones and shared over WhatsApp. Experiments conducted on this dataset demonstrate that, in all scenarios, the proposed system performs as well as or better than the state-of-the-art system based on handcrafted features and classification of letters extracted from document images. The new dataset and code of the proposed system will be made publicly available along with this letter's publication, presently they are submitted for review.