Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Natural Policy Gradient for POMDPs
Paper and Code
May 28, 2024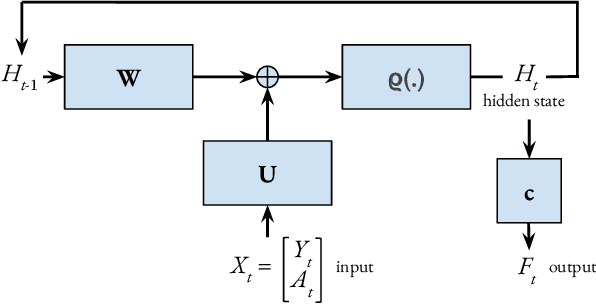
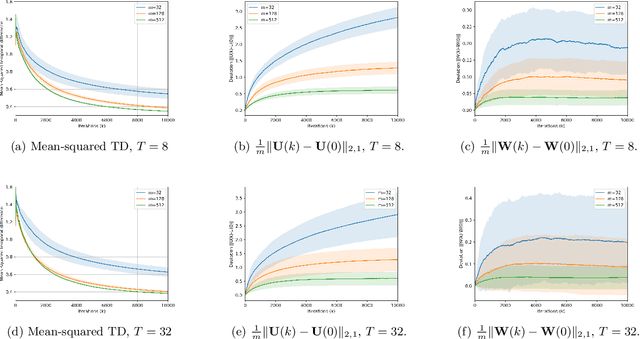
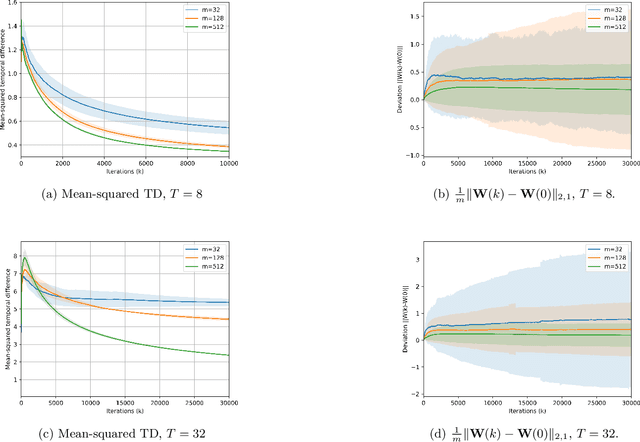
In this paper, we study a natural policy gradient method based on recurrent neural networks (RNNs) for partially-observable Markov decision processes, whereby RNNs are used for policy parameterization and policy evaluation to address curse of dimensionality in non-Markovian reinforcement learning. We present finite-time and finite-width analyses for both the critic (recurrent temporal difference learning), and correspondingly-operated recurrent natural policy gradient method in the near-initialization regime. Our analysis demonstrates the efficiency of RNNs for problems with short-term memory with explicit bounds on the required network widths and sample complexity, and points out the challenges in the case of long-term dependencies.
View paper on