 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
Budget-Constrained Item Cold-Start Handling in Collaborative Filtering Recommenders via Optimal Design
Sep 20, 2016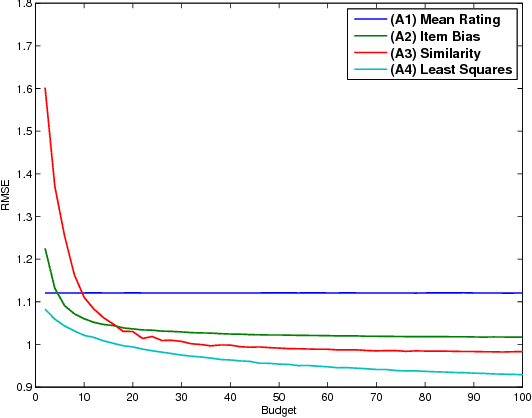
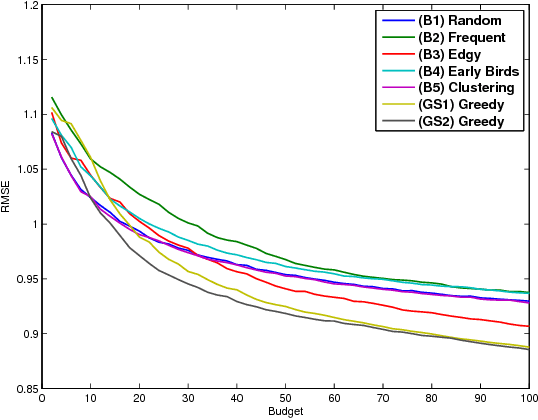
It is well known that collaborative filtering (CF) based recommender systems provide better modeling of users and items associated with considerable rating history. The lack of historical ratings results in the user and the item cold-start problems. The latter is the main focus of this work. Most of the current literature addresses this problem by integrating content-based recommendation techniques to model the new item. However, in many cases such content is not available, and the question arises is whether this problem can be mitigated using CF techniques only. We formalize this problem as an optimization problem: given a new item, a pool of available users, and a budget constraint, select which users to assign with the task of rating the new item in order to minimize the prediction error of our model. We show that the objective function is monotone-supermodular, and propose efficient optimal design based algorithms that attain an approximation to its optimum. Our findings are verified by an empirical study using the Netflix dataset, where the proposed algorithms outperform several baselines for the problem at hand.