 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic and Adaptive Lagrangian Hedging
Feb 03, 2021In online learning an algorithm plays against an environment with losses possibly picked by an adversary at each round. The generality of this framework includes problems that are not adversarial, for example offline optimization, or saddle point problems (i.e. min max optimization). However, online algorithms are typically not designed to leverage additional structure present in non-adversarial problems. Recently, slight modifications to well-known online algorithms such as optimism and adaptive step sizes have been used in several domains to accelerate online learning -- recovering optimal rates in offline smooth optimization, and accelerating convergence to saddle points or social welfare in smooth games. In this work we introduce optimism and adaptive stepsizes to Lagrangian hedging, a class of online algorithms that includes regret-matching, and hedge (i.e. multiplicative weights). Our results include: a general general regret bound; a path length regret bound for a fixed smooth loss, applicable to an optimistic variant of regret-matching and regret-matching+; optimistic regret bounds for $\Phi$ regret, a framework that includes external, internal, and swap regret; and optimistic bounds for a family of algorithms that includes regret-matching+ as a special case.
CDT: Cascading Decision Trees for Explainable Reinforcement Learning
Nov 15, 2020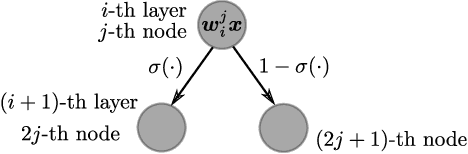
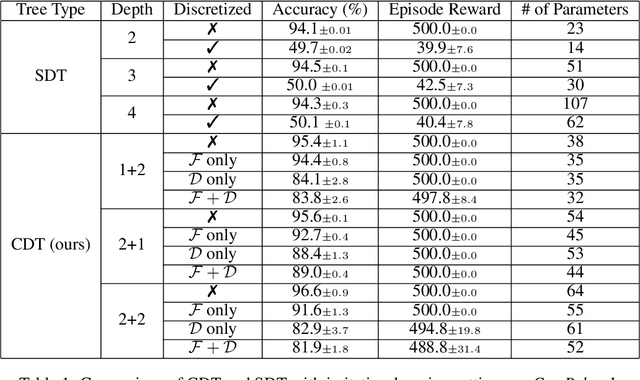
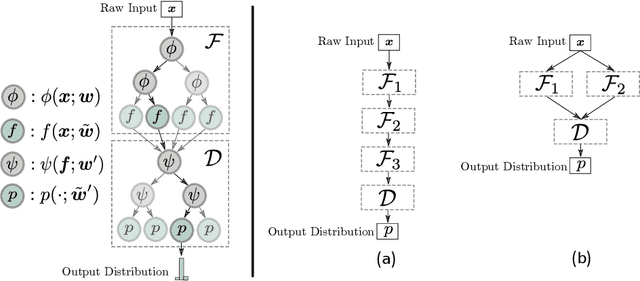
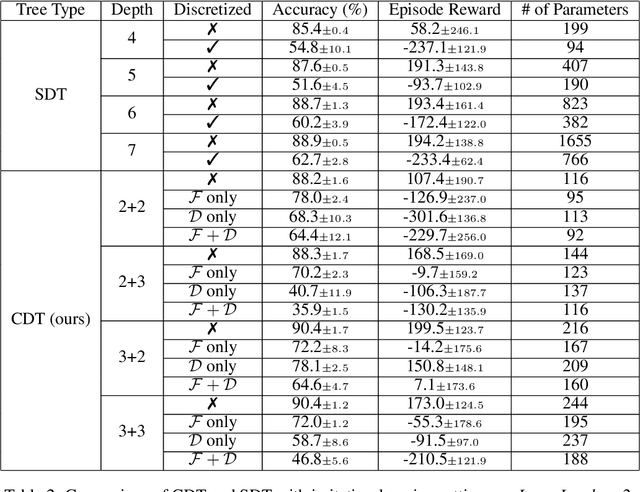
Deep Reinforcement Learning (DRL) has recently achieved significant advances in various domains. However, explaining the policy of RL agents still remains an open problem due to several factors, one being the complexity of explaining neural networks decisions. Recently, a group of works have used decision-tree-based models to learn explainable policies. Soft decision trees (SDTs) and discretized differentiable decision trees (DDTs) have been demonstrated to achieve both good performance and share the benefit of having explainable policies. In this work, we further improve the results for tree-based explainable RL in both performance and explainability. Our proposal, Cascading Decision Trees (CDTs) apply representation learning on the decision path to allow richer expressivity. Empirical results show that in both situations, where CDTs are used as policy function approximators or as imitation learners to explain black-box policies, CDTs can achieve better performances with more succinct and explainable models than SDTs. As a second contribution our study reveals limitations of explaining black-box policies via imitation learning with tree-based explainable models, due to its inherent instability.
On the Sensitivity of Adversarial Robustness to Input Data Distributions
Feb 22, 2019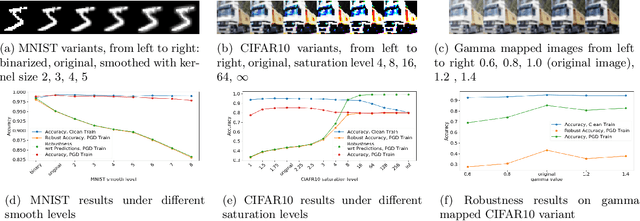
Neural networks are vulnerable to small adversarial perturbations. Existing literature largely focused on understanding and mitigating the vulnerability of learned models. In this paper, we demonstrate an intriguing phenomenon about the most popular robust training method in the literature, adversarial training: Adversarial robustness, unlike clean accuracy, is sensitive to the input data distribution. Even a semantics-preserving transformations on the input data distribution can cause a significantly different robustness for the adversarial trained model that is both trained and evaluated on the new distribution. Our discovery of such sensitivity on data distribution is based on a study which disentangles the behaviors of clean accuracy and robust accuracy of the Bayes classifier. Empirical investigations further confirm our finding. We construct semantically-identical variants for MNIST and CIFAR10 respectively, and show that standardly trained models achieve comparable clean accuracies on them, but adversarially trained models achieve significantly different robustness accuracies. This counter-intuitive phenomenon indicates that input data distribution alone can affect the adversarial robustness of trained neural networks, not necessarily the tasks themselves. Lastly, we discuss the practical implications on evaluating adversarial robustness, and make initial attempts to understand this complex phenomenon.
Max-Margin Adversarial (MMA) Training: Direct Input Space Margin Maximization through Adversarial Training
Dec 06, 2018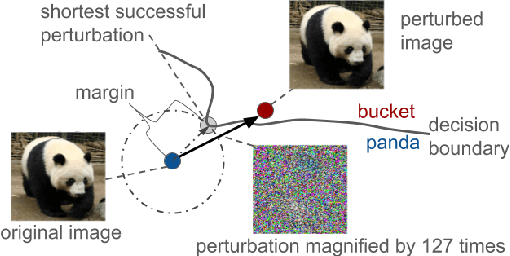
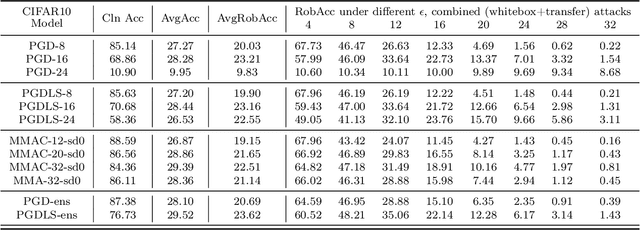
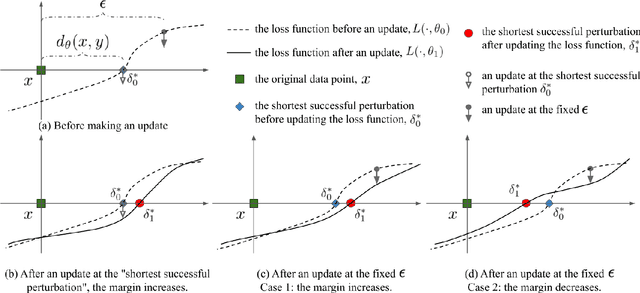
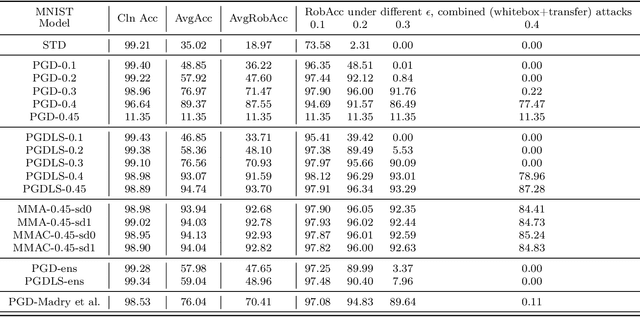
We propose Max-Margin Adversarial (MMA) training for directly maximizing the input space margin. This margin maximization is direct, in the sense that the margin's gradient w.r.t. model parameters can be shown to be parallel with the loss' gradient at the minimal length perturbation, thus gradient ascent on margins can be performed by gradient descent on losses. We further propose a specific formulation of MMA training to maximize the average margin of training examples in order to train models that are robust to adversarial perturbations. It is implemented by performing adversarial training on a novel adaptive norm projected gradient descent (AN-PGD) attack. Preliminary experimental results demonstrate that our method outperforms the existing state of the art methods. In particular, testing against both white-box and transfer projected gradient descent attacks on MNIST, our trained model improves the SOTA $\ell_\infty$ $\epsilon=0.3$ robust accuracy by 2\%, while maintaining the SOTA clean accuracy. Furthermore, the same model provides, to the best of our knowledge, the first model that is robust at $\ell_\infty$ $\epsilon=0.4$, with a robust accuracy of $86.51\%$.
Few-Shot Self Reminder to Overcome Catastrophic Forgetting
Dec 03, 2018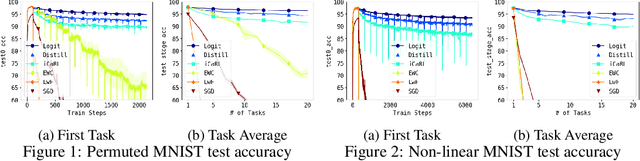
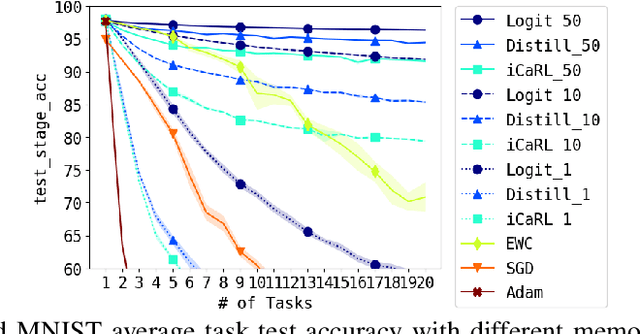
Deep neural networks are known to suffer the catastrophic forgetting problem, where they tend to forget the knowledge from the previous tasks when sequentially learning new tasks. Such failure hinders the application of deep learning based vision system in continual learning settings. In this work, we present a simple yet surprisingly effective way of preventing catastrophic forgetting. Our method, called Few-shot Self Reminder (FSR), regularizes the neural net from changing its learned behaviour by performing logit matching on selected samples kept in episodic memory from the old tasks. Surprisingly, this simplistic approach only requires to retrain a small amount of data in order to outperform previous methods in knowledge retention. We demonstrate the superiority of our method to the previous ones in two different continual learning settings on popular benchmarks, as well as a new continual learning problem where tasks are designed to be more dissimilar.
Dimensionality Reduction has Quantifiable Imperfections: Two Geometric Bounds
Oct 31, 2018
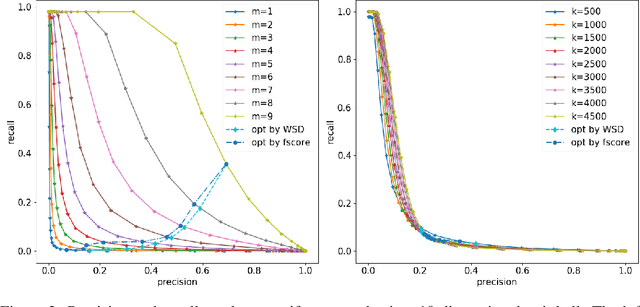
In this paper, we investigate Dimensionality reduction (DR) maps in an information retrieval setting from a quantitative topology point of view. In particular, we show that no DR maps can achieve perfect precision and perfect recall simultaneously. Thus a continuous DR map must have imperfect precision. We further prove an upper bound on the precision of Lipschitz continuous DR maps. While precision is a natural measure in an information retrieval setting, it does not measure `how' wrong the retrieved data is. We therefore propose a new measure based on Wasserstein distance that comes with similar theoretical guarantee. A key technical step in our proofs is a particular optimization problem of the $L_2$-Wasserstein distance over a constrained set of distributions. We provide a complete solution to this optimization problem, which can be of independent interest on the technical side.
* 32nd Conference on Neural Information Processing Systems (NIPS 2018), Montreal, Canada
Improving GAN Training via Binarized Representation Entropy (BRE) Regularization
May 09, 2018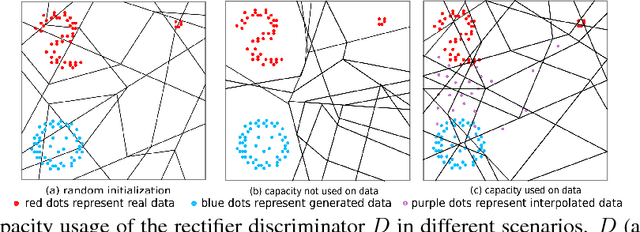
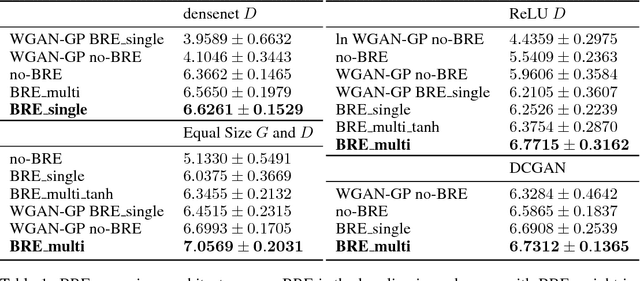
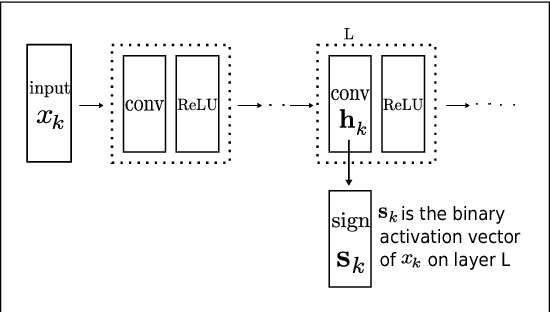
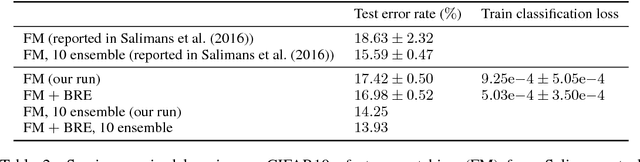
We propose a novel regularizer to improve the training of Generative Adversarial Networks (GANs). The motivation is that when the discriminator D spreads out its model capacity in the right way, the learning signals given to the generator G are more informative and diverse. These in turn help G to explore better and discover the real data manifold while avoiding large unstable jumps due to the erroneous extrapolation made by D. Our regularizer guides the rectifier discriminator D to better allocate its model capacity, by encouraging the binary activation patterns on selected internal layers of D to have a high joint entropy. Experimental results on both synthetic data and real datasets demonstrate improvements in stability and convergence speed of the GAN training, as well as higher sample quality. The approach also leads to higher classification accuracies in semi-supervised learning.
Structured Best Arm Identification with Fixed Confidence
Jun 19, 2017
We study the problem of identifying the best action among a set of possible options when the value of each action is given by a mapping from a number of noisy micro-observables in the so-called fixed confidence setting. Our main motivation is the application to the minimax game search, which has been a major topic of interest in artificial intelligence. In this paper we introduce an abstract setting to clearly describe the essential properties of the problem. While previous work only considered a two-move game tree search problem, our abstract setting can be applied to the general minimax games where the depth can be non-uniform and arbitrary, and transpositions are allowed. We introduce a new algorithm (LUCB-micro) for the abstract setting, and give its lower and upper sample complexity results. Our bounds recover some previous results, which were only available in more limited settings, while they also shed further light on how the structure of minimax problems influence sample complexity.
Revise Saturated Activation Functions
May 02, 2016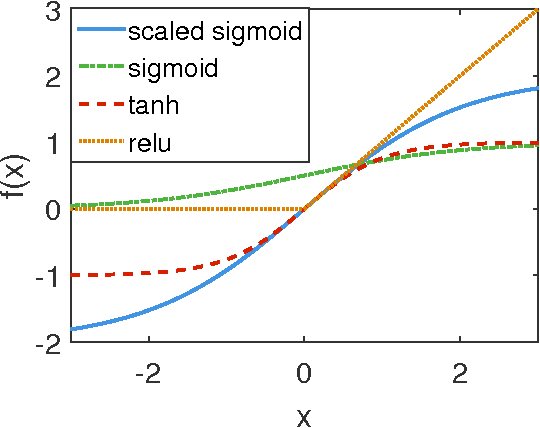
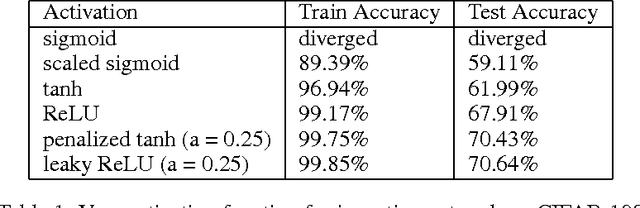
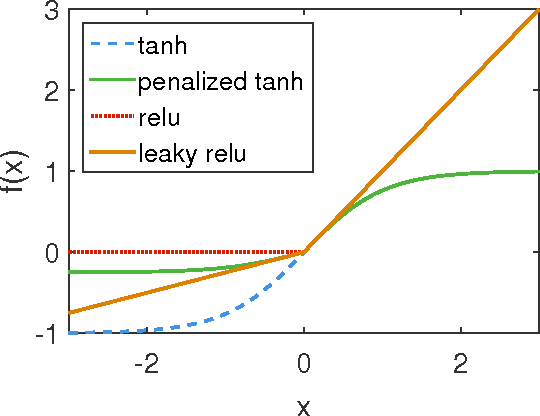

In this paper, we revise two commonly used saturated functions, the logistic sigmoid and the hyperbolic tangent (tanh). We point out that, besides the well-known non-zero centered property, slope of the activation function near the origin is another possible reason making training deep networks with the logistic function difficult to train. We demonstrate that, with proper rescaling, the logistic sigmoid achieves comparable results with tanh. Then following the same argument, we improve tahn by penalizing in the negative part. We show that "penalized tanh" is comparable and even outperforms the state-of-the-art non-saturated functions including ReLU and leaky ReLU on deep convolution neural networks. Our results contradict to the conclusion of previous works that the saturation property causes the slow convergence. It suggests further investigation is necessary to better understand activation functions in deep architectures.
Learning with a Strong Adversary
Jan 16, 2016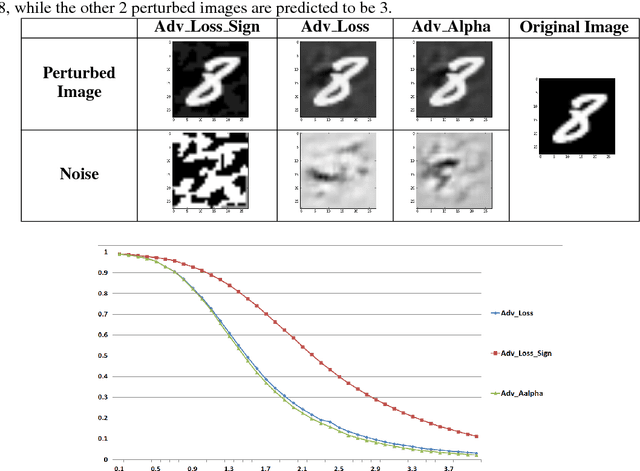
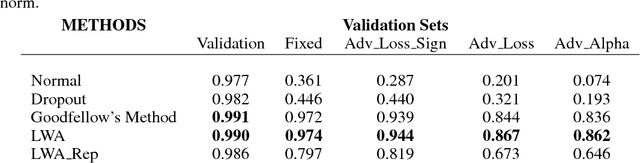
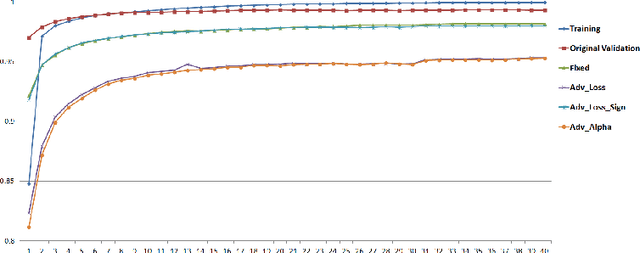
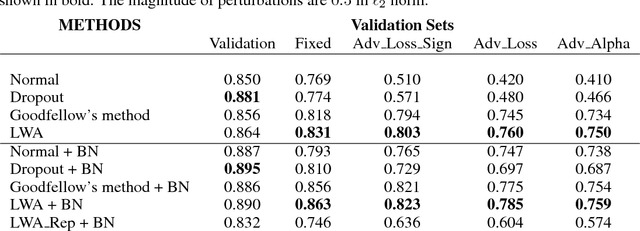
The robustness of neural networks to intended perturbations has recently attracted significant attention. In this paper, we propose a new method, \emph{learning with a strong adversary}, that learns robust classifiers from supervised data. The proposed method takes finding adversarial examples as an intermediate step. A new and simple way of finding adversarial examples is presented and experimentally shown to be efficient. Experimental results demonstrate that resulting learning method greatly improves the robustness of the classification models produced.