 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliMory: Orchestrating Cognitive Memory for Conversational Agents
Jun 02, 2026Conversational agents that serve as lifelong companions must maintain persistent memory across all interactions. However, simply expanding context windows with raw retrieval degrades reasoning quality, while training memory agents via standard reinforcement learning creates a severe credit assignment bottleneck in a multi-stage pipeline. To solve this, we introduce SALIMORY, a framework that trains a single language model to manage a cognitively-structured memory-spanning user facts, preferences, and working memory. By introducing a hierarchical stage-wise process reward and reward-decomposed contrastive refinement, SALIMORY provides isolated supervision for distinct memory operations (selective filtering, consolidation, and cue-driven recall) end-to-end. SALIMORY cuts memory-attributed failures by one-third, outperforms the state-of-the-art by over 10% in end-to-end accuracy, and more than doubles the Good Personalization rate.
Pixel-Grounded Retrieval for Knowledgeable Large Multimodal Models
Jan 27, 2026Visual Question Answering (VQA) often requires coupling fine-grained perception with factual knowledge beyond the input image. Prior multimodal Retrieval-Augmented Generation (MM-RAG) systems improve factual grounding but lack an internal policy for when and how to retrieve. We propose PixSearch, the first end-to-end Segmenting Large Multimodal Model (LMM) that unifies region-level perception and retrieval-augmented reasoning. During encoding, PixSearch emits <search> tokens to trigger retrieval, selects query modalities (text, image, or region), and generates pixel-level masks that directly serve as visual queries, eliminating the reliance on modular pipelines (detectors, segmenters, captioners, etc.). A two-stage supervised fine-tuning regimen with search-interleaved supervision teaches retrieval timing and query selection while preserving segmentation ability. On egocentric and entity-centric VQA benchmarks, PixSearch substantially improves factual consistency and generalization, yielding a 19.7% relative gain in accuracy on CRAG-MM compared to whole image retrieval, while retaining competitive reasoning performance on various VQA and text-only QA tasks.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025


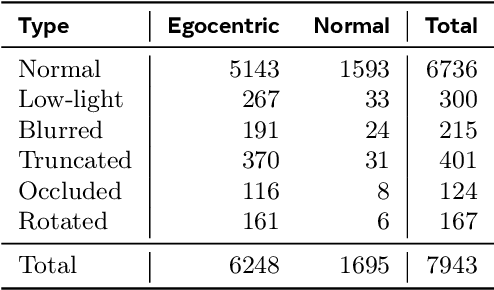
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025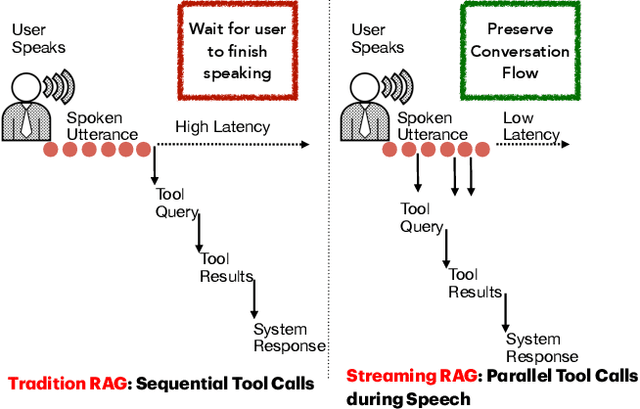
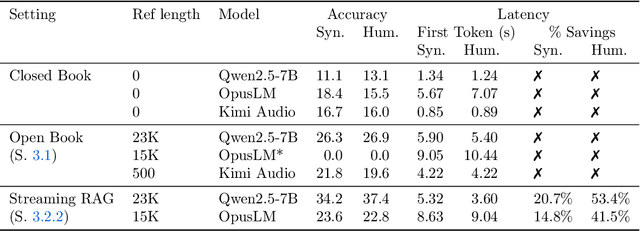
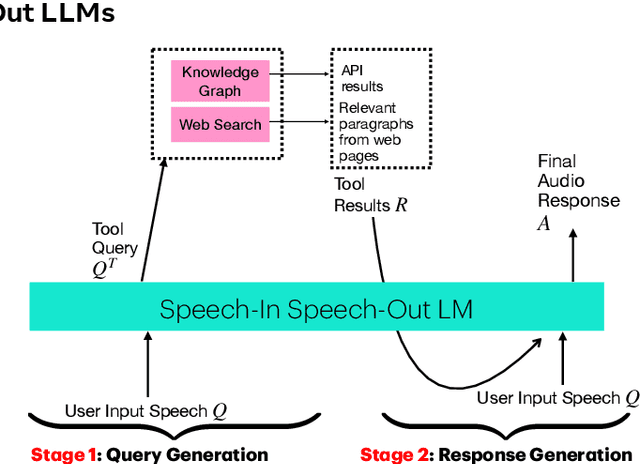
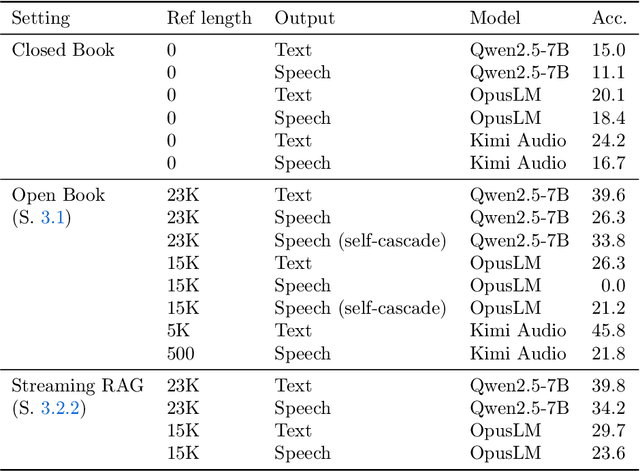
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
Domain-specific Question Answering with Hybrid Search
Dec 04, 2024



Domain specific question answering is an evolving field that requires specialized solutions to address unique challenges. In this paper, we show that a hybrid approach combining a fine-tuned dense retriever with keyword based sparse search methods significantly enhances performance. Our system leverages a linear combination of relevance signals, including cosine similarity from dense retrieval, BM25 scores, and URL host matching, each with tunable boost parameters. Experimental results indicate that this hybrid method outperforms our single-retriever system, achieving improved accuracy while maintaining robust contextual grounding. These findings suggest that integrating multiple retrieval methodologies with weighted scoring effectively addresses the complexities of domain specific question answering in enterprise settings.
Smart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express
Aug 26, 2024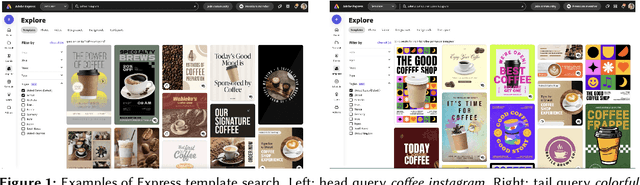
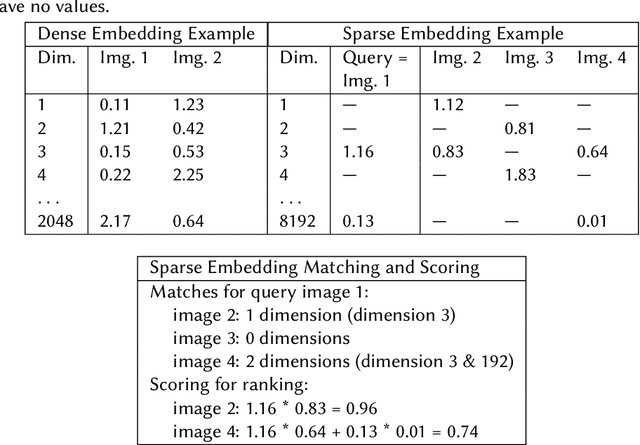

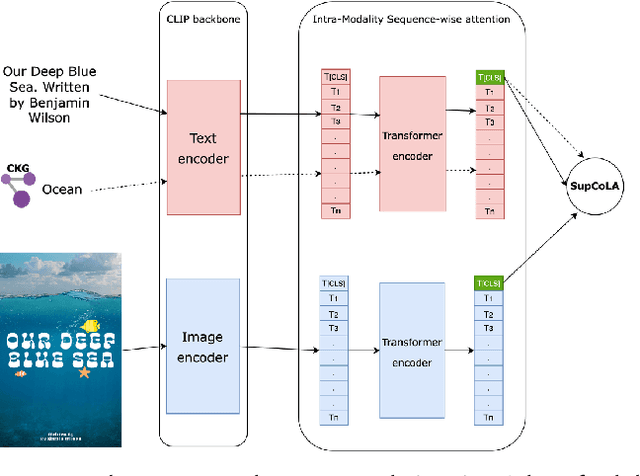
As user content and queries become increasingly multi-modal, the need for effective multi-modal search systems has grown. Traditional search systems often rely on textual and metadata annotations for indexed images, while multi-modal embeddings like CLIP enable direct search using text and image embeddings. However, embedding-based approaches face challenges in integrating contextual features such as user locale and recency. Building a scalable multi-modal search system requires fine-tuning several components. This paper presents a multi-modal search architecture and a series of AB tests that optimize embeddings and multi-modal technologies in Adobe Express template search. We address considerations such as embedding model selection, the roles of embeddings in matching and ranking, and the balance between dense and sparse embeddings. Our iterative approach demonstrates how utilizing sparse, dense, and contextual features enhances short and long query search, significantly reduces null rates (over 70\%), and increases click-through rates (CTR). Our findings provide insights into developing robust multi-modal search systems, thereby enhancing relevance for complex queries.
Hide and Seek: Fingerprinting Large Language Models with Evolutionary Learning
Aug 06, 2024As content generated by Large Language Model (LLM) has grown exponentially, the ability to accurately identify and fingerprint such text has become increasingly crucial. In this work, we introduce a novel black-box approach for fingerprinting LLMs, achieving an impressive 72% accuracy in identifying the correct family of models (Such as Llama, Mistral, Gemma, etc) among a lineup of LLMs. We present an evolutionary strategy that leverages the capabilities of one LLM to discover the most salient features for identifying other LLMs. Our method employs a unique "Hide and Seek" algorithm, where an Auditor LLM generates discriminative prompts, and a Detective LLM analyzes the responses to fingerprint the target models. This approach not only demonstrates the feasibility of LLM-driven model identification but also reveals insights into the semantic manifolds of different LLM families. By iteratively refining prompts through in-context learning, our system uncovers subtle distinctions between model outputs, providing a powerful tool for LLM analysis and verification. This research opens new avenues for understanding LLM behavior and has significant implications for model attribution, security, and the broader field of AI transparency.
Retrieval Augmented Generation for Domain-specific Question Answering
Apr 23, 2024



Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Semantic In-Domain Product Identification for Search Queries
Apr 13, 2024



Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Augmenting Knowledge Graph Hierarchies Using Neural Transformers
Apr 11, 2024Knowledge graphs are useful tools to organize, recommend and sort data. Hierarchies in knowledge graphs provide significant benefit in improving understanding and compartmentalization of the data within a knowledge graph. This work leverages large language models to generate and augment hierarchies in an existing knowledge graph. For small (<100,000 node) domain-specific KGs, we find that a combination of few-shot prompting with one-shot generation works well, while larger KG may require cyclical generation. We present techniques for augmenting hierarchies, which led to coverage increase by 98% for intents and 99% for colors in our knowledge graph.