 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSememeLM: A Sememe Knowledge Enhanced Method for Long-tail Relation Representation
Paper and Code
Jun 13, 2024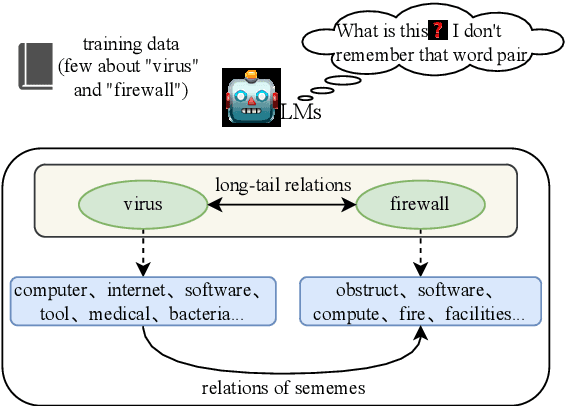

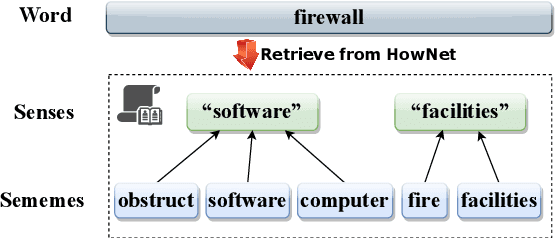
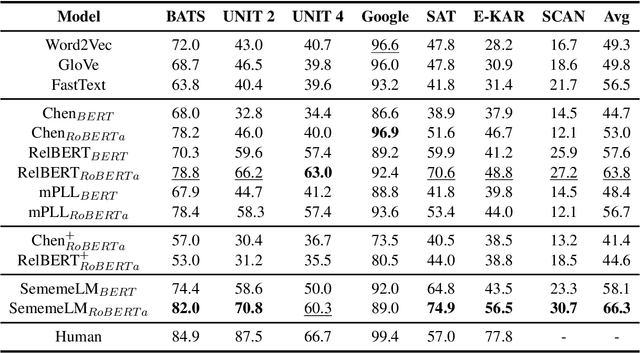
Recognizing relations between two words is a fundamental task with the broad applications. Different from extracting relations from text, it is difficult to identify relations among words without their contexts. Especially for long-tail relations, it becomes more difficult due to inadequate semantic features. Existing approaches based on language models (LMs) utilize rich knowledge of LMs to enhance the semantic features of relations. However, they capture uncommon relations while overlooking less frequent but meaningful ones since knowledge of LMs seriously relies on trained data where often represents common relations. On the other hand, long-tail relations are often uncommon in training data. It is interesting but not trivial to use external knowledge to enrich LMs due to collecting corpus containing long-tail relationships is hardly feasible. In this paper, we propose a sememe knowledge enhanced method (SememeLM) to enhance the representation of long-tail relations, in which sememes can break the contextual constraints between wors. Firstly, we present a sememe relation graph and propose a graph encoding method. Moreover, since external knowledge base possibly consisting of massive irrelevant knowledge, the noise is introduced. We propose a consistency alignment module, which aligns the introduced knowledge with LMs, reduces the noise and integrates the knowledge into the language model. Finally, we conducted experiments on word analogy datasets, which evaluates the ability to distinguish relation representations subtle differences, including long-tail relations. Extensive experiments show that our approach outperforms some state-of-the-art methods.