 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSememeLM: A Sememe Knowledge Enhanced Method for Long-tail Relation Representation
Jun 13, 2024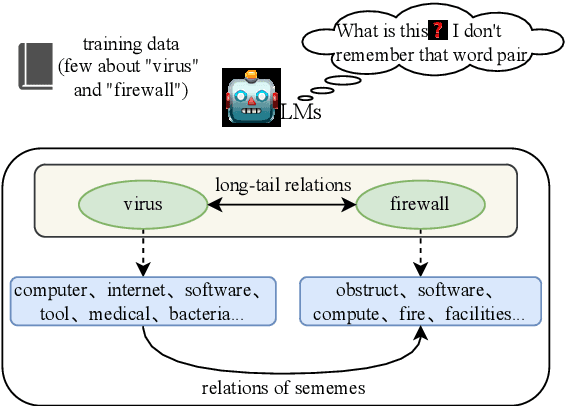

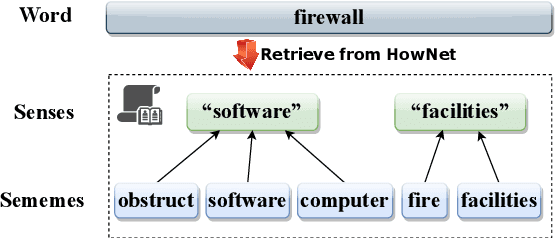
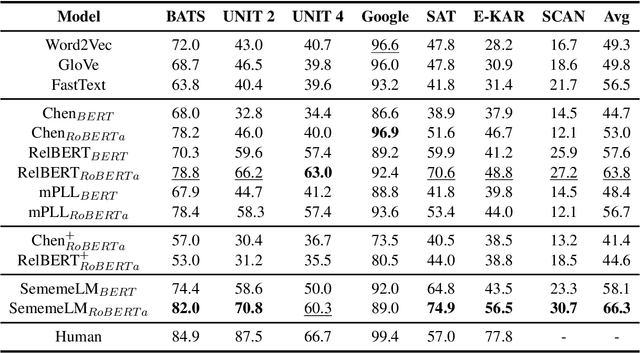
Recognizing relations between two words is a fundamental task with the broad applications. Different from extracting relations from text, it is difficult to identify relations among words without their contexts. Especially for long-tail relations, it becomes more difficult due to inadequate semantic features. Existing approaches based on language models (LMs) utilize rich knowledge of LMs to enhance the semantic features of relations. However, they capture uncommon relations while overlooking less frequent but meaningful ones since knowledge of LMs seriously relies on trained data where often represents common relations. On the other hand, long-tail relations are often uncommon in training data. It is interesting but not trivial to use external knowledge to enrich LMs due to collecting corpus containing long-tail relationships is hardly feasible. In this paper, we propose a sememe knowledge enhanced method (SememeLM) to enhance the representation of long-tail relations, in which sememes can break the contextual constraints between wors. Firstly, we present a sememe relation graph and propose a graph encoding method. Moreover, since external knowledge base possibly consisting of massive irrelevant knowledge, the noise is introduced. We propose a consistency alignment module, which aligns the introduced knowledge with LMs, reduces the noise and integrates the knowledge into the language model. Finally, we conducted experiments on word analogy datasets, which evaluates the ability to distinguish relation representations subtle differences, including long-tail relations. Extensive experiments show that our approach outperforms some state-of-the-art methods.
Relative Counterfactual Contrastive Learning for Mitigating Pretrained Stance Bias in Stance Detection
May 16, 2024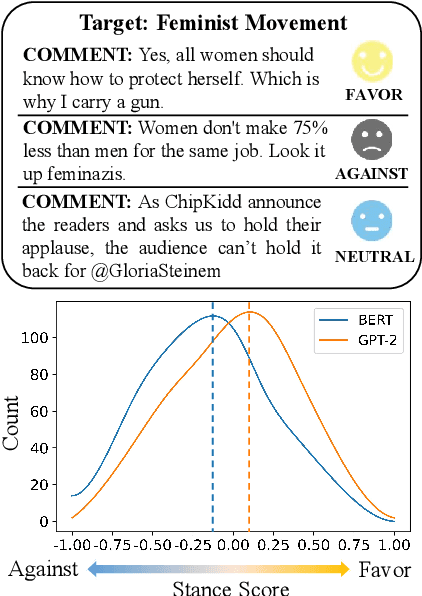
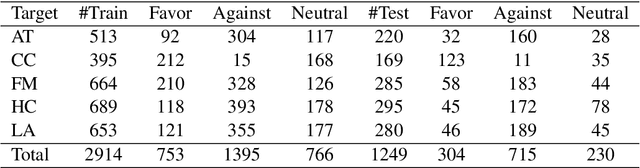
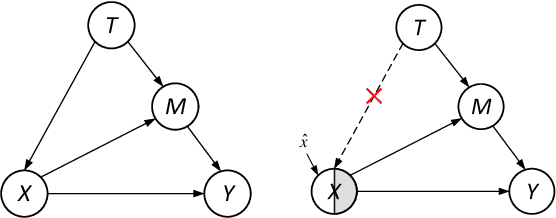
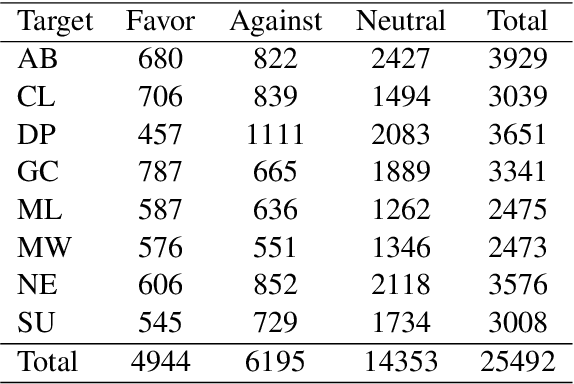
Stance detection classifies stance relations (namely, Favor, Against, or Neither) between comments and targets. Pretrained language models (PLMs) are widely used to mine the stance relation to improve the performance of stance detection through pretrained knowledge. However, PLMs also embed ``bad'' pretrained knowledge concerning stance into the extracted stance relation semantics, resulting in pretrained stance bias. It is not trivial to measure pretrained stance bias due to its weak quantifiability. In this paper, we propose Relative Counterfactual Contrastive Learning (RCCL), in which pretrained stance bias is mitigated as relative stance bias instead of absolute stance bias to overtake the difficulty of measuring bias. Firstly, we present a new structural causal model for characterizing complicated relationships among context, PLMs and stance relations to locate pretrained stance bias. Then, based on masked language model prediction, we present a target-aware relative stance sample generation method for obtaining relative bias. Finally, we use contrastive learning based on counterfactual theory to mitigate pretrained stance bias and preserve context stance relation. Experiments show that the proposed method is superior to stance detection and debiasing baselines.
Function-words Enhanced Attention Networks for Few-Shot Inverse Relation Classification
Apr 26, 2022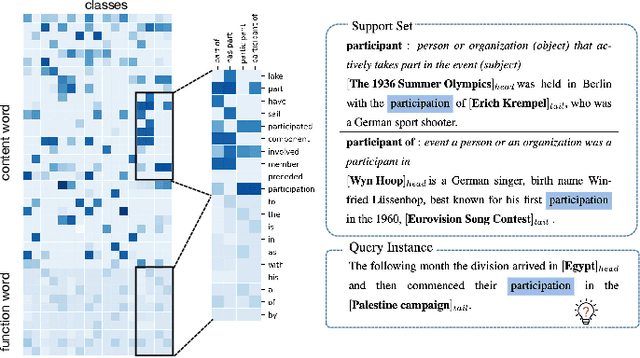
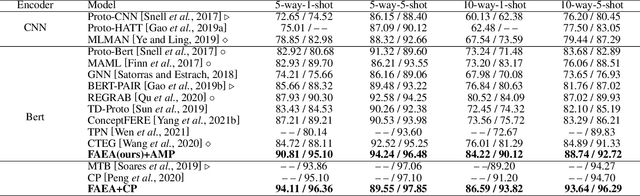
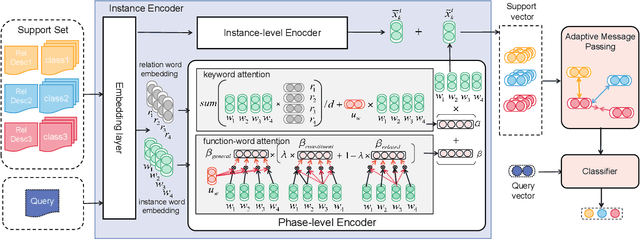
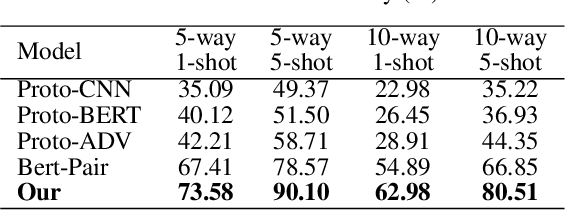
The relation classification is to identify semantic relations between two entities in a given text. While existing models perform well for classifying inverse relations with large datasets, their performance is significantly reduced for few-shot learning. In this paper, we propose a function words adaptively enhanced attention framework (FAEA) for few-shot inverse relation classification, in which a hybrid attention model is designed to attend class-related function words based on meta-learning. As the involvement of function words brings in significant intra-class redundancy, an adaptive message passing mechanism is introduced to capture and transfer inter-class differences.We mathematically analyze the negative impact of function words from dot-product measurement, which explains why message passing mechanism effectively reduces the impact. Our experimental results show that FAEA outperforms strong baselines, especially the inverse relation accuracy is improved by 14.33% under 1-shot setting in FewRel1.0.
Learning Disentangled Semantic Representations for Zero-Shot Cross-Lingual Transfer in Multilingual Machine Reading Comprehension
Apr 03, 2022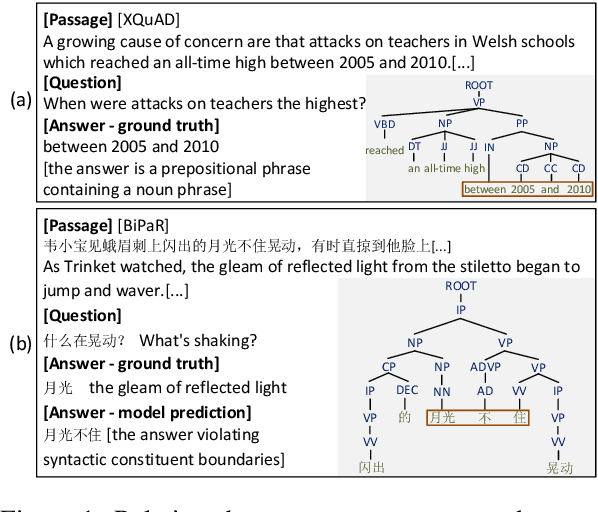
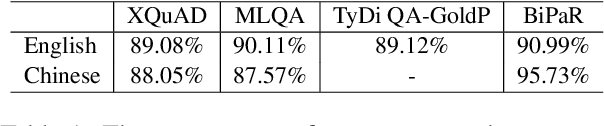
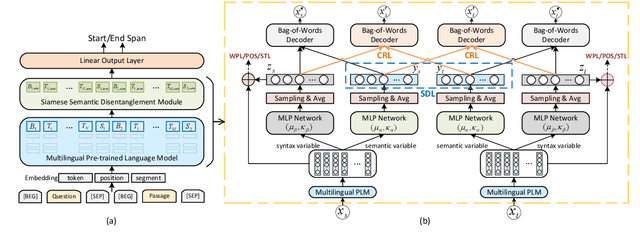
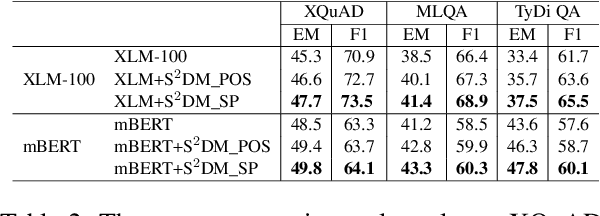
Multilingual pre-trained models are able to zero-shot transfer knowledge from rich-resource to low-resource languages in machine reading comprehension (MRC). However, inherent linguistic discrepancies in different languages could make answer spans predicted by zero-shot transfer violate syntactic constraints of the target language. In this paper, we propose a novel multilingual MRC framework equipped with a Siamese Semantic Disentanglement Model (SSDM) to disassociate semantics from syntax in representations learned by multilingual pre-trained models. To explicitly transfer only semantic knowledge to the target language, we propose two groups of losses tailored for semantic and syntactic encoding and disentanglement. Experimental results on three multilingual MRC datasets (i.e., XQuAD, MLQA, and TyDi QA) demonstrate the effectiveness of our proposed approach over models based on mBERT and XLM-100. Code is available at:https://github.com/wulinjuan/SSDM_MRC.