 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Design of Deep Priors for Unsupervised Audio Restoration
Apr 14, 2021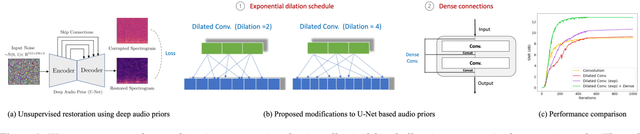
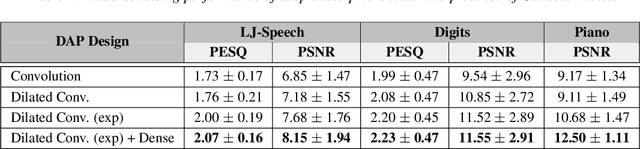
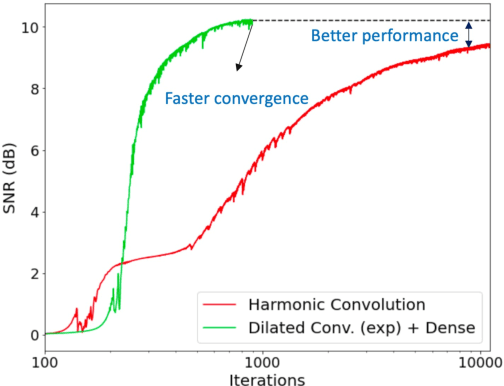
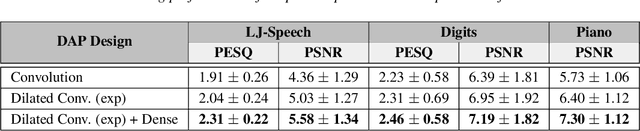
Unsupervised deep learning methods for solving audio restoration problems extensively rely on carefully tailored neural architectures that carry strong inductive biases for defining priors in the time or spectral domain. In this context, lot of recent success has been achieved with sophisticated convolutional network constructions that recover audio signals in the spectral domain. However, in practice, audio priors require careful engineering of the convolutional kernels to be effective at solving ill-posed restoration tasks, while also being easy to train. To this end, in this paper, we propose a new U-Net based prior that does not impact either the network complexity or convergence behavior of existing convolutional architectures, yet leads to significantly improved restoration. In particular, we advocate the use of carefully designed dilation schedules and dense connections in the U-Net architecture to obtain powerful audio priors. Using empirical studies on standard benchmarks and a variety of ill-posed restoration tasks, such as audio denoising, in-painting and source separation, we demonstrate that our proposed approach consistently outperforms widely adopted audio prior architectures.
Audio Source Separation via Multi-Scale Learning with Dilated Dense U-Nets
Apr 08, 2019
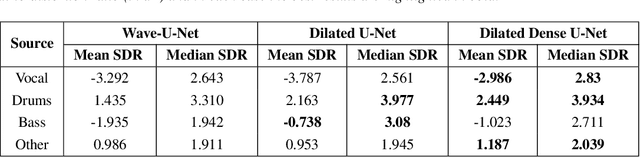
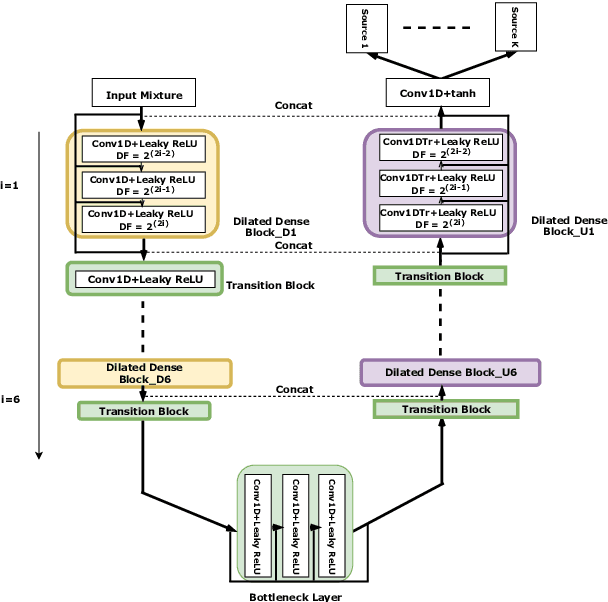
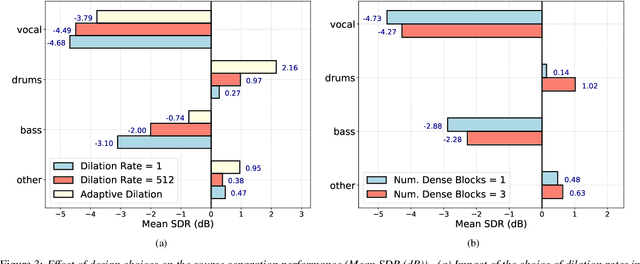
Modern audio source separation techniques rely on optimizing sequence model architectures such as, 1D-CNNs, on mixture recordings to generalize well to unseen mixtures. Specifically, recent focus is on time-domain based architectures such as Wave-U-Net which exploit temporal context by extracting multi-scale features. However, the optimality of the feature extraction process in these architectures has not been well investigated. In this paper, we examine and recommend critical architectural changes that forge an optimal multi-scale feature extraction process. To this end, we replace regular $1-$D convolutions with adaptive dilated convolutions that have innate capability of capturing increased context by using large temporal receptive fields. We also investigate the impact of dense connections on the extraction process that encourage feature reuse and better gradient flow. The dense connections between the downsampling and upsampling paths of a U-Net architecture capture multi-resolution information leading to improved temporal modelling. We evaluate the proposed approaches on the MUSDB test dataset. In addition to providing an improved performance over the state-of-the-art, we also provide insights on the impact of different architectural choices on complex data-driven solutions for source separation.
Designing an Effective Metric Learning Pipeline for Speaker Diarization
Nov 01, 2018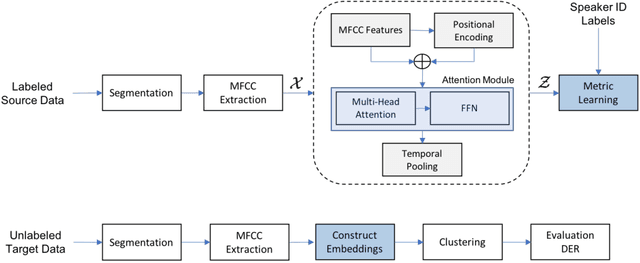
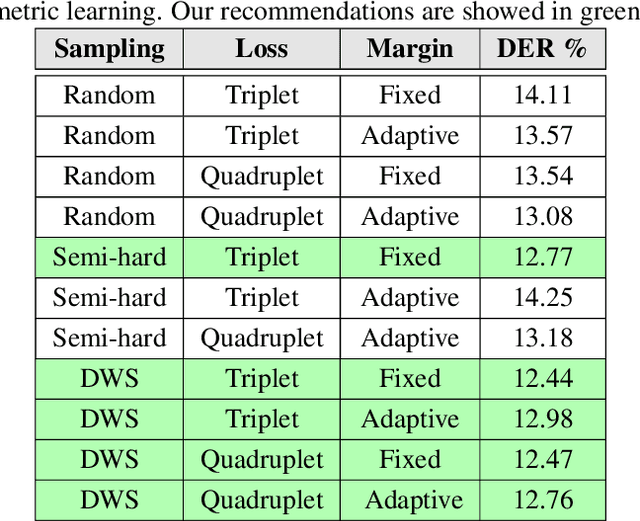
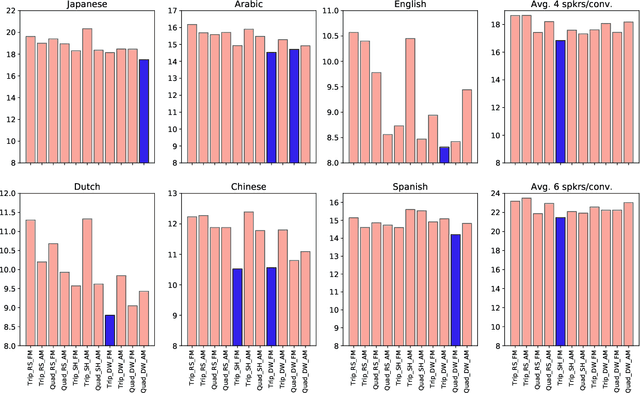
State-of-the-art speaker diarization systems utilize knowledge from external data, in the form of a pre-trained distance metric, to effectively determine relative speaker identities to unseen data. However, much of recent focus has been on choosing the appropriate feature extractor, ranging from pre-trained $i-$vectors to representations learned via different sequence modeling architectures (e.g. 1D-CNNs, LSTMs, attention models), while adopting off-the-shelf metric learning solutions. In this paper, we argue that, regardless of the feature extractor, it is crucial to carefully design a metric learning pipeline, namely the loss function, the sampling strategy and the discrimnative margin parameter, for building robust diarization systems. Furthermore, we propose to adopt a fine-grained validation process to obtain a comprehensive evaluation of the generalization power of metric learning pipelines. To this end, we measure diarization performance across different language speakers, and variations in the number of speakers in a recording. Using empirical studies, we provide interesting insights into the effectiveness of different design choices and make recommendations.