 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Green AI-Native Networks: Evaluation of Neural Circuit Policy for Estimating Energy Consumption of Base Stations
Apr 03, 2025



Optimization of radio hardware and AI-based network management software yield significant energy savings in radio access networks. The execution of underlying Machine Learning (ML) models, which enable energy savings through recommended actions, may require additional compute and energy, highlighting the opportunity to explore and adopt accurate and energy-efficient ML technologies. This work evaluates the novel use of sparsely structured Neural Circuit Policies (NCPs) in a use case to estimate the energy consumption of base stations. Sparsity in ML models yields reduced memory, computation and energy demand, hence facilitating a low-cost and scalable solution. We also evaluate the generalization capability of NCPs in comparison to traditional and widely used ML models such as Long Short Term Memory (LSTM), via quantifying their sensitivity to varying model hyper-parameters (HPs). NCPs demonstrated a clear reduction in computational overhead and energy consumption. Moreover, results indicated that the NCPs are robust to varying HPs such as number of epochs and neurons in each layer, making them a suitable option to ease model management and to reduce energy consumption in Machine Learning Operations (MLOps) in telecommunications.
Arbitrary Scale Super-Resolution Assisted Lunar Crater Detection in Satellite Images
Feb 07, 2024Craters are one of the most studied planetary features used for different scientific analyses, such as estimation of surface age and surface processes. Satellite images utilized for crater detection often have low resolution (LR) due to hardware constraints and transmission time. Super-resolution (SR) is a practical and cost-effective solution; however, most SR approaches work on fixed integer scale factors, i.e., a single model can generate images of a specific resolution. In practical applications, SR on multiple scales provides various levels of detail, but training for each scale is resource-intensive. Therefore, this paper proposes a system for crater detection assisted with an arbitrary scale super-resolution approach (i.e., a single model can be used for multiple scale factors) for the lunar surface. Our work is composed of two subsystems. The first sub-system employs an arbitrary scale SR approach to generate super-resolved images of multiple resolutions. Subsequently, the second sub-system passes super-resolved images of multiple resolutions to a deep learning-based crater detection framework for identifying craters on the lunar surface. Employed arbitrary scale SR approach is based on a combination of convolution and transformer modules. For the crater detection sub-system, we utilize the Mask-RCNN framework. Using SR images of multiple resolutions, the proposed system detects 13.47% more craters from the ground truth than the craters detected using only the LR images. Further, in complex crater settings, specifically in overlapping and degraded craters, 11.84% and 15.01% more craters are detected as compared to the crater detection networks using only the LR images. The proposed system also leads to better localization performance, 3.19% IoU increment compared to the LR images
Deep Learning based Systems for Crater Detection: A Review
Sep 28, 2023Craters are one of the most prominent features on planetary surfaces, used in applications such as age estimation, hazard detection, and spacecraft navigation. Crater detection is a challenging problem due to various aspects, including complex crater characteristics such as varying sizes and shapes, data resolution, and planetary data types. Similar to other computer vision tasks, deep learning-based approaches have significantly impacted research on crater detection in recent years. This survey aims to assist researchers in this field by examining the development of deep learning-based crater detection algorithms (CDAs). The review includes over 140 research works covering diverse crater detection approaches, including planetary data, craters database, and evaluation metrics. To be specific, we discuss the challenges in crater detection due to the complex properties of the craters and survey the DL-based CDAs by categorizing them into three parts: (a) semantic segmentation-based, (b) object detection-based, and (c) classification-based. Additionally, we have conducted training and testing of all the semantic segmentation-based CDAs on a common dataset to evaluate the effectiveness of each architecture for crater detection and its potential applications. Finally, we have provided recommendations for potential future works.
Automatic Crater Shape Retrieval using Unsupervised and Semi-Supervised Systems
Nov 03, 2022Impact craters are formed due to continuous impacts on the surface of planetary bodies. Most recent deep learning-based crater detection methods treat craters as circular shapes, and less attention is paid to extracting the exact shapes of craters. Extracting precise shapes of the craters can be helpful for many advanced analyses, such as crater formation. This paper proposes a combination of unsupervised non-deep learning and semi-supervised deep learning approach to accurately extract shapes of the craters and detect missing craters from the existing catalog. In unsupervised non-deep learning, we have proposed an adaptive rim extraction algorithm to extract craters' shapes. In this adaptive rim extraction algorithm, we utilized the elevation profiles of DEMs and applied morphological operation on DEM-derived slopes to extract craters' shapes. The extracted shapes of the craters are used in semi-supervised deep learning to get the locations, size, and refined shapes. Further, the extracted shapes of the craters are utilized to improve the estimate of the craters' diameter, depth, and other morphological factors. The craters' shape, estimated diameter, and depth with other morphological factors will be publicly available.
In-Orbit Lunar Satellite Image Super Resolution for Selective Data Transmission
Oct 19, 2021Rapid technological advancements have tremendously increased the data acquisition capabilities of remote sensing satellites. However, the data utilization efficiency in satellite missions is very low. This growing data also escalates the cost required for data downlink transmission and post-processing. Selective data transmission based on in-orbit inferences will address these issues to a great extent. Therefore, to decrease the cost of the satellite mission, we propose a novel system design for selective data transmission, based on in-orbit inferences. As the resolution of images plays a critical role in making precise inferences, we also include in-orbit super-resolution (SR) in the system design. We introduce a new image reconstruction technique and a unique loss function to enable the execution of the SR model on low-power devices suitable for satellite environments. We present a residual dense non-local attention network (RDNLA) that provides enhanced super-resolution outputs to improve the SR performance. SR experiments on Kaguya digital ortho maps (DOMs) demonstrate that the proposed SR algorithm outperforms the residual dense network (RDN) in terms of PSNR and block-sensitive PSNR by a margin of +0.1 dB and +0.19 dB, respectively. The proposed SR system consumes 48% less memory and 67% less peak instantaneous power than the standard SR model, RDN, making it more suitable for execution on a low-powered device platform.
Source Printer Identification using Printer Specific Pooling of Letter Descriptors
Sep 23, 2021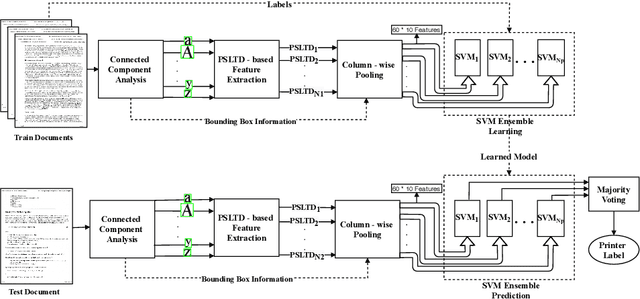
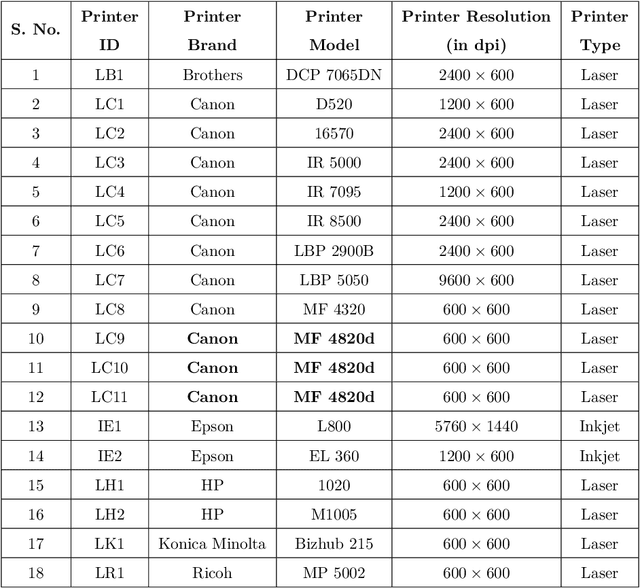
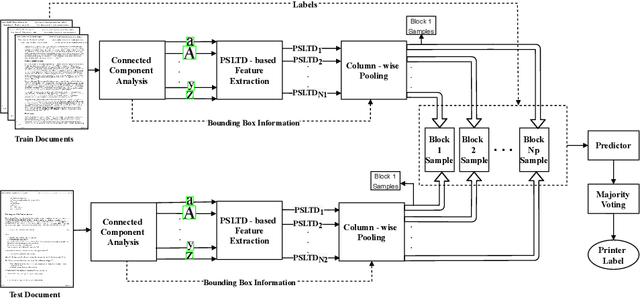
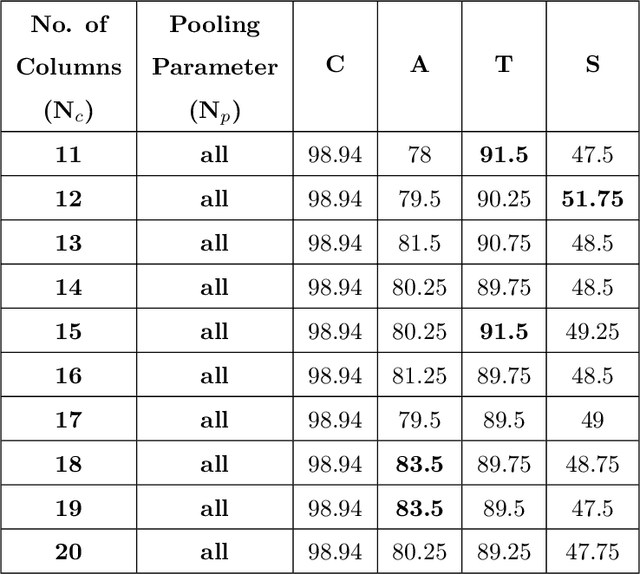
The digital revolution has replaced the use of printed documents with their digital counterparts. However, many applications require the use of both due to several factors, including challenges of digital security, installation costs, ease of use, and lack of digital expertise. Technological developments in the digital domain have also resulted in the easy availability of high-quality scanners, printers, and image editing software at lower prices. Miscreants leverage such technology to develop forged documents that may go undetected in vast volumes of printed documents. These developments mandate the research on creating fast and accurate digital systems for source printer identification of printed documents. We extensively analyze and propose a printer-specific pooling that improves the performance of printer-specific local texture descriptor on two datasets. The proposed pooling performs well using a simple correlation-based prediction instead of a complex machine learning-based classifier achieving improved performance under cross-font scenarios. The proposed system achieves an average classification accuracy of 93.5%, 94.3%, and 60.3% on documents printed in Arial, Times New Roman, and Comic Sans font types respectively, when documents printed in only Cambria font are available for training.
Q-matrix Unaware Double JPEG Detection using DCT-Domain Deep BiLSTM Network
Apr 10, 2021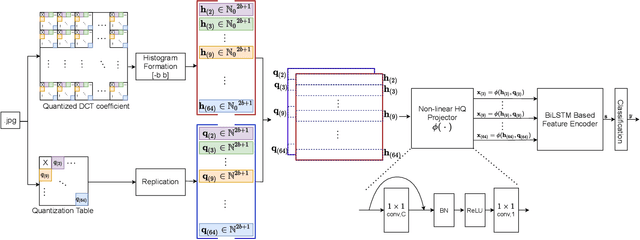
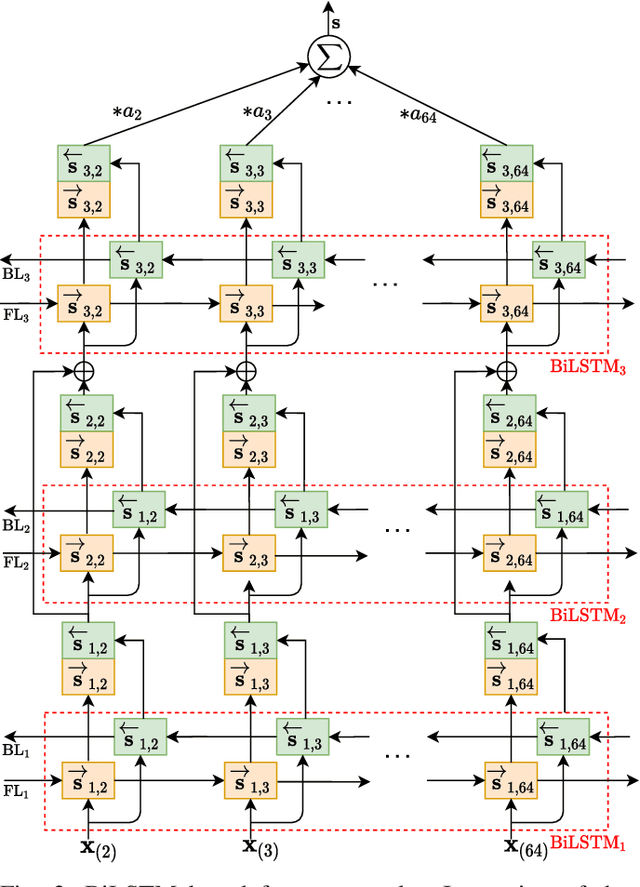
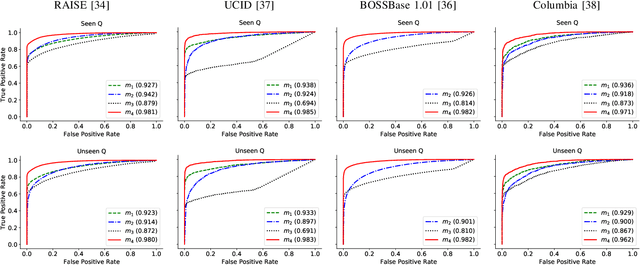
The double JPEG compression detection has received much attention in recent years due to its applicability as a forensic tool for the most widely used JPEG file format. Existing state-of-the-art CNN-based methods either use histograms of all the frequencies or rely on heuristics to select histograms of specific low frequencies to classify single and double compressed images. However, even amidst lower frequencies of double compressed images/patches, histograms of all the frequencies do not have distinguishable features to separate them from single compressed images. This paper directly extracts the quantized DCT coefficients from the JPEG images without decompressing them in the pixel domain, obtains all AC frequencies' histograms, uses a module based on $1\times 1$ depth-wise convolutions to learn the inherent relation between each histogram and corresponding q-factor, and utilizes a tailor-made BiLSTM network for selectively encoding these feature vector sequences. The proposed system outperforms several baseline methods on a relatively large and diverse publicly available dataset of single and double compressed patches. Another essential aspect of any single vs. double JPEG compression detection system is handling the scenario where test patches are compressed with entirely different quantization matrices (Q-matrices) than those used while training; different camera manufacturers and image processing software generally utilize their customized quantization matrices. A set of extensive experiments shows that the proposed system trained on a single dataset generalizes well on other datasets compressed with completely unseen quantization matrices and outperforms the state-of-the-art methods in both seen and unseen quantization matrices scenarios.
Automated Crater Detection from Co-registered Optical Images, Elevation Maps and Slope Maps using Deep Learning
Dec 30, 2020Impact craters are formed as a result of continuous impacts on the surface of planetary bodies. This paper proposes a novel way of simultaneously utilizing optical images, digital elevation maps (DEMs), and slope maps for automatic crater detection on the lunar surface. Mask R-CNN, tuned for the crater detection task, is utilized in this paper. Two catalogs, namely, Head-LROC and Robbins, are used for the performance evaluation. Exhaustive analysis of the detection results on the lunar surface has been performed with respect to both Head-LROC and Robbins catalog. With the Head-LROC catalog, which has relatively strict crater markings and larger possibility of missing craters, recall value of 94.28\% has been obtained as compared to 88.03\% for the baseline method. However, with respect to a manually marked exhaustive crater catalog based on relatively liberal marking, significant precision and recall values are obtained for different crater size ranges. The generalization capability of the proposed method in terms of crater detection on a different terrain with different input data type is also evaluated. We show that the proposed model trained on the lunar surface with optical images, DEMs and corresponding slope maps can be used to detect craters on the Martian surface even with entirely different input data type, such as thermal IR images from the Martian surface.
Empirical Evaluation of PRNU Fingerprint Variation for Mismatched Imaging Pipelines
Apr 04, 2020
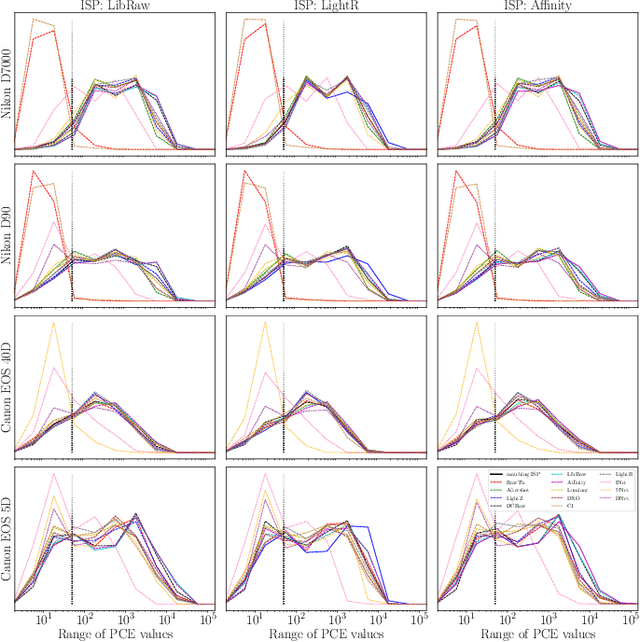
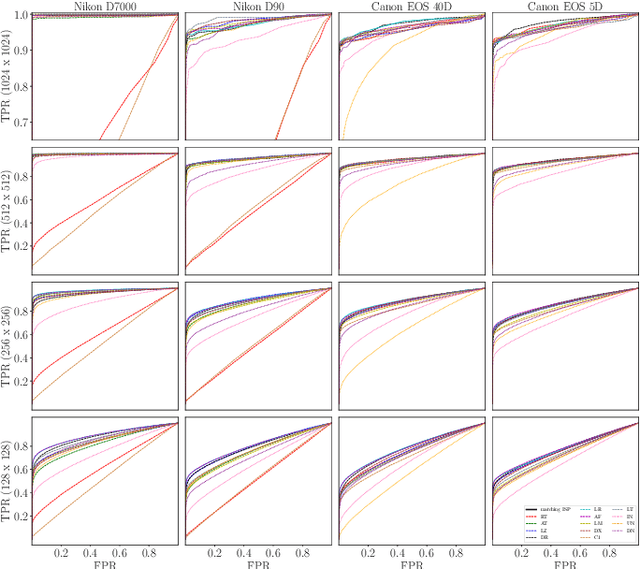

We assess the variability of PRNU-based camera fingerprints with mismatched imaging pipelines (e.g., different camera ISP or digital darkroom software). We show that camera fingerprints exhibit non-negligible variations in this setup, which may lead to unexpected degradation of detection statistics in real-world use-cases. We tested 13 different pipelines, including standard digital darkroom software and recent neural-networks. We observed that correlation between fingerprints from mismatched pipelines drops on average to 0.38 and the PCE detection statistic drops by over 40%. The degradation in error rates is the strongest for small patches commonly used in photo manipulation detection, and when neural networks are used for photo development. At a fixed 0.5% FPR setting, the TPR drops by 17 ppt (percentage points) for 128 px and 256 px patches.
Source Printer Identification from Document Images Acquired using Smartphone
Mar 27, 2020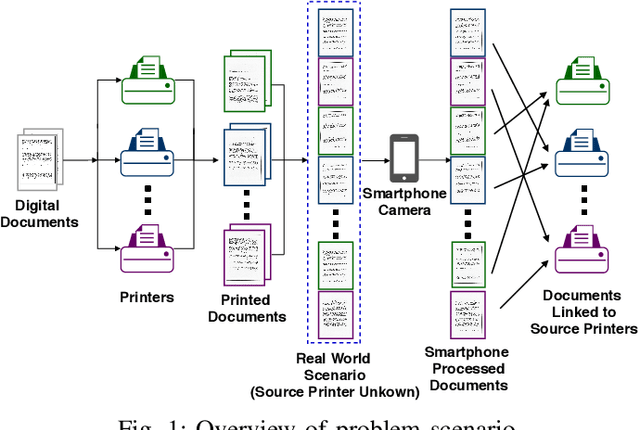


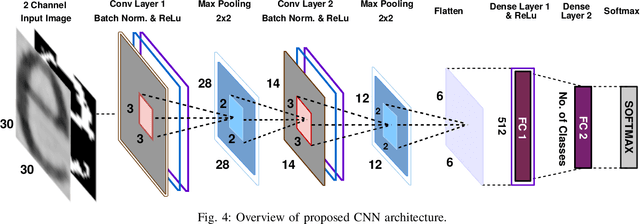
Vast volumes of printed documents continue to be used for various important as well as trivial applications. Such applications often rely on the information provided in the form of printed text documents whose integrity verification poses a challenge due to time constraints and lack of resources. Source printer identification provides essential information about the origin and integrity of a printed document in a fast and cost-effective manner. Even when fraudulent documents are identified, information about their origin can help stop future frauds. If a smartphone camera replaces scanner for the document acquisition process, document forensics would be more economical, user-friendly, and even faster in many applications where remote and distributed analysis is beneficial. Building on existing methods, we propose to learn a single CNN model from the fusion of letter images and their printer-specific noise residuals. In the absence of any publicly available dataset, we created a new dataset consisting of 2250 document images of text documents printed by eighteen printers and acquired by a smartphone camera at five acquisition settings. The proposed method achieves 98.42% document classification accuracy using images of letter 'e' under a 5x2 cross-validation approach. Further, when tested using about half a million letters of all types, it achieves 90.33% and 98.01% letter and document classification accuracies, respectively, thus highlighting the ability to learn a discriminative model without dependence on a single letter type. Also, classification accuracies are encouraging under various acquisition settings, including low illumination and change in angle between the document and camera planes.