 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Subsampling for ROI-based Visual Tracking: Algorithms and FPGA Implementation
Jan 17, 2022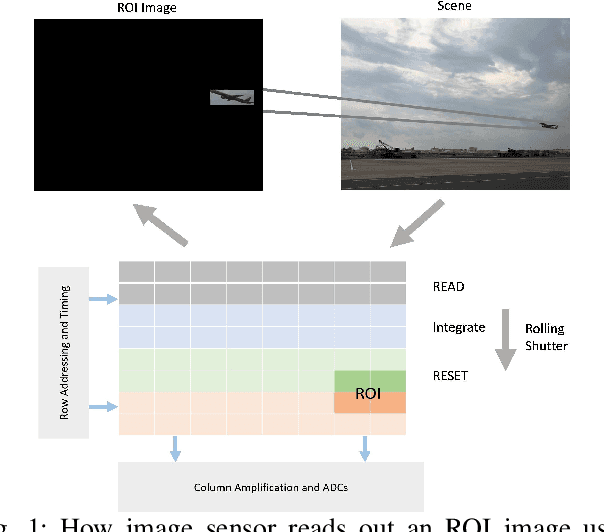

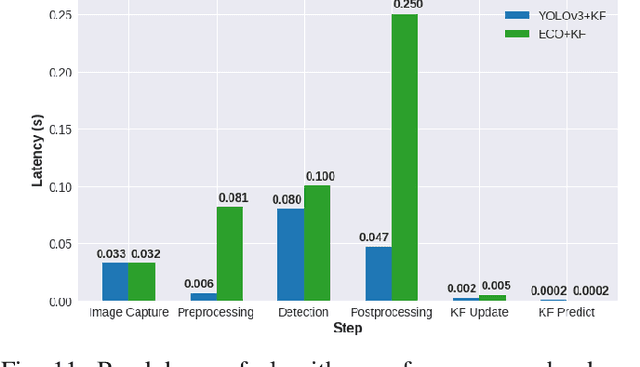

There is tremendous scope for improving the energy efficiency of embedded vision systems by incorporating programmable region-of-interest (ROI) readout in the image sensor design. In this work, we study how ROI programmability can be leveraged for tracking applications by anticipating where the ROI will be located in future frames and switching pixels off outside of this region. We refer to this process of ROI prediction and corresponding sensor configuration as adaptive subsampling. Our adaptive subsampling algorithms comprise an object detector and an ROI predictor (Kalman filter) which operate in conjunction to optimize the energy efficiency of the vision pipeline with the end task being object tracking. To further facilitate the implementation of our adaptive algorithms in real life, we select a candidate algorithm and map it onto an FPGA. Leveraging Xilinx Vitis AI tools, we designed and accelerated a YOLO object detector-based adaptive subsampling algorithm. In order to further improve the algorithm post-deployment, we evaluated several competing baselines on the OTB100 and LaSOT datasets. We found that coupling the ECO tracker with the Kalman filter has a competitive AUC score of 0.4568 and 0.3471 on the OTB100 and LaSOT datasets respectively. Further, the power efficiency of this algorithm is on par with, and in a couple of instances superior to, the other baselines. The ECO-based algorithm incurs a power consumption of approximately 4 W averaged across both datasets while the YOLO-based approach requires power consumption of approximately 6 W (as per our power consumption model). In terms of accuracy-latency tradeoff, the ECO-based algorithm provides near-real-time performance (19.23 FPS) while managing to attain competitive tracking precision.
Improving Multi-Domain Generalization through Domain Re-labeling
Dec 17, 2021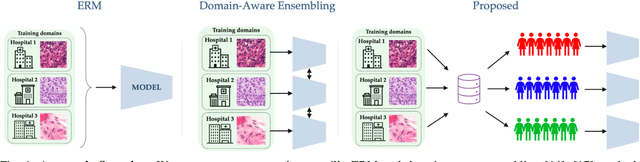
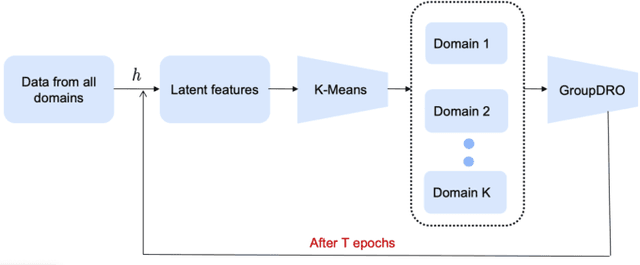
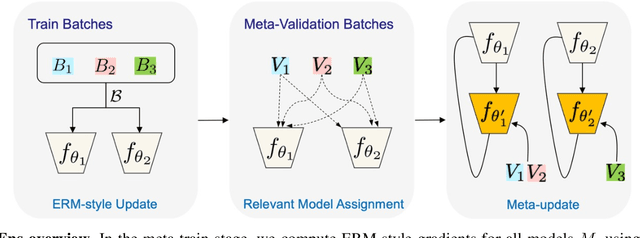
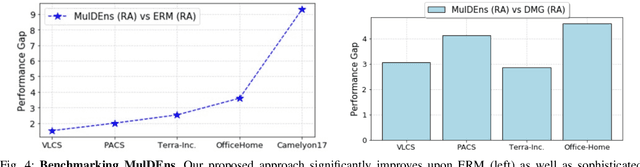
Domain generalization (DG) methods aim to develop models that generalize to settings where the test distribution is different from the training data. In this paper, we focus on the challenging problem of multi-source zero-shot DG, where labeled training data from multiple source domains is available but with no access to data from the target domain. Though this problem has become an important topic of research, surprisingly, the simple solution of pooling all source data together and training a single classifier is highly competitive on standard benchmarks. More importantly, even sophisticated approaches that explicitly optimize for invariance across different domains do not necessarily provide non-trivial gains over ERM. In this paper, for the first time, we study the important link between pre-specified domain labels and the generalization performance. Using a motivating case-study and a new variant of a distributional robust optimization algorithm, GroupDRO++, we first demonstrate how inferring custom domain groups can lead to consistent improvements over the original domain labels that come with the dataset. Subsequently, we introduce a general approach for multi-domain generalization, MulDEns, that uses an ERM-based deep ensembling backbone and performs implicit domain re-labeling through a meta-optimization algorithm. Using empirical studies on multiple standard benchmarks, we show that MulDEns does not require tailoring the augmentation strategy or the training process specific to a dataset, consistently outperforms ERM by significant margins, and produces state-of-the-art generalization performance, even when compared to existing methods that exploit the domain labels.
Invenio: Discovering Hidden Relationships Between Tasks/Domains Using Structured Meta Learning
Nov 24, 2019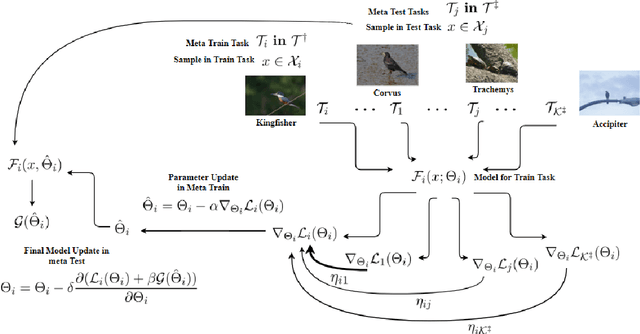
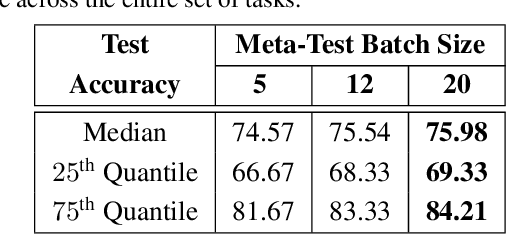

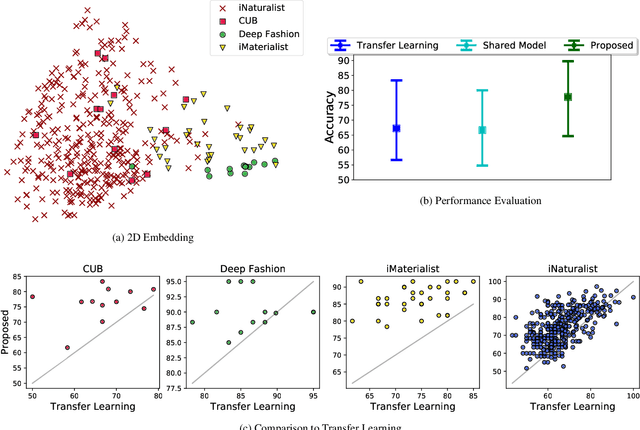
Exploiting known semantic relationships between fine-grained tasks is critical to the success of recent model agnostic approaches. These approaches often rely on meta-optimization to make a model robust to systematic task or domain shifts. However, in practice, the performance of these methods can suffer, when there are no coherent semantic relationships between the tasks (or domains). We present Invenio, a structured meta-learning algorithm to infer semantic similarities between a given set of tasks and to provide insights into the complexity of transferring knowledge between different tasks. In contrast to existing techniques such as Task2Vec and Taskonomy, which measure similarities between pre-trained models, our approach employs a novel self-supervised learning strategy to discover these relationships in the training loop and at the same time utilizes them to update task-specific models in the meta-update step. Using challenging task and domain databases, under few-shot learning settings, we show that Invenio can discover intricate dependencies between tasks or domains, and can provide significant gains over existing approaches in terms of generalization performance. The learned semantic structure between tasks/domains from Invenio is interpretable and can be used to construct meaningful priors for tasks or domains.
Audio Source Separation via Multi-Scale Learning with Dilated Dense U-Nets
Apr 08, 2019
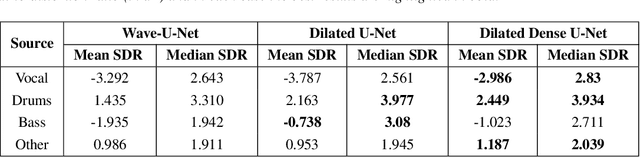
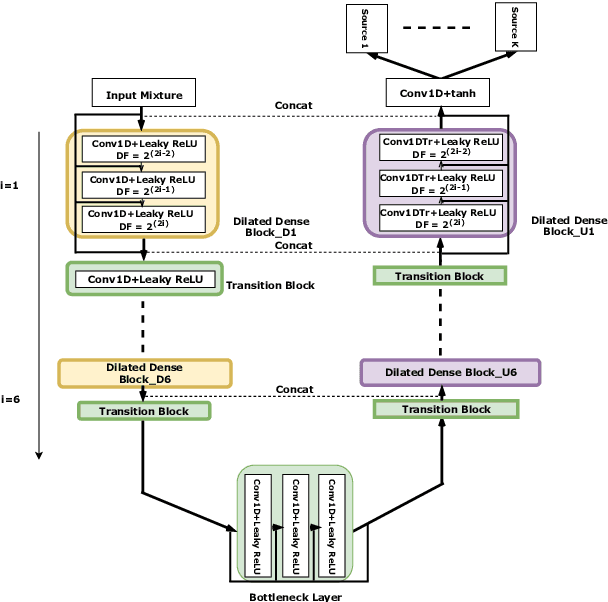
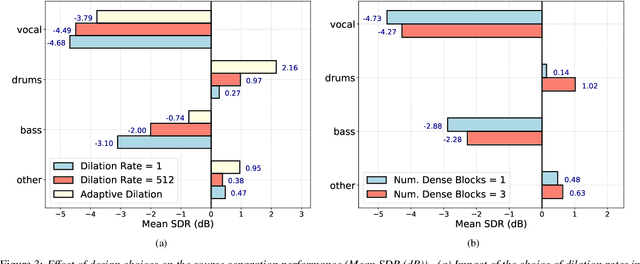
Modern audio source separation techniques rely on optimizing sequence model architectures such as, 1D-CNNs, on mixture recordings to generalize well to unseen mixtures. Specifically, recent focus is on time-domain based architectures such as Wave-U-Net which exploit temporal context by extracting multi-scale features. However, the optimality of the feature extraction process in these architectures has not been well investigated. In this paper, we examine and recommend critical architectural changes that forge an optimal multi-scale feature extraction process. To this end, we replace regular $1-$D convolutions with adaptive dilated convolutions that have innate capability of capturing increased context by using large temporal receptive fields. We also investigate the impact of dense connections on the extraction process that encourage feature reuse and better gradient flow. The dense connections between the downsampling and upsampling paths of a U-Net architecture capture multi-resolution information leading to improved temporal modelling. We evaluate the proposed approaches on the MUSDB test dataset. In addition to providing an improved performance over the state-of-the-art, we also provide insights on the impact of different architectural choices on complex data-driven solutions for source separation.