 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Based Serving Architecture of Embeddings-Based Recommendations
Paper and Code
Jul 07, 2019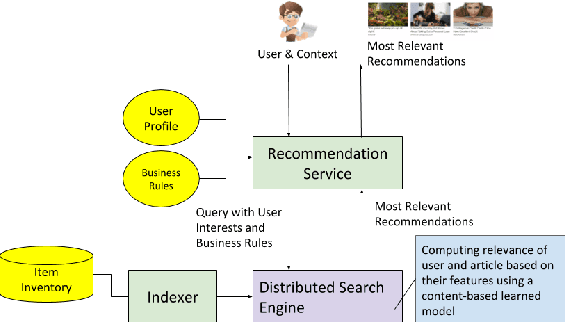
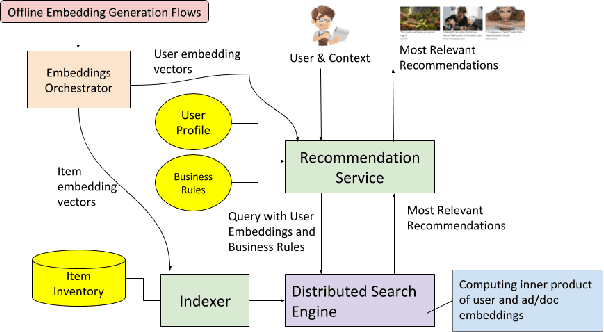
Over the past 10 years, many recommendation techniques have been based on embedding users and items in latent vector spaces, where the inner product of a (user,item) pair of vectors represents the predicted affinity of the user to the item. A wealth of literature has focused on the various modeling approaches that result in embeddings, and has compared their quality metrics, learning complexity, etc. However, much less attention has been devoted to the issues surrounding productization of an embeddings-based high throughput, low latency recommender system. In particular, how the system might keep up with the changing embeddings as new models are learnt. This paper describes a reference architecture of a high-throughput, large scale recommendation service which leverages a search engine as its runtime core. We describe how the search index and the query builder adapt to changes in the embeddings, which often happen at a different cadence than index builds. We provide solutions for both id-based and feature-based embeddings, as well as for batch indexing and incremental indexing setups. The described system is at the core of a Web content discovery service that serves tens of billions recommendations per day in response to billions of user requests.