 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-specific Question Answering with Hybrid Search
Dec 04, 2024



Domain specific question answering is an evolving field that requires specialized solutions to address unique challenges. In this paper, we show that a hybrid approach combining a fine-tuned dense retriever with keyword based sparse search methods significantly enhances performance. Our system leverages a linear combination of relevance signals, including cosine similarity from dense retrieval, BM25 scores, and URL host matching, each with tunable boost parameters. Experimental results indicate that this hybrid method outperforms our single-retriever system, achieving improved accuracy while maintaining robust contextual grounding. These findings suggest that integrating multiple retrieval methodologies with weighted scoring effectively addresses the complexities of domain specific question answering in enterprise settings.
The Potential and Pitfalls of using a Large Language Model such as ChatGPT or GPT-4 as a Clinical Assistant
Jul 16, 2023
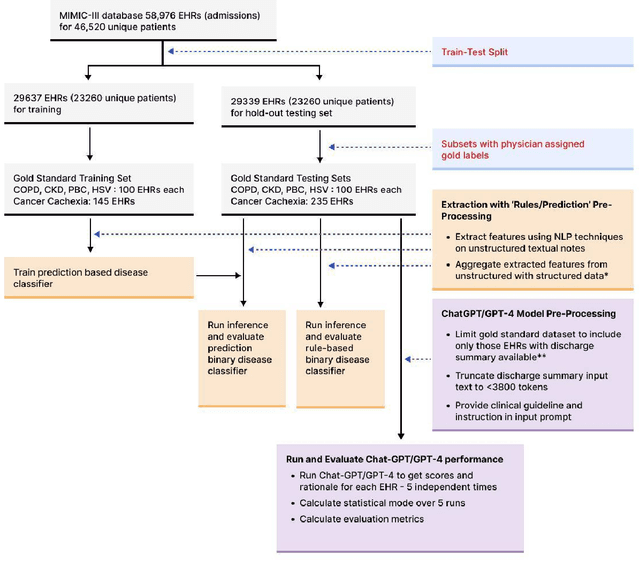
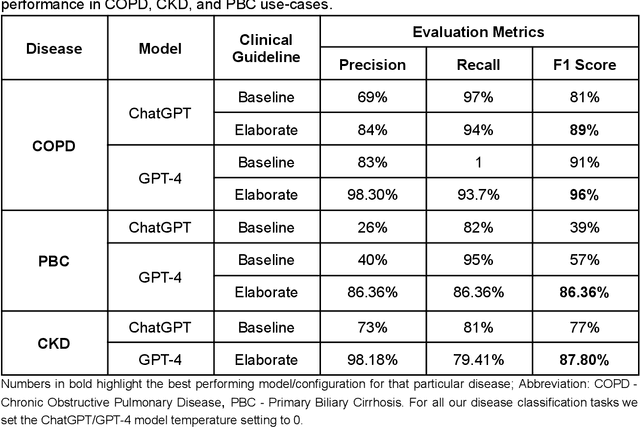
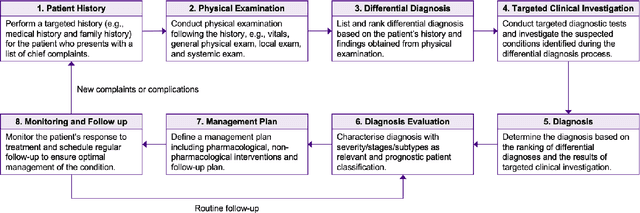
Recent studies have demonstrated promising performance of ChatGPT and GPT-4 on several medical domain tasks. However, none have assessed its performance using a large-scale real-world electronic health record database, nor have evaluated its utility in providing clinical diagnostic assistance for patients across a full range of disease presentation. We performed two analyses using ChatGPT and GPT-4, one to identify patients with specific medical diagnoses using a real-world large electronic health record database and the other, in providing diagnostic assistance to healthcare workers in the prospective evaluation of hypothetical patients. Our results show that GPT-4 across disease classification tasks with chain of thought and few-shot prompting can achieve performance as high as 96% F1 scores. For patient assessment, GPT-4 can accurately diagnose three out of four times. However, there were mentions of factually incorrect statements, overlooking crucial medical findings, recommendations for unnecessary investigations and overtreatment. These issues coupled with privacy concerns, make these models currently inadequate for real world clinical use. However, limited data and time needed for prompt engineering in comparison to configuration of conventional machine learning workflows highlight their potential for scalability across healthcare applications.