 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefastMRI+: Clinical Pathology Annotations for Knee and Brain Fully Sampled Multi-Coil MRI Data
Sep 14, 2021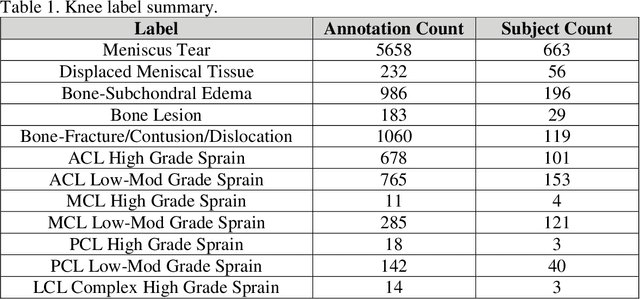
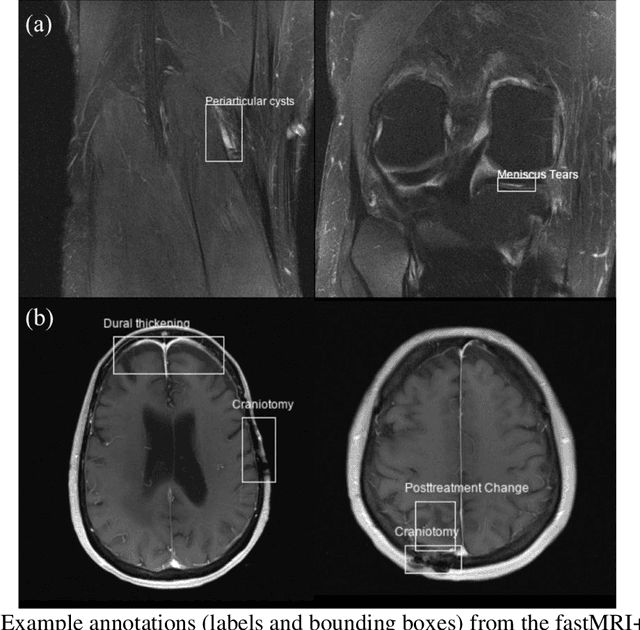
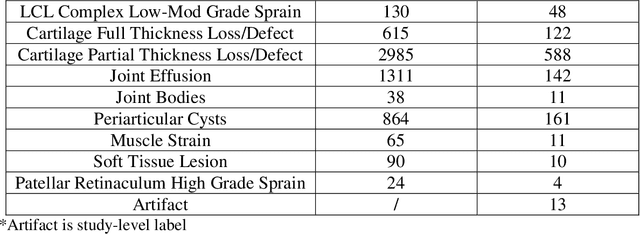
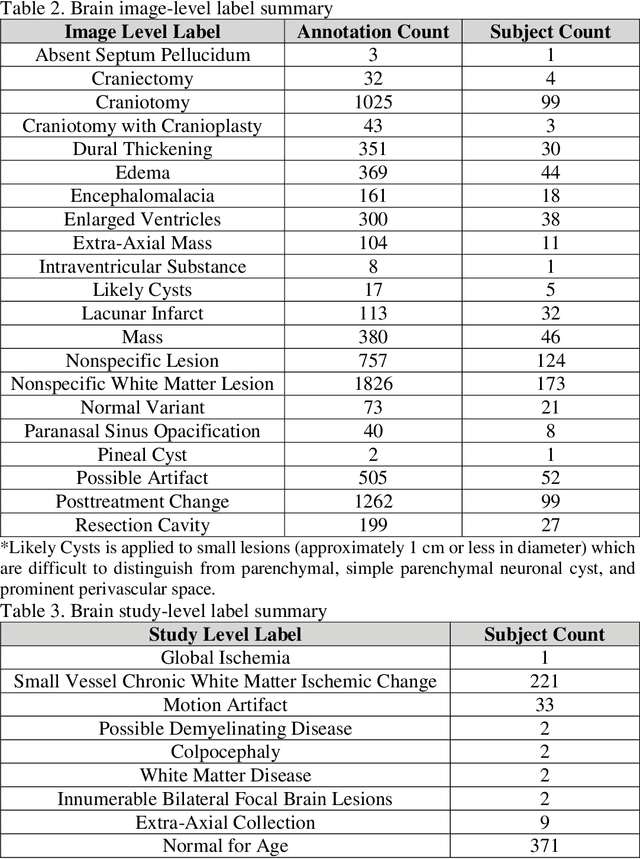
Improving speed and image quality of Magnetic Resonance Imaging (MRI) via novel reconstruction approaches remains one of the highest impact applications for deep learning in medical imaging. The fastMRI dataset, unique in that it contains large volumes of raw MRI data, has enabled significant advances in accelerating MRI using deep learning-based reconstruction methods. While the impact of the fastMRI dataset on the field of medical imaging is unquestioned, the dataset currently lacks clinical expert pathology annotations, critical to addressing clinically relevant reconstruction frameworks and exploring important questions regarding rendering of specific pathology using such novel approaches. This work introduces fastMRI+, which consists of 16154 subspecialist expert bounding box annotations and 13 study-level labels for 22 different pathology categories on the fastMRI knee dataset, and 7570 subspecialist expert bounding box annotations and 643 study-level labels for 30 different pathology categories for the fastMRI brain dataset. The fastMRI+ dataset is open access and aims to support further research and advancement of medical imaging in MRI reconstruction and beyond.
A Theory of Usable Information Under Computational Constraints
Feb 25, 2020


We propose a new framework for reasoning about information in complex systems. Our foundation is based on a variational extension of Shannon's information theory that takes into account the modeling power and computational constraints of the observer. The resulting \emph{predictive $\mathcal{V}$-information} encompasses mutual information and other notions of informativeness such as the coefficient of determination. Unlike Shannon's mutual information and in violation of the data processing inequality, $\mathcal{V}$-information can be created through computation. This is consistent with deep neural networks extracting hierarchies of progressively more informative features in representation learning. Additionally, we show that by incorporating computational constraints, $\mathcal{V}$-information can be reliably estimated from data even in high dimensions with PAC-style guarantees. Empirically, we demonstrate predictive $\mathcal{V}$-information is more effective than mutual information for structure learning and fair representation learning.
Adversarial Constraint Learning for Structured Prediction
May 31, 2018
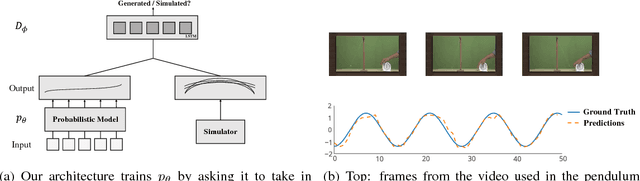
Constraint-based learning reduces the burden of collecting labels by having users specify general properties of structured outputs, such as constraints imposed by physical laws. We propose a novel framework for simultaneously learning these constraints and using them for supervision, bypassing the difficulty of using domain expertise to manually specify constraints. Learning requires a black-box simulator of structured outputs, which generates valid labels, but need not model their corresponding inputs or the input-label relationship. At training time, we constrain the model to produce outputs that cannot be distinguished from simulated labels by adversarial training. Providing our framework with a small number of labeled inputs gives rise to a new semi-supervised structured prediction model; we evaluate this model on multiple tasks --- tracking, pose estimation and time series prediction --- and find that it achieves high accuracy with only a small number of labeled inputs. In some cases, no labels are required at all.
On the Limits of Learning Representations with Label-Based Supervision
Mar 07, 2017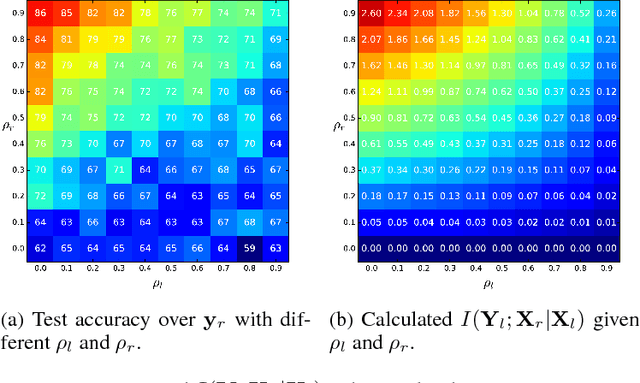

Advances in neural network based classifiers have transformed automatic feature learning from a pipe dream of stronger AI to a routine and expected property of practical systems. Since the emergence of AlexNet every winning submission of the ImageNet challenge has employed end-to-end representation learning, and due to the utility of good representations for transfer learning, representation learning has become as an important and distinct task from supervised learning. At present, this distinction is inconsequential, as supervised methods are state-of-the-art in learning transferable representations. But recent work has shown that generative models can also be powerful agents of representation learning. Will the representations learned from these generative methods ever rival the quality of those from their supervised competitors? In this work, we argue in the affirmative, that from an information theoretic perspective, generative models have greater potential for representation learning. Based on several experimentally validated assumptions, we show that supervised learning is upper bounded in its capacity for representation learning in ways that certain generative models, such as Generative Adversarial Networks (GANs) are not. We hope that our analysis will provide a rigorous motivation for further exploration of generative representation learning.
Label-Free Supervision of Neural Networks with Physics and Domain Knowledge
Sep 18, 2016



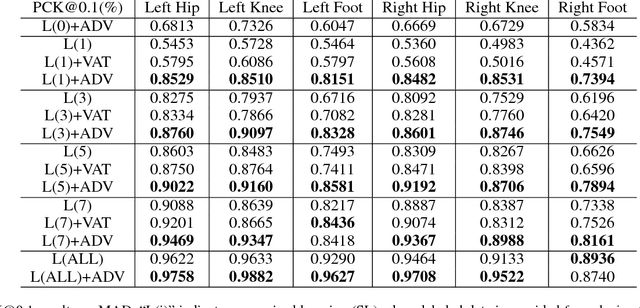
In many machine learning applications, labeled data is scarce and obtaining more labels is expensive. We introduce a new approach to supervising neural networks by specifying constraints that should hold over the output space, rather than direct examples of input-output pairs. These constraints are derived from prior domain knowledge, e.g., from known laws of physics. We demonstrate the effectiveness of this approach on real world and simulated computer vision tasks. We are able to train a convolutional neural network to detect and track objects without any labeled examples. Our approach can significantly reduce the need for labeled training data, but introduces new challenges for encoding prior knowledge into appropriate loss functions.
End-to-end people detection in crowded scenes
Jul 08, 2015



Current people detectors operate either by scanning an image in a sliding window fashion or by classifying a discrete set of proposals. We propose a model that is based on decoding an image into a set of people detections. Our system takes an image as input and directly outputs a set of distinct detection hypotheses. Because we generate predictions jointly, common post-processing steps such as non-maximum suppression are unnecessary. We use a recurrent LSTM layer for sequence generation and train our model end-to-end with a new loss function that operates on sets of detections. We demonstrate the effectiveness of our approach on the challenging task of detecting people in crowded scenes.