 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutBERT: Masked Language Layout Model for Object Insertion
Apr 30, 2022
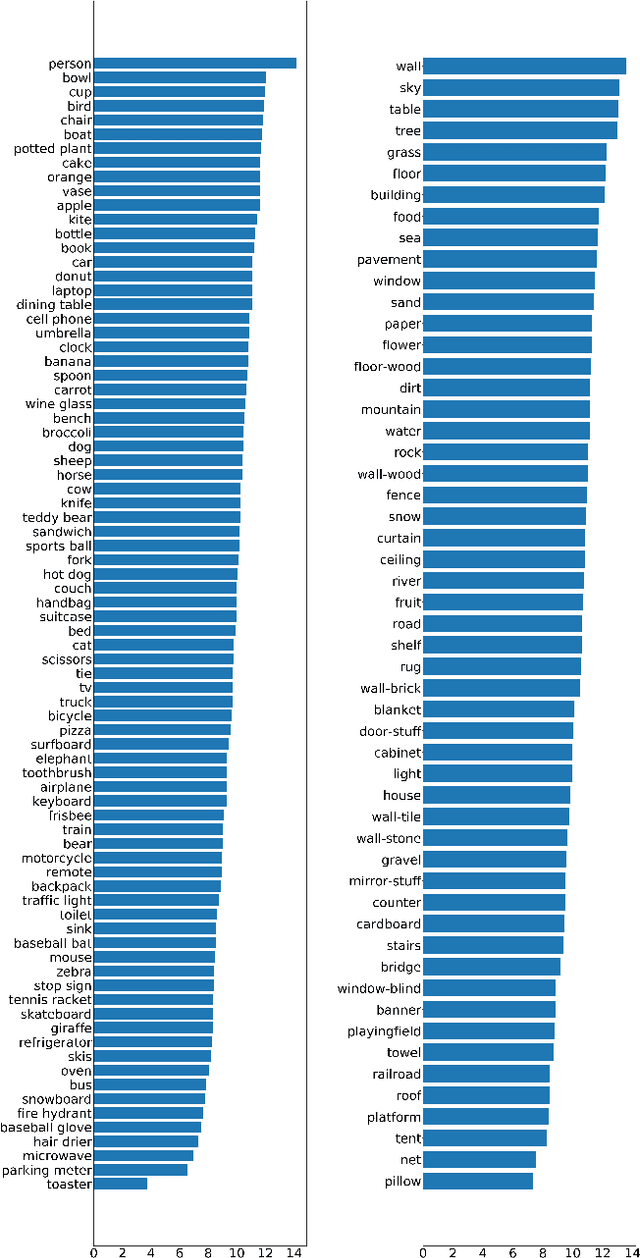

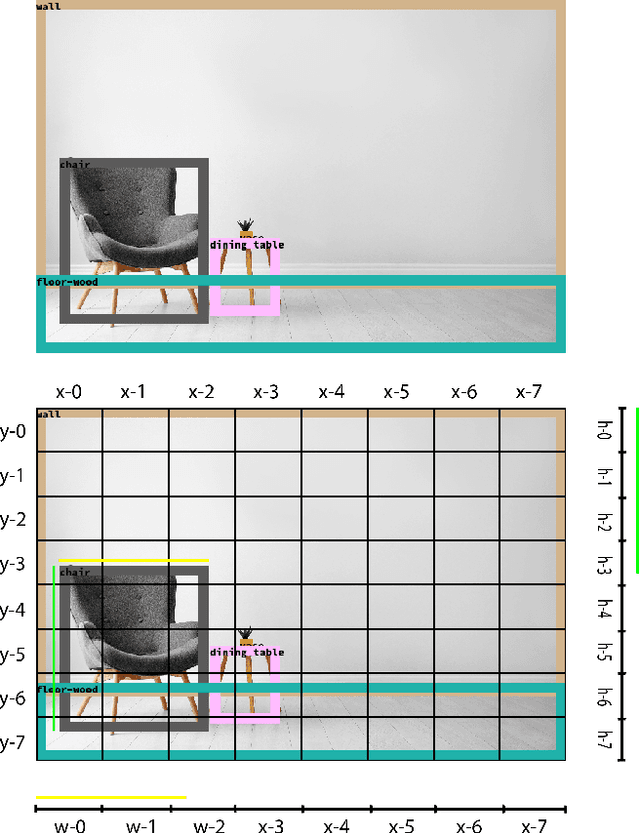
Image compositing is one of the most fundamental steps in creative workflows. It involves taking objects/parts of several images to create a new image, called a composite. Currently, this process is done manually by creating accurate masks of objects to be inserted and carefully blending them with the target scene or images, usually with the help of tools such as Photoshop or GIMP. While there have been several works on automatic selection of objects for creating masks, the problem of object placement within an image with the correct position, scale, and harmony remains a difficult problem with limited exploration. Automatic object insertion in images or designs is a difficult problem as it requires understanding of the scene geometry and the color harmony between objects. We propose LayoutBERT for the object insertion task. It uses a novel self-supervised masked language model objective and bidirectional multi-head self-attention. It outperforms previous layout-based likelihood models and shows favorable properties in terms of model capacity. We demonstrate the effectiveness of our approach for object insertion in the image compositing setting and other settings like documents and design templates. We further demonstrate the usefulness of the learned representations for layout-based retrieval tasks. We provide both qualitative and quantitative evaluations on datasets from diverse domains like COCO, PublayNet, and two new datasets which we call Image Layouts and Template Layouts. Image Layouts which consists of 5.8 million images with layout annotations is the largest image layout dataset to our knowledge. We also share ablation study results on the effect of dataset size, model size and class sample size for this task.
CLIP-Art: Contrastive Pre-training for Fine-Grained Art Classification
Apr 29, 2022



Existing computer vision research in artwork struggles with artwork's fine-grained attributes recognition and lack of curated annotated datasets due to their costly creation. To the best of our knowledge, we are one of the first methods to use CLIP (Contrastive Language-Image Pre-Training) to train a neural network on a variety of artwork images and text descriptions pairs. CLIP is able to learn directly from free-form art descriptions, or, if available, curated fine-grained labels. Model's zero-shot capability allows predicting accurate natural language description for a given image, without directly optimizing for the task. Our approach aims to solve 2 challenges: instance retrieval and fine-grained artwork attribute recognition. We use the iMet Dataset, which we consider the largest annotated artwork dataset. In this benchmark we achieved competitive results using only self-supervision.
* CVPR CVFAD Workshop 2021
Exploring Vision Transformers for Fine-grained Classification
Jun 30, 2021



Existing computer vision research in categorization struggles with fine-grained attributes recognition due to the inherently high intra-class variances and low inter-class variances. SOTA methods tackle this challenge by locating the most informative image regions and rely on them to classify the complete image. The most recent work, Vision Transformer (ViT), shows its strong performance in both traditional and fine-grained classification tasks. In this work, we propose a multi-stage ViT framework for fine-grained image classification tasks, which localizes the informative image regions without requiring architectural changes using the inherent multi-head self-attention mechanism. We also introduce attention-guided augmentations for improving the model's capabilities. We demonstrate the value of our approach by experimenting with four popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, and FGVC7 Plant Pathology. We also prove our model's interpretability via qualitative results.