 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteNator: A Router-Based Multi-Modal Architecture for Generating Synthetic Training Data for Function Calling LLMs
May 15, 2025This paper addresses fine-tuning Large Language Models (LLMs) for function calling tasks when real user interaction data is unavailable. In digital content creation tools, where users express their needs through natural language queries that must be mapped to API calls, the lack of real-world task-specific data and privacy constraints for training on it necessitate synthetic data generation. Existing approaches to synthetic data generation fall short in diversity and complexity, failing to replicate real-world data distributions and leading to suboptimal performance after LLM fine-tuning. We present a novel router-based architecture that leverages domain resources like content metadata and structured knowledge graphs, along with text-to-text and vision-to-text language models to generate high-quality synthetic training data. Our architecture's flexible routing mechanism enables synthetic data generation that matches observed real-world distributions, addressing a fundamental limitation of traditional approaches. Evaluation on a comprehensive set of real user queries demonstrates significant improvements in both function classification accuracy and API parameter selection. Models fine-tuned with our synthetic data consistently outperform traditional approaches, establishing new benchmarks for function calling tasks.
* Proceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing
Domain-specific Question Answering with Hybrid Search
Dec 04, 2024



Domain specific question answering is an evolving field that requires specialized solutions to address unique challenges. In this paper, we show that a hybrid approach combining a fine-tuned dense retriever with keyword based sparse search methods significantly enhances performance. Our system leverages a linear combination of relevance signals, including cosine similarity from dense retrieval, BM25 scores, and URL host matching, each with tunable boost parameters. Experimental results indicate that this hybrid method outperforms our single-retriever system, achieving improved accuracy while maintaining robust contextual grounding. These findings suggest that integrating multiple retrieval methodologies with weighted scoring effectively addresses the complexities of domain specific question answering in enterprise settings.
Multi-concept adversarial attacks
Oct 19, 2021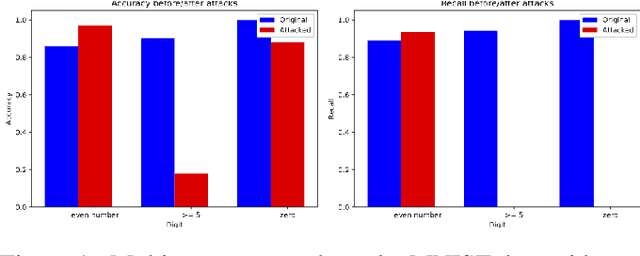



As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.