 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProductization Challenges of Contextual Multi-Armed Bandits
Jul 10, 2019
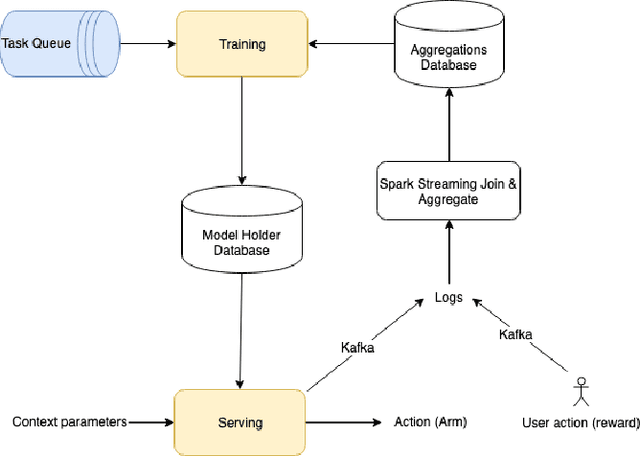
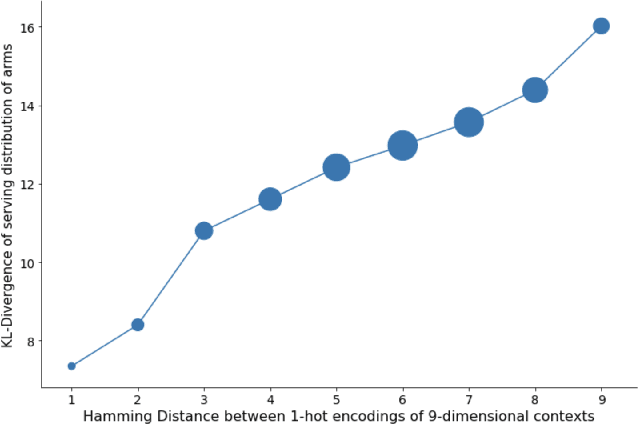
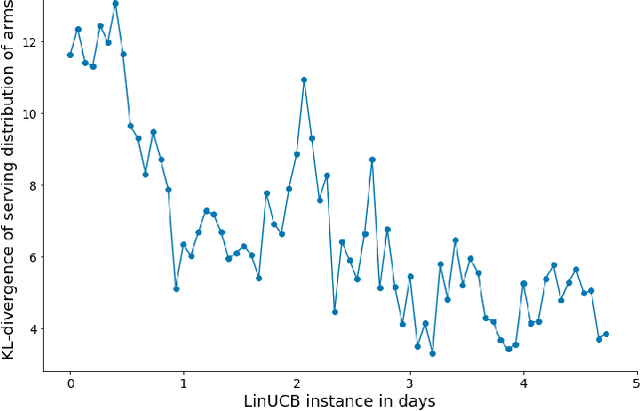
Contextual Multi-Armed Bandits is a well-known and accepted online optimization algorithm, that is used in many Web experiences to tailor content or presentation to users' traffic. Much has been published on theoretical guarantees (e.g. regret bounds) of proposed algorithmic variants, but relatively little attention has been devoted to the challenges encountered while productizing contextual bandits schemes in large scale settings. This work enumerates several productization challenges we encountered while leveraging contextual bandits for two concrete use cases at scale. We discuss how to (1) determine the context (engineer the features) that model the bandit arms; (2) sanity check the health of the optimization process; (3) evaluate the process in an offline manner; (4) add potential actions (arms) on the fly to a running process; (5) subject the decision process to constraints; and (6) iteratively improve the online learning algorithm. For each such challenge, we explain the issue, provide our approach, and relate to prior art where applicable.
Search-Based Serving Architecture of Embeddings-Based Recommendations
Jul 07, 2019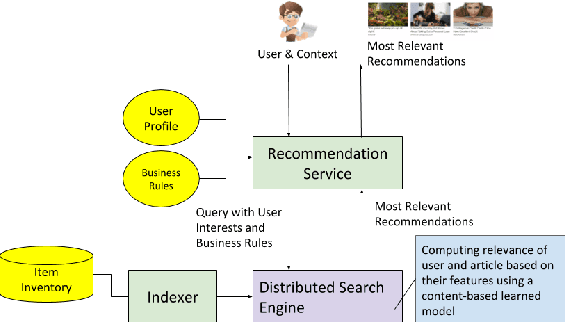
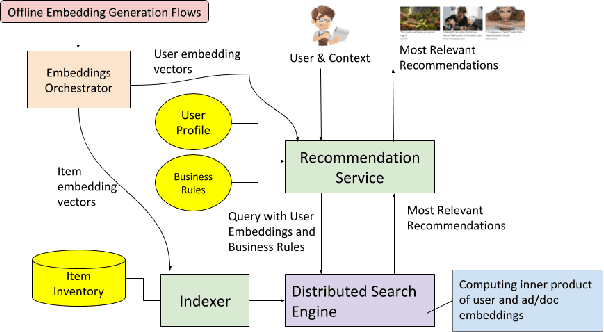
Over the past 10 years, many recommendation techniques have been based on embedding users and items in latent vector spaces, where the inner product of a (user,item) pair of vectors represents the predicted affinity of the user to the item. A wealth of literature has focused on the various modeling approaches that result in embeddings, and has compared their quality metrics, learning complexity, etc. However, much less attention has been devoted to the issues surrounding productization of an embeddings-based high throughput, low latency recommender system. In particular, how the system might keep up with the changing embeddings as new models are learnt. This paper describes a reference architecture of a high-throughput, large scale recommendation service which leverages a search engine as its runtime core. We describe how the search index and the query builder adapt to changes in the embeddings, which often happen at a different cadence than index builds. We provide solutions for both id-based and feature-based embeddings, as well as for batch indexing and incremental indexing setups. The described system is at the core of a Web content discovery service that serves tens of billions recommendations per day in response to billions of user requests.
Budget-Constrained Item Cold-Start Handling in Collaborative Filtering Recommenders via Optimal Design
Sep 20, 2016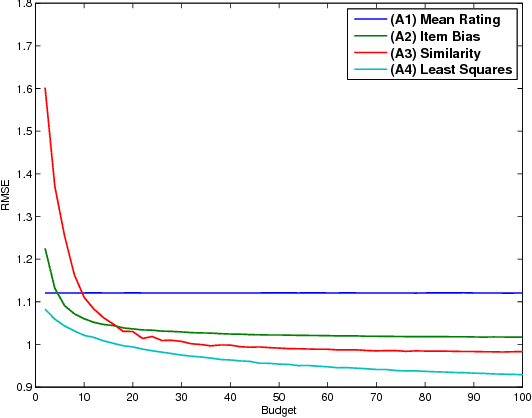
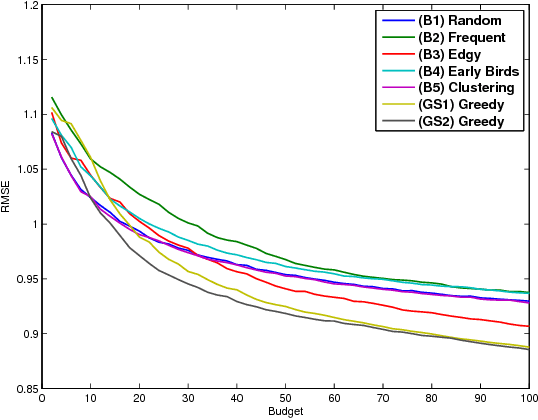
It is well known that collaborative filtering (CF) based recommender systems provide better modeling of users and items associated with considerable rating history. The lack of historical ratings results in the user and the item cold-start problems. The latter is the main focus of this work. Most of the current literature addresses this problem by integrating content-based recommendation techniques to model the new item. However, in many cases such content is not available, and the question arises is whether this problem can be mitigated using CF techniques only. We formalize this problem as an optimization problem: given a new item, a pool of available users, and a budget constraint, select which users to assign with the task of rating the new item in order to minimize the prediction error of our model. We show that the objective function is monotone-supermodular, and propose efficient optimal design based algorithms that attain an approximation to its optimum. Our findings are verified by an empirical study using the Netflix dataset, where the proposed algorithms outperform several baselines for the problem at hand.
Distributed Exploration in Multi-Armed Bandits
Nov 04, 2013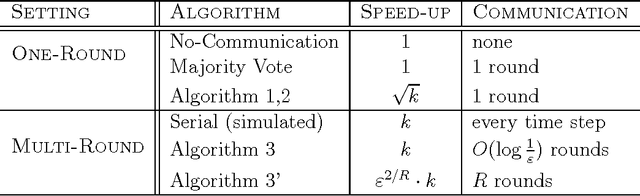
We study exploration in Multi-Armed Bandits in a setting where $k$ players collaborate in order to identify an $\epsilon$-optimal arm. Our motivation comes from recent employment of bandit algorithms in computationally intensive, large-scale applications. Our results demonstrate a non-trivial tradeoff between the number of arm pulls required by each of the players, and the amount of communication between them. In particular, our main result shows that by allowing the $k$ players to communicate only once, they are able to learn $\sqrt{k}$ times faster than a single player. That is, distributing learning to $k$ players gives rise to a factor $\sqrt{k}$ parallel speed-up. We complement this result with a lower bound showing this is in general the best possible. On the other extreme, we present an algorithm that achieves the ideal factor $k$ speed-up in learning performance, with communication only logarithmic in $1/\epsilon$.
OFF-Set: One-pass Factorization of Feature Sets for Online Recommendation in Persistent Cold Start Settings
Aug 08, 2013
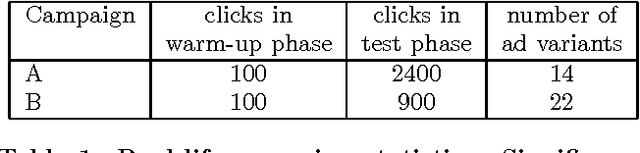
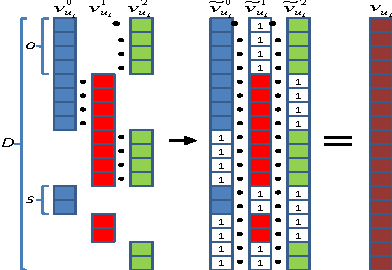
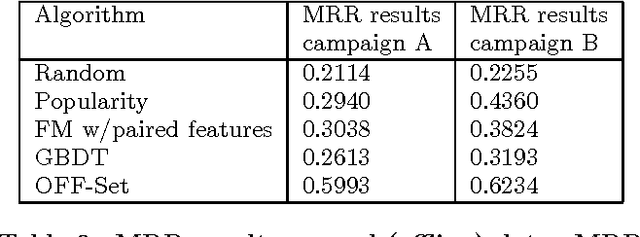
One of the most challenging recommendation tasks is recommending to a new, previously unseen user. This is known as the 'user cold start' problem. Assuming certain features or attributes of users are known, one approach for handling new users is to initially model them based on their features. Motivated by an ad targeting application, this paper describes an extreme online recommendation setting where the cold start problem is perpetual. Every user is encountered by the system just once, receives a recommendation, and either consumes or ignores it, registering a binary reward. We introduce One-pass Factorization of Feature Sets, OFF-Set, a novel recommendation algorithm based on Latent Factor analysis, which models users by mapping their features to a latent space. Furthermore, OFF-Set is able to model non-linear interactions between pairs of features. OFF-Set is designed for purely online recommendation, performing lightweight updates of its model per each recommendation-reward observation. We evaluate OFF-Set against several state of the art baselines, and demonstrate its superiority on real ad-targeting data.