 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deepfake Detection, NTIRE 2026 Challenge: Report
Apr 27, 2026Robustness is a long-overlooked problem in deepfake detection. However, detection performance is nearly worthless in the real world if it suffers under exposure to even slight image degradation. In addition to weaker degradations that can accidentally occur in the image processing pipeline, there is another risk of malicious deepfakes that specifically introduce degradations, purposefully exploiting the detector's weaknesses in that regard. Here, we present an overview of the NTIRE 2026 Robust Deepfake Detection Challenge, which specifically addresses that problem. Participants were tasked with building a detector that would later be tested on an unknown test-set, which included both common and uncommon degradations of various strengths. With a total number of 337 participants and 57 submissions to the final leaderboard, the first edition of the challenge was well received. To ensure the reliability of the results, participants were given only 24h to complete the test run with no labels provided, limiting the possibility of training on the test data. Furthermore, the top solutions were scored on a private test-set to detect any such overfitting. This report presents the competition setting, dataset preparation, as well as details and performance of methods. Top methods rely on large foundation models, ensembles, and degradation training to combine generality and robustness.
Low Light Image Enhancement Challenge at NTIRE 2026
Apr 19, 2026This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
Smart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express
Aug 26, 2024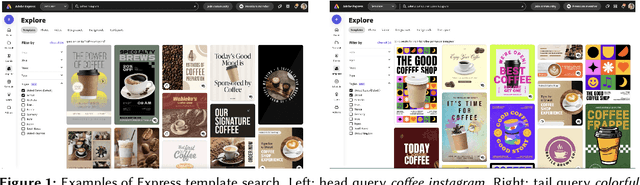
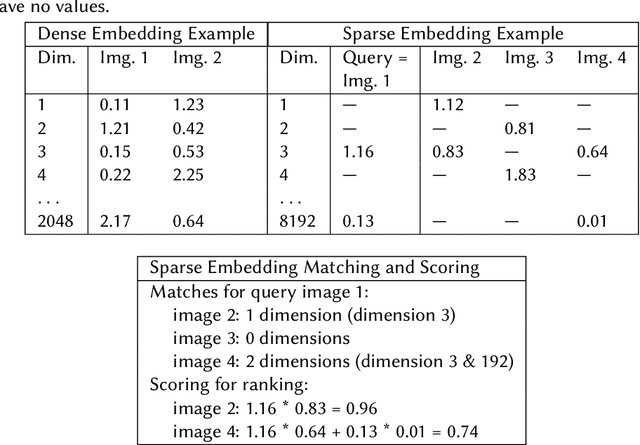

As user content and queries become increasingly multi-modal, the need for effective multi-modal search systems has grown. Traditional search systems often rely on textual and metadata annotations for indexed images, while multi-modal embeddings like CLIP enable direct search using text and image embeddings. However, embedding-based approaches face challenges in integrating contextual features such as user locale and recency. Building a scalable multi-modal search system requires fine-tuning several components. This paper presents a multi-modal search architecture and a series of AB tests that optimize embeddings and multi-modal technologies in Adobe Express template search. We address considerations such as embedding model selection, the roles of embeddings in matching and ranking, and the balance between dense and sparse embeddings. Our iterative approach demonstrates how utilizing sparse, dense, and contextual features enhances short and long query search, significantly reduces null rates (over 70\%), and increases click-through rates (CTR). Our findings provide insights into developing robust multi-modal search systems, thereby enhancing relevance for complex queries.
Semantic In-Domain Product Identification for Search Queries
Apr 13, 2024



Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Augmenting Knowledge Graph Hierarchies Using Neural Transformers
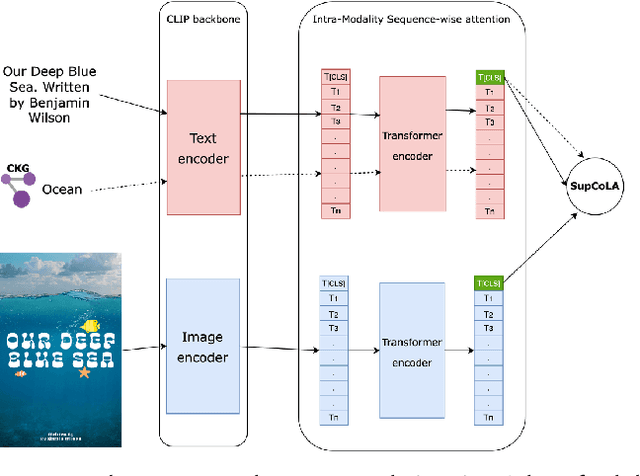
Apr 11, 2024Knowledge graphs are useful tools to organize, recommend and sort data. Hierarchies in knowledge graphs provide significant benefit in improving understanding and compartmentalization of the data within a knowledge graph. This work leverages large language models to generate and augment hierarchies in an existing knowledge graph. For small (<100,000 node) domain-specific KGs, we find that a combination of few-shot prompting with one-shot generation works well, while larger KG may require cyclical generation. We present techniques for augmenting hierarchies, which led to coverage increase by 98% for intents and 99% for colors in our knowledge graph.
Contextual Font Recommendations based on User Intent
Jun 14, 2023



Adobe Fonts has a rich library of over 20,000 unique fonts that Adobe users utilize for creating graphics, posters, composites etc. Due to the nature of the large library, knowing what font to select can be a daunting task that requires a lot of experience. For most users in Adobe products, especially casual users of Adobe Express, this often means choosing the default font instead of utilizing the rich and diverse fonts available. In this work, we create an intent-driven system to provide contextual font recommendations to users to aid in their creative journey. Our system takes in multilingual text input and recommends suitable fonts based on the user's intent. Based on user entitlements, the mix of free and paid fonts is adjusted. The feature is currently used by millions of Adobe Express users with a CTR of >25%.
LayoutBERT: Masked Language Layout Model for Object Insertion
Apr 30, 2022

Image compositing is one of the most fundamental steps in creative workflows. It involves taking objects/parts of several images to create a new image, called a composite. Currently, this process is done manually by creating accurate masks of objects to be inserted and carefully blending them with the target scene or images, usually with the help of tools such as Photoshop or GIMP. While there have been several works on automatic selection of objects for creating masks, the problem of object placement within an image with the correct position, scale, and harmony remains a difficult problem with limited exploration. Automatic object insertion in images or designs is a difficult problem as it requires understanding of the scene geometry and the color harmony between objects. We propose LayoutBERT for the object insertion task. It uses a novel self-supervised masked language model objective and bidirectional multi-head self-attention. It outperforms previous layout-based likelihood models and shows favorable properties in terms of model capacity. We demonstrate the effectiveness of our approach for object insertion in the image compositing setting and other settings like documents and design templates. We further demonstrate the usefulness of the learned representations for layout-based retrieval tasks. We provide both qualitative and quantitative evaluations on datasets from diverse domains like COCO, PublayNet, and two new datasets which we call Image Layouts and Template Layouts. Image Layouts which consists of 5.8 million images with layout annotations is the largest image layout dataset to our knowledge. We also share ablation study results on the effect of dataset size, model size and class sample size for this task.