 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multi-Domain Generalization through Domain Re-labeling
Paper and Code
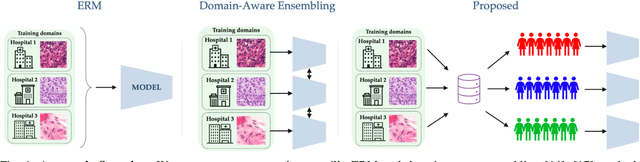
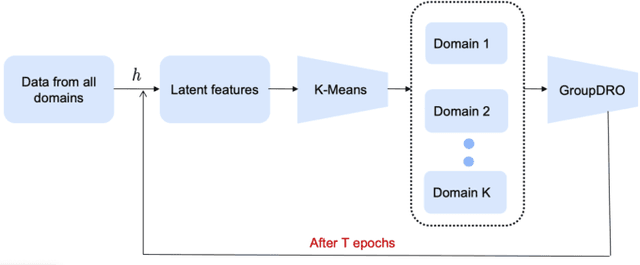
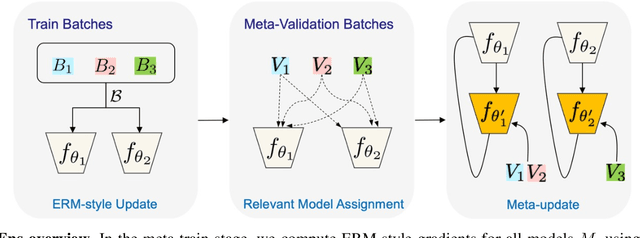
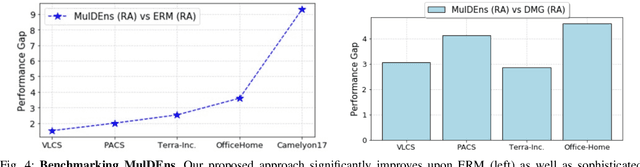
Domain generalization (DG) methods aim to develop models that generalize to settings where the test distribution is different from the training data. In this paper, we focus on the challenging problem of multi-source zero-shot DG, where labeled training data from multiple source domains is available but with no access to data from the target domain. Though this problem has become an important topic of research, surprisingly, the simple solution of pooling all source data together and training a single classifier is highly competitive on standard benchmarks. More importantly, even sophisticated approaches that explicitly optimize for invariance across different domains do not necessarily provide non-trivial gains over ERM. In this paper, for the first time, we study the important link between pre-specified domain labels and the generalization performance. Using a motivating case-study and a new variant of a distributional robust optimization algorithm, GroupDRO++, we first demonstrate how inferring custom domain groups can lead to consistent improvements over the original domain labels that come with the dataset. Subsequently, we introduce a general approach for multi-domain generalization, MulDEns, that uses an ERM-based deep ensembling backbone and performs implicit domain re-labeling through a meta-optimization algorithm. Using empirical studies on multiple standard benchmarks, we show that MulDEns does not require tailoring the augmentation strategy or the training process specific to a dataset, consistently outperforms ERM by significant margins, and produces state-of-the-art generalization performance, even when compared to existing methods that exploit the domain labels.