 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteNator: A Router-Based Multi-Modal Architecture for Generating Synthetic Training Data for Function Calling LLMs
May 15, 2025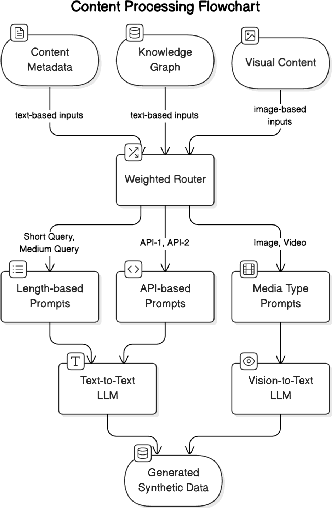

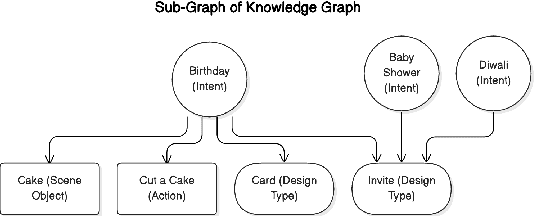
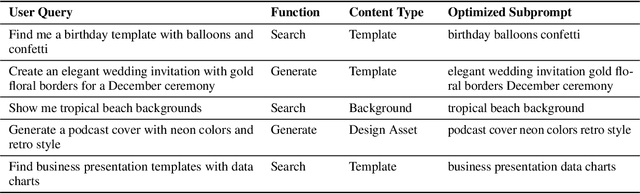
This paper addresses fine-tuning Large Language Models (LLMs) for function calling tasks when real user interaction data is unavailable. In digital content creation tools, where users express their needs through natural language queries that must be mapped to API calls, the lack of real-world task-specific data and privacy constraints for training on it necessitate synthetic data generation. Existing approaches to synthetic data generation fall short in diversity and complexity, failing to replicate real-world data distributions and leading to suboptimal performance after LLM fine-tuning. We present a novel router-based architecture that leverages domain resources like content metadata and structured knowledge graphs, along with text-to-text and vision-to-text language models to generate high-quality synthetic training data. Our architecture's flexible routing mechanism enables synthetic data generation that matches observed real-world distributions, addressing a fundamental limitation of traditional approaches. Evaluation on a comprehensive set of real user queries demonstrates significant improvements in both function classification accuracy and API parameter selection. Models fine-tuned with our synthetic data consistently outperform traditional approaches, establishing new benchmarks for function calling tasks.
* Proceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing
Smart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express
Aug 26, 2024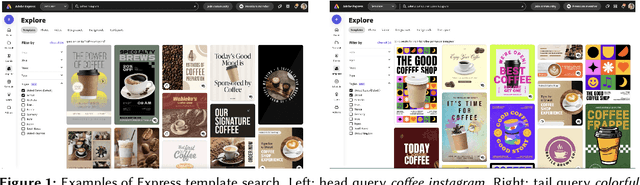
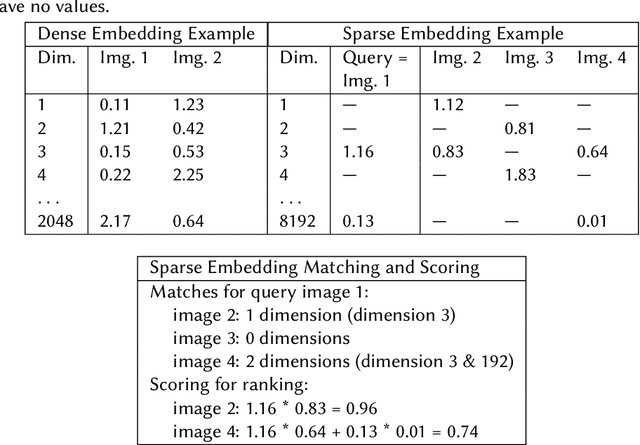

As user content and queries become increasingly multi-modal, the need for effective multi-modal search systems has grown. Traditional search systems often rely on textual and metadata annotations for indexed images, while multi-modal embeddings like CLIP enable direct search using text and image embeddings. However, embedding-based approaches face challenges in integrating contextual features such as user locale and recency. Building a scalable multi-modal search system requires fine-tuning several components. This paper presents a multi-modal search architecture and a series of AB tests that optimize embeddings and multi-modal technologies in Adobe Express template search. We address considerations such as embedding model selection, the roles of embeddings in matching and ranking, and the balance between dense and sparse embeddings. Our iterative approach demonstrates how utilizing sparse, dense, and contextual features enhances short and long query search, significantly reduces null rates (over 70\%), and increases click-through rates (CTR). Our findings provide insights into developing robust multi-modal search systems, thereby enhancing relevance for complex queries.
Semantic In-Domain Product Identification for Search Queries
Apr 13, 2024



Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Contextual Font Recommendations based on User Intent
Jun 14, 2023



Adobe Fonts has a rich library of over 20,000 unique fonts that Adobe users utilize for creating graphics, posters, composites etc. Due to the nature of the large library, knowing what font to select can be a daunting task that requires a lot of experience. For most users in Adobe products, especially casual users of Adobe Express, this often means choosing the default font instead of utilizing the rich and diverse fonts available. In this work, we create an intent-driven system to provide contextual font recommendations to users to aid in their creative journey. Our system takes in multilingual text input and recommends suitable fonts based on the user's intent. Based on user entitlements, the mix of free and paid fonts is adjusted. The feature is currently used by millions of Adobe Express users with a CTR of >25%.
Contextual Multilingual Spellchecker for User Queries
May 01, 2023Spellchecking is one of the most fundamental and widely used search features. Correcting incorrectly spelled user queries not only enhances the user experience but is expected by the user. However, most widely available spellchecking solutions are either lower accuracy than state-of-the-art solutions or too slow to be used for search use cases where latency is a key requirement. Furthermore, most innovative recent architectures focus on English and are not trained in a multilingual fashion and are trained for spell correction in longer text, which is a different paradigm from spell correction for user queries, where context is sparse (most queries are 1-2 words long). Finally, since most enterprises have unique vocabularies such as product names, off-the-shelf spelling solutions fall short of users' needs. In this work, we build a multilingual spellchecker that is extremely fast and scalable and that adapts its vocabulary and hence speller output based on a specific product's needs. Furthermore, our speller out-performs general purpose spellers by a wide margin on in-domain datasets. Our multilingual speller is used in search in Adobe products, powering autocomplete in various applications.