 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing information content of representation spaces for disentanglement with VAE ensembles
May 31, 2024



Disentanglement is the endeavour to use machine learning to divide information about a dataset into meaningful fragments. In practice these fragments are representation (sub)spaces, often the set of channels in the latent space of a variational autoencoder (VAE). Assessments of disentanglement predominantly employ metrics that are coarse-grained at the model level, but this approach can obscure much about the process of information fragmentation. Here we propose to study the learned channels in aggregate, as the fragments of information learned by an ensemble of repeat training runs. Additionally, we depart from prior work where measures of similarity between individual subspaces neglected the nature of data embeddings as probability distributions. Instead, we view representation subspaces as communication channels that perform a soft clustering of the data; consequently, we generalize two classic information-theoretic measures of similarity between clustering assignments to compare representation spaces. We develop a lightweight method of estimation based on fingerprinting representation subspaces by their ability to distinguish dataset samples, allowing us to identify, analyze, and leverage meaningful structure in ensembles of VAEs trained on synthetic and natural datasets. Using this fully unsupervised pipeline we identify "hotspots" in the space of information fragments: groups of nearly identical representation subspaces that appear repeatedly in an ensemble of VAEs, particularly as regularization is increased. Finally, we leverage the proposed methodology to achieve ensemble learning with VAEs, boosting the information content of a set of weak learners -- a capability not possible with previous methods of assessing channel similarity.
Machine Learning Without a Processor: Emergent Learning in a Nonlinear Electronic Metamaterial
Nov 01, 2023



Standard deep learning algorithms require differentiating large nonlinear networks, a process that is slow and power-hungry. Electronic learning metamaterials offer potentially fast, efficient, and fault-tolerant hardware for analog machine learning, but existing implementations are linear, severely limiting their capabilities. These systems differ significantly from artificial neural networks as well as the brain, so the feasibility and utility of incorporating nonlinear elements have not been explored. Here we introduce a nonlinear learning metamaterial -- an analog electronic network made of self-adjusting nonlinear resistive elements based on transistors. We demonstrate that the system learns tasks unachievable in linear systems, including XOR and nonlinear regression, without a computer. We find our nonlinear learning metamaterial reduces modes of training error in order (mean, slope, curvature), similar to spectral bias in artificial neural networks. The circuitry is robust to damage, retrainable in seconds, and performs learned tasks in microseconds while dissipating only picojoules of energy across each transistor. This suggests enormous potential for fast, low-power computing in edge systems like sensors, robotic controllers, and medical devices, as well as manufacturability at scale for performing and studying emergent learning.
Bellybutton: Accessible and Customizable Deep-Learning Image Segmentation
Aug 31, 2023The conversion of raw images into quantifiable data can be a major hurdle in experimental research, and typically involves identifying region(s) of interest, a process known as segmentation. Machine learning tools for image segmentation are often specific to a set of tasks, such as tracking cells, or require substantial compute or coding knowledge to train and use. Here we introduce an easy-to-use (no coding required), image segmentation method, using a 15-layer convolutional neural network that can be trained on a laptop: Bellybutton. The algorithm trains on user-provided segmentation of example images, but, as we show, just one or even a portion of one training image can be sufficient in some cases. We detail the machine learning method and give three use cases where Bellybutton correctly segments images despite substantial lighting, shape, size, focus, and/or structure variation across the regions(s) of interest. Instructions for easy download and use, with further details and the datasets used in this paper are available at pypi.org/project/Bellybuttonseg.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Learning Without a Global Clock: Asynchronous Learning in a Physics-Driven Learning Network
Jan 10, 2022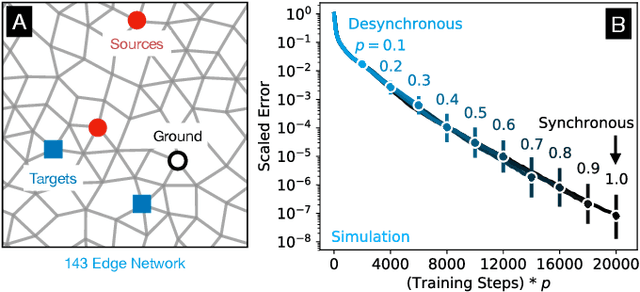
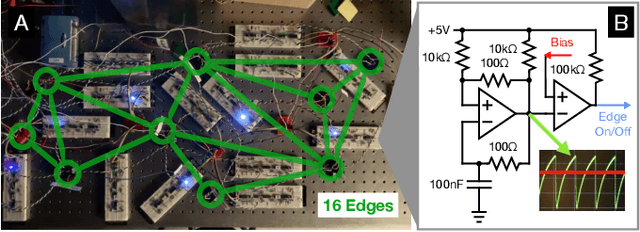
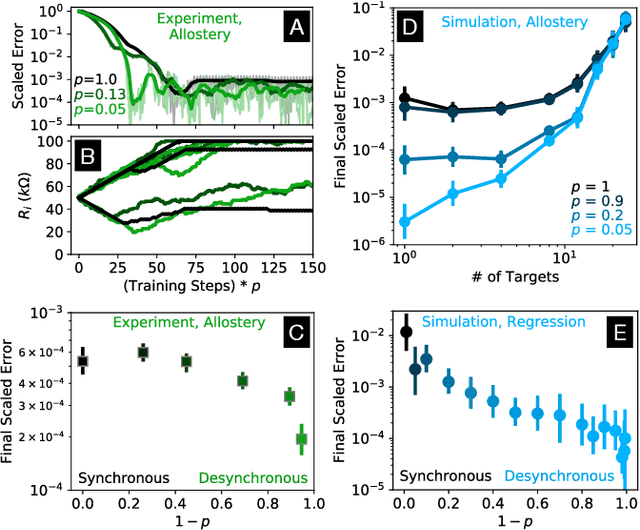
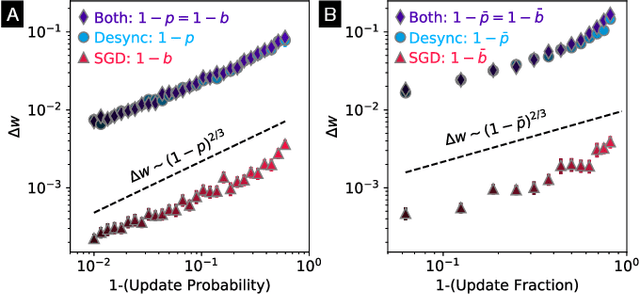
In a neuron network, synapses update individually using local information, allowing for entirely decentralized learning. In contrast, elements in an artificial neural network (ANN) are typically updated simultaneously using a central processor. Here we investigate the feasibility and effect of asynchronous learning in a recently introduced decentralized, physics-driven learning network. We show that desynchronizing the learning process does not degrade performance for a variety of tasks in an idealized simulation. In experiment, desynchronization actually improves performance by allowing the system to better explore the discretized state space of solutions. We draw an analogy between asynchronicity and mini-batching in stochastic gradient descent, and show that they have similar effects on the learning process. Desynchronizing the learning process establishes physics-driven learning networks as truly fully distributed learning machines, promoting better performance and scalability in deployment.