 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Analysis of Gradient Descent for Shallow Transformers
Jan 23, 2026Understanding why Transformers perform so well remains challenging due to their non-convex optimization landscape. In this work, we analyze a shallow Transformer with $m$ independent heads trained by projected gradient descent in the kernel regime. Our analysis reveals two main findings: (i) the width required for nonasymptotic guarantees scales only logarithmically with the sample size $n$, and (ii) the optimization error is independent of the sequence length $T$. This contrasts sharply with recurrent architectures, where the optimization error can grow exponentially with $T$. The trade-off is memory: to keep the full context, the Transformer's memory requirement grows with the sequence length. We validate our theoretical results numerically in a teacher-student setting and confirm the predicted scaling laws for Transformers.
Non-Asymptotic Optimization and Generalization Bounds for Stochastic Gauss-Newton in Overparameterized Models
Nov 12, 2025An important question in deep learning is how higher-order optimization methods affect generalization. In this work, we analyze a stochastic Gauss-Newton (SGN) method with Levenberg-Marquardt damping and mini-batch sampling for training overparameterized deep neural networks with smooth activations in a regression setting. Our theoretical contributions are twofold. First, we establish finite-time convergence bounds via a variable-metric analysis in parameter space, with explicit dependencies on the batch size, network width and depth. Second, we derive non-asymptotic generalization bounds for SGN using uniform stability in the overparameterized regime, characterizing the impact of curvature, batch size, and overparameterization on generalization performance. Our theoretical results identify a favorable generalization regime for SGN in which a larger minimum eigenvalue of the Gauss-Newton matrix along the optimization path yields tighter stability bounds.
Gauss-Newton Dynamics for Neural Networks: A Riemannian Optimization Perspective
Dec 19, 2024
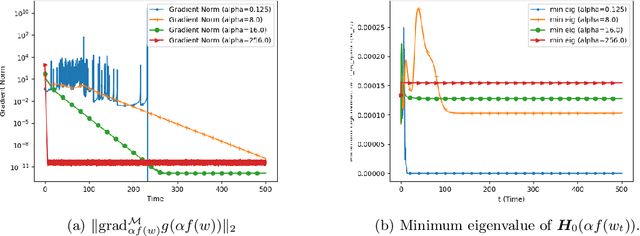
We analyze the convergence of Gauss-Newton dynamics for training neural networks with smooth activation functions. In the underparameterized regime, the Gauss-Newton gradient flow induces a Riemannian gradient flow on a low-dimensional, smooth, embedded submanifold of the Euclidean output space. Using tools from Riemannian optimization, we prove \emph{last-iterate} convergence of the Riemannian gradient flow to the optimal in-class predictor at an \emph{exponential rate} that is independent of the conditioning of the Gram matrix, \emph{without} requiring explicit regularization. We further characterize the critical impacts of the neural network scaling factor and the initialization on the convergence behavior. In the overparameterized regime, we show that the Levenberg-Marquardt dynamics with an appropriately chosen damping factor yields robustness to ill-conditioned kernels, analogous to the underparameterized regime. These findings demonstrate the potential of Gauss-Newton methods for efficiently optimizing neural networks, particularly in ill-conditioned problems where kernel and Gram matrices have small singular values.
Essentially Sharp Estimates on the Entropy Regularization Error in Discrete Discounted Markov Decision Processes
Jun 06, 2024We study the error introduced by entropy regularization of infinite-horizon discrete discounted Markov decision processes. We show that this error decreases exponentially in the inverse regularization strength both in a weighted KL-divergence and in value with a problem-specific exponent. We provide a lower bound matching our upper bound up to a polynomial factor. Our proof relies on the correspondence of the solutions of entropy-regularized Markov decision processes with gradient flows of the unregularized reward with respect to a Riemannian metric common in natural policy gradient methods. Further, this correspondence allows us to identify the limit of the gradient flow as the generalized maximum entropy optimal policy, thereby characterizing the implicit bias of the Kakade gradient flow which corresponds to a time-continuous version of the natural policy gradient method. We use this to show that for entropy-regularized natural policy gradient methods the overall error decays exponentially in the square root of the number of iterations improving existing sublinear guarantees.
Recurrent Natural Policy Gradient for POMDPs
May 28, 2024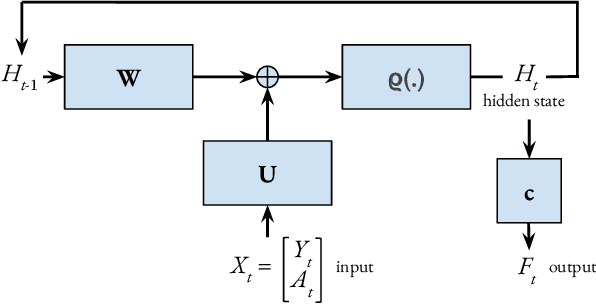
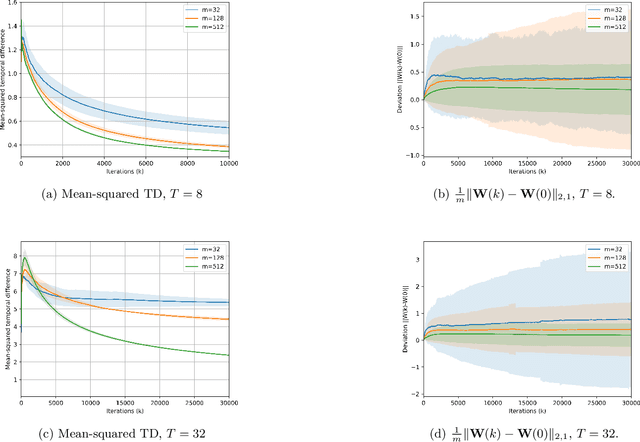
In this paper, we study a natural policy gradient method based on recurrent neural networks (RNNs) for partially-observable Markov decision processes, whereby RNNs are used for policy parameterization and policy evaluation to address curse of dimensionality in non-Markovian reinforcement learning. We present finite-time and finite-width analyses for both the critic (recurrent temporal difference learning), and correspondingly-operated recurrent natural policy gradient method in the near-initialization regime. Our analysis demonstrates the efficiency of RNNs for problems with short-term memory with explicit bounds on the required network widths and sample complexity, and points out the challenges in the case of long-term dependencies.
Convergence of Gradient Descent for Recurrent Neural Networks: A Nonasymptotic Analysis
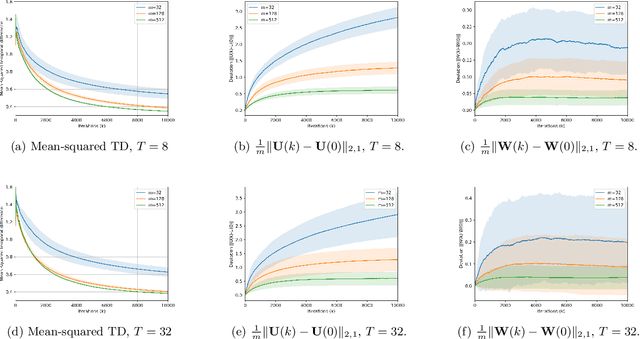
Feb 19, 2024We analyze recurrent neural networks trained with gradient descent in the supervised learning setting for dynamical systems, and prove that gradient descent can achieve optimality \emph{without} massive overparameterization. Our in-depth nonasymptotic analysis (i) provides sharp bounds on the network size $m$ and iteration complexity $\tau$ in terms of the sequence length $T$, sample size $n$ and ambient dimension $d$, and (ii) identifies the significant impact of long-term dependencies in the dynamical system on the convergence and network width bounds characterized by a cutoff point that depends on the Lipschitz continuity of the activation function. Remarkably, this analysis reveals that an appropriately-initialized recurrent neural network trained with $n$ samples can achieve optimality with a network size $m$ that scales only logarithmically with $n$. This sharply contrasts with the prior works that require high-order polynomial dependency of $m$ on $n$ to establish strong regularity conditions. Our results are based on an explicit characterization of the class of dynamical systems that can be approximated and learned by recurrent neural networks via norm-constrained transportation mappings, and establishing local smoothness properties of the hidden state with respect to the learnable parameters.
Provably Robust Temporal Difference Learning for Heavy-Tailed Rewards
Jun 20, 2023In a broad class of reinforcement learning applications, stochastic rewards have heavy-tailed distributions, which lead to infinite second-order moments for stochastic (semi)gradients in policy evaluation and direct policy optimization. In such instances, the existing RL methods may fail miserably due to frequent statistical outliers. In this work, we establish that temporal difference (TD) learning with a dynamic gradient clipping mechanism, and correspondingly operated natural actor-critic (NAC), can be provably robustified against heavy-tailed reward distributions. It is shown in the framework of linear function approximation that a favorable tradeoff between bias and variability of the stochastic gradients can be achieved with this dynamic gradient clipping mechanism. In particular, we prove that robust versions of TD learning achieve sample complexities of order $\mathcal{O}(\varepsilon^{-\frac{1}{p}})$ and $\mathcal{O}(\varepsilon^{-1-\frac{1}{p}})$ with and without the full-rank assumption on the feature matrix, respectively, under heavy-tailed rewards with finite moments of order $(1+p)$ for some $p\in(0,1]$, both in expectation and with high probability. We show that a robust variant of NAC based on Robust TD learning achieves $\tilde{\mathcal{O}}(\varepsilon^{-4-\frac{2}{p}})$ sample complexity. We corroborate our theoretical results with numerical experiments.
Policy Mirror Ascent for Efficient and Independent Learning in Mean Field Games
Dec 29, 2022Mean-field games have been used as a theoretical tool to obtain an approximate Nash equilibrium for symmetric and anonymous $N$-player games in literature. However, limiting applicability, existing theoretical results assume variations of a "population generative model", which allows arbitrary modifications of the population distribution by the learning algorithm. Instead, we show that $N$ agents running policy mirror ascent converge to the Nash equilibrium of the regularized game within $\tilde{\mathcal{O}}(\varepsilon^{-2})$ samples from a single sample trajectory without a population generative model, up to a standard $\mathcal{O}(\frac{1}{\sqrt{N}})$ error due to the mean field. Taking a divergent approach from literature, instead of working with the best-response map we first show that a policy mirror ascent map can be used to construct a contractive operator having the Nash equilibrium as its fixed point. Next, we prove that conditional TD-learning in $N$-agent games can learn value functions within $\tilde{\mathcal{O}}(\varepsilon^{-2})$ time steps. These results allow proving sample complexity guarantees in the oracle-free setting by only relying on a sample path from the $N$ agent simulator. Furthermore, we demonstrate that our methodology allows for independent learning by $N$ agents with finite sample guarantees.
Finite-Time Analysis of Entropy-Regularized Neural Natural Actor-Critic Algorithm
Jun 02, 2022
Natural actor-critic (NAC) and its variants, equipped with the representation power of neural networks, have demonstrated impressive empirical success in solving Markov decision problems with large state spaces. In this paper, we present a finite-time analysis of NAC with neural network approximation, and identify the roles of neural networks, regularization and optimization techniques (e.g., gradient clipping and averaging) to achieve provably good performance in terms of sample complexity, iteration complexity and overparametrization bounds for the actor and the critic. In particular, we prove that (i) entropy regularization and averaging ensure stability by providing sufficient exploration to avoid near-deterministic and strictly suboptimal policies and (ii) regularization leads to sharp sample complexity and network width bounds in the regularized MDPs, yielding a favorable bias-variance tradeoff in policy optimization. In the process, we identify the importance of uniform approximation power of the actor neural network to achieve global optimality in policy optimization due to distributional shift.
Learning to Control Partially Observed Systems with Finite Memory
Feb 22, 2022We consider the reinforcement learning problem for partially observed Markov decision processes (POMDPs) with large or even countably infinite state spaces, where the controller has access to only noisy observations of the underlying controlled Markov chain. We consider a natural actor-critic method that employs a finite internal memory for policy parameterization, and a multi-step temporal difference learning algorithm for policy evaluation. We establish, to the best of our knowledge, the first non-asymptotic global convergence of actor-critic methods for partially observed systems under function approximation. In particular, in addition to the function approximation and statistical errors that also arise in MDPs, we explicitly characterize the error due to the use of finite-state controllers. This additional error is stated in terms of the total variation distance between the traditional belief state in POMDPs and the posterior distribution of the hidden state when using a finite-state controller. Further, we show that this error can be made small in the case of sliding-block controllers by using larger block sizes.