 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Neural Incentive Design with Parameterized Mean-Field Approximation
Oct 24, 2025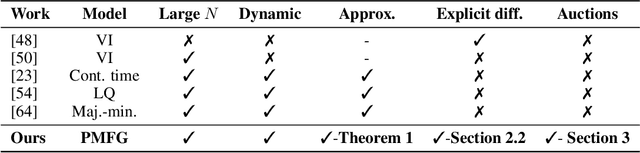
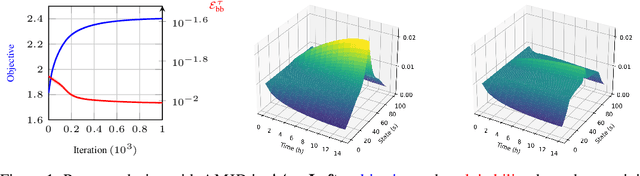
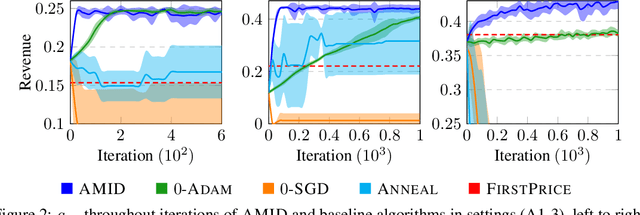

Designing incentives for a multi-agent system to induce a desirable Nash equilibrium is both a crucial and challenging problem appearing in many decision-making domains, especially for a large number of agents $N$. Under the exchangeability assumption, we formalize this incentive design (ID) problem as a parameterized mean-field game (PMFG), aiming to reduce complexity via an infinite-population limit. We first show that when dynamics and rewards are Lipschitz, the finite-$N$ ID objective is approximated by the PMFG at rate $\mathscr{O}(\frac{1}{\sqrt{N}})$. Moreover, beyond the Lipschitz-continuous setting, we prove the same $\mathscr{O}(\frac{1}{\sqrt{N}})$ decay for the important special case of sequential auctions, despite discontinuities in dynamics, through a tailored auction-specific analysis. Built on our novel approximation results, we further introduce our Adjoint Mean-Field Incentive Design (AMID) algorithm, which uses explicit differentiation of iterated equilibrium operators to compute gradients efficiently. By uniting approximation bounds with optimization guarantees, AMID delivers a powerful, scalable algorithmic tool for many-agent (large $N$) ID. Across diverse auction settings, the proposed AMID method substantially increases revenue over first-price formats and outperforms existing benchmark methods.
Exploiting Approximate Symmetry for Efficient Multi-Agent Reinforcement Learning
Aug 27, 2024Mean-field games (MFG) have become significant tools for solving large-scale multi-agent reinforcement learning problems under symmetry. However, the assumption of exact symmetry limits the applicability of MFGs, as real-world scenarios often feature inherent heterogeneity. Furthermore, most works on MFG assume access to a known MFG model, which might not be readily available for real-world finite-agent games. In this work, we broaden the applicability of MFGs by providing a methodology to extend any finite-player, possibly asymmetric, game to an "induced MFG". First, we prove that $N$-player dynamic games can be symmetrized and smoothly extended to the infinite-player continuum via explicit Kirszbraun extensions. Next, we propose the notion of $\alpha,\beta$-symmetric games, a new class of dynamic population games that incorporate approximate permutation invariance. For $\alpha,\beta$-symmetric games, we establish explicit approximation bounds, demonstrating that a Nash policy of the induced MFG is an approximate Nash of the $N$-player dynamic game. We show that TD learning converges up to a small bias using trajectories of the $N$-player game with finite-sample guarantees, permitting symmetrized learning without building an explicit MFG model. Finally, for certain games satisfying monotonicity, we prove a sample complexity of $\widetilde{\mathcal{O}}(\varepsilon^{-6})$ for the $N$-agent game to learn an $\varepsilon$-Nash up to symmetrization bias. Our theory is supported by evaluations on MARL benchmarks with thousands of agents.
On the Statistical Efficiency of Mean Field Reinforcement Learning with General Function Approximation
May 18, 2023In this paper, we study the statistical efficiency of Reinforcement Learning in Mean-Field Control (MFC) and Mean-Field Game (MFG) with general function approximation. We introduce a new concept called Mean-Field Model-Based Eluder Dimension (MBED), which subsumes a rich family of Mean-Field RL problems. Additionally, we propose algorithms based on Optimistic Maximal Likelihood Estimation, which can return an $\epsilon$-optimal policy for MFC or an $\epsilon$-Nash Equilibrium policy for MFG, with sample complexity polynomial w.r.t. relevant parameters and independent of the number of states, actions and the number of agents. Notably, our results only require a mild assumption of Lipschitz continuity on transition dynamics and avoid strong structural assumptions in previous work. Finally, in the tabular setting, given the access to a generative model, we establish an exponential lower bound for MFC setting, while providing a novel sample-efficient model elimination algorithm to approximate equilibrium in MFG setting. Our results reveal a fundamental separation between RL for single-agent, MFC, and MFG from the sample efficiency perspective.
Policy Mirror Ascent for Efficient and Independent Learning in Mean Field Games
Dec 29, 2022Mean-field games have been used as a theoretical tool to obtain an approximate Nash equilibrium for symmetric and anonymous $N$-player games in literature. However, limiting applicability, existing theoretical results assume variations of a "population generative model", which allows arbitrary modifications of the population distribution by the learning algorithm. Instead, we show that $N$ agents running policy mirror ascent converge to the Nash equilibrium of the regularized game within $\tilde{\mathcal{O}}(\varepsilon^{-2})$ samples from a single sample trajectory without a population generative model, up to a standard $\mathcal{O}(\frac{1}{\sqrt{N}})$ error due to the mean field. Taking a divergent approach from literature, instead of working with the best-response map we first show that a policy mirror ascent map can be used to construct a contractive operator having the Nash equilibrium as its fixed point. Next, we prove that conditional TD-learning in $N$-agent games can learn value functions within $\tilde{\mathcal{O}}(\varepsilon^{-2})$ time steps. These results allow proving sample complexity guarantees in the oracle-free setting by only relying on a sample path from the $N$ agent simulator. Furthermore, we demonstrate that our methodology allows for independent learning by $N$ agents with finite sample guarantees.