 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevise Saturated Activation Functions
Paper and Code
May 02, 2016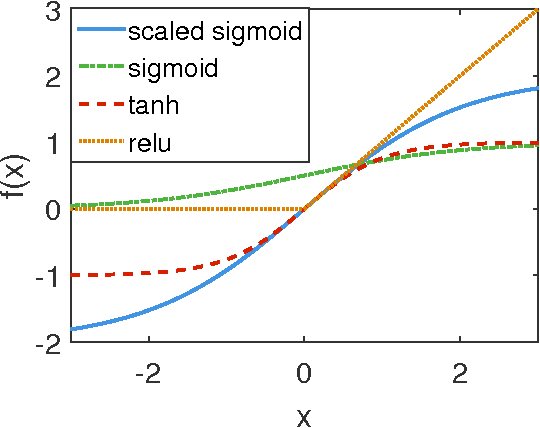
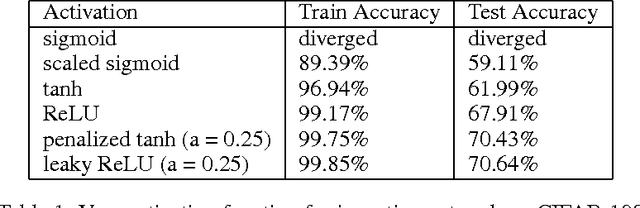
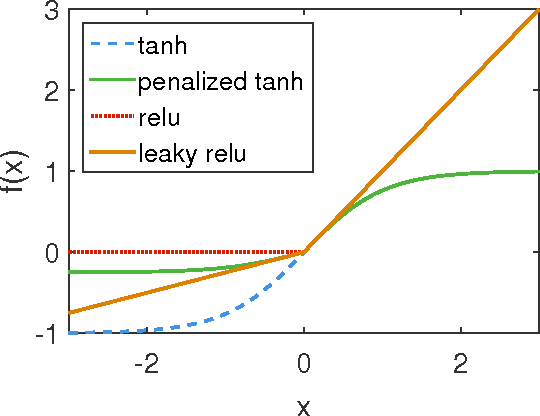

In this paper, we revise two commonly used saturated functions, the logistic sigmoid and the hyperbolic tangent (tanh). We point out that, besides the well-known non-zero centered property, slope of the activation function near the origin is another possible reason making training deep networks with the logistic function difficult to train. We demonstrate that, with proper rescaling, the logistic sigmoid achieves comparable results with tanh. Then following the same argument, we improve tahn by penalizing in the negative part. We show that "penalized tanh" is comparable and even outperforms the state-of-the-art non-saturated functions including ReLU and leaky ReLU on deep convolution neural networks. Our results contradict to the conclusion of previous works that the saturation property causes the slow convergence. It suggests further investigation is necessary to better understand activation functions in deep architectures.