 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
Causal Autoregressive Flows
Nov 04, 2020

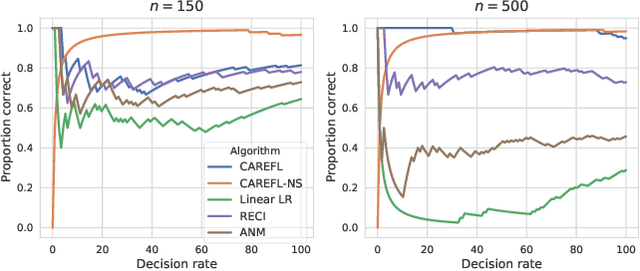

Two apparently unrelated fields -- normalizing flows and causality -- have recently received considerable attention in the machine learning community. In this work, we highlight an intrinsic correspondence between a simple family of flows and identifiable causal models. We exploit the fact that autoregressive flow architectures define an ordering over variables, analogous to a causal ordering, to show that they are well-suited to performing a range of causal inference tasks. First, we show that causal models derived from both affine and additive flows are identifiable. This provides a generalization of the additive noise model well-known in causal discovery. Second, we derive a bivariate measure of causal direction based on likelihood ratios, leveraging the fact that flow models estimate normalized log-densities of data. Such likelihood ratios have well-known optimality properties in finite-sample inference. Third, we demonstrate that the invertibility of flows naturally allows for direct evaluation of both interventional and counterfactual queries. Finally, throughout a series of experiments on synthetic and real data, the proposed method is shown to outperform current approaches for causal discovery as well as making accurate interventional and counterfactual predictions.
Autoregressive flow-based causal discovery and inference
Jul 26, 2020

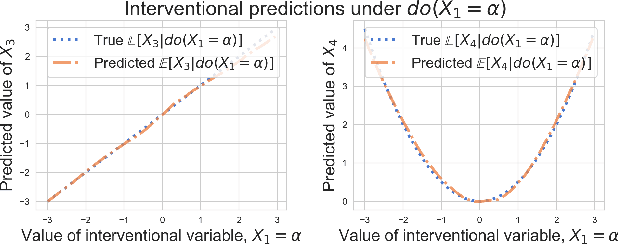
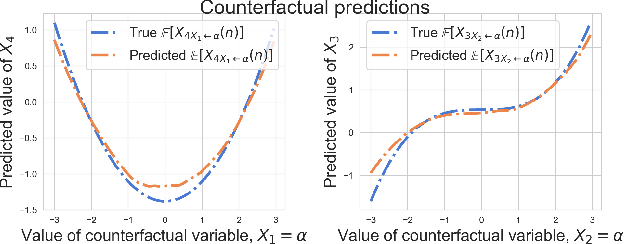
We posit that autoregressive flow models are well-suited to performing a range of causal inference tasks - ranging from causal discovery to making interventional and counterfactual predictions. In particular, we exploit the fact that autoregressive architectures define an ordering over variables, analogous to a causal ordering, in order to propose a single flow architecture to perform all three aforementioned tasks. We first leverage the fact that flow models estimate normalized log-densities of data to derive a bivariate measure of causal direction based on likelihood ratios. Whilst traditional measures of causal direction often require restrictive assumptions on the nature of causal relationships (e.g., linearity),the flexibility of flow models allows for arbitrary causal dependencies. Our approach compares favourably against alternative methods on synthetic data as well as on the Cause-Effect Pairs bench-mark dataset. Subsequently, we demonstrate that the invertible nature of flows naturally allows for direct evaluation of both interventional and counterfactual predictions, which require marginalization and conditioning over latent variables respectively. We present examples over synthetic data where autoregressive flows, when trained under the correct causal ordering, are able to make accurate interventional and counterfactual predictions
Bayesian optimization for automatic design of face stimuli
Jul 20, 2020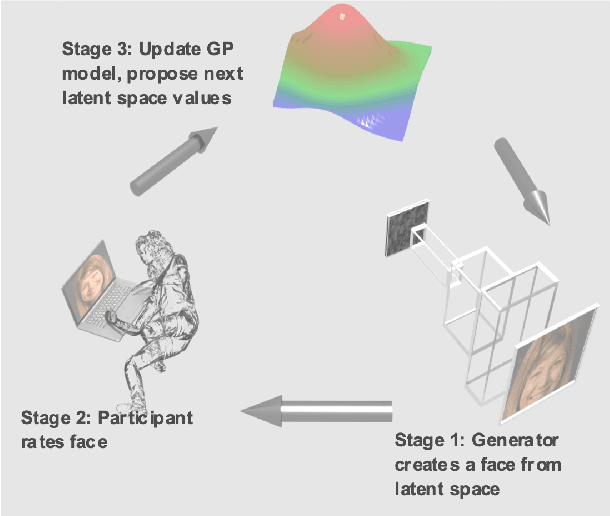
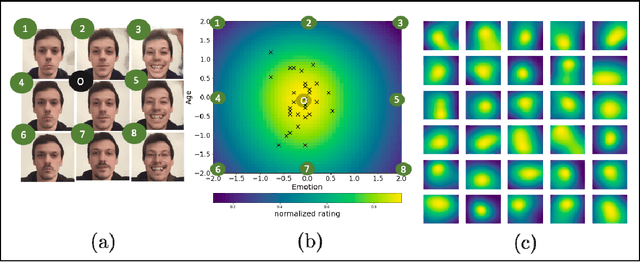
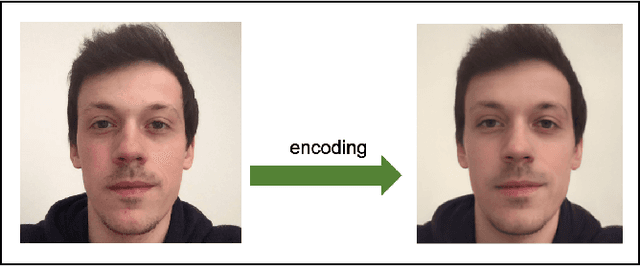

Investigating the cognitive and neural mechanisms involved with face processing is a fundamental task in modern neuroscience and psychology. To date, the majority of such studies have focused on the use of pre-selected stimuli. The absence of personalized stimuli presents a serious limitation as it fails to account for how each individual face processing system is tuned to cultural embeddings or how it is disrupted in disease. In this work, we propose a novel framework which combines generative adversarial networks (GANs) with Bayesian optimization to identify individual response patterns to many different faces. Formally, we employ Bayesian optimization to efficiently search the latent space of state-of-the-art GAN models, with the aim to automatically generate novel faces, to maximize an individual subject's response. We present results from a web-based proof-of-principle study, where participants rated images of themselves generated via performing Bayesian optimization over the latent space of a GAN. We show how the algorithm can efficiently locate an individual's optimal face while mapping out their response across different semantic transformations of a face; inter-individual analyses suggest how the approach can provide rich information about individual differences in face processing.
ICE-BeeM: Identifiable Conditional Energy-Based Deep Models
Feb 26, 2020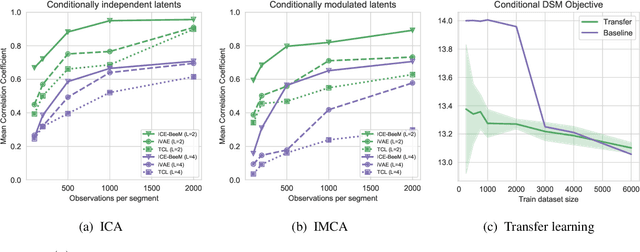

Despite the growing popularity of energy-based models, their identifiability properties are not well-understood. In this paper we establish sufficient conditions under which a large family of conditional energy-based models is identifiable in function space, up to a simple transformation. Our results build on recent developments in the theory of nonlinear ICA, showing that the latent representations in certain families of deep latent-variable models are identifiable. We extend these results to a very broad family of conditional energy-based models. In this family, the energy function is simply the dot-product between two feature extractors, one for the dependent variable, and one for the conditioning variable. We show that under mild conditions, the features are unique up to scaling and permutation. Second, we propose the framework of independently modulated component analysis (IMCA), a new form of nonlinear ICA where the indepencence assumption is relaxed. Importantly, we show that our energy-based model can be used for the estimation of the components: the features learned are a simple and often trivial transformation of the latents.
Causal Discovery with General Non-Linear Relationships Using Non-Linear ICA
Apr 19, 2019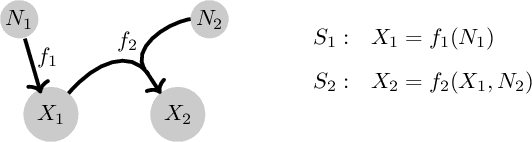
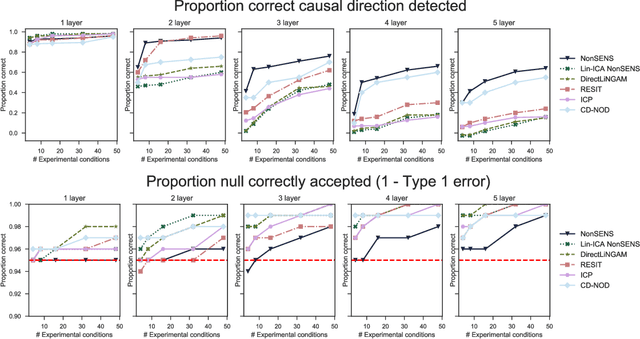
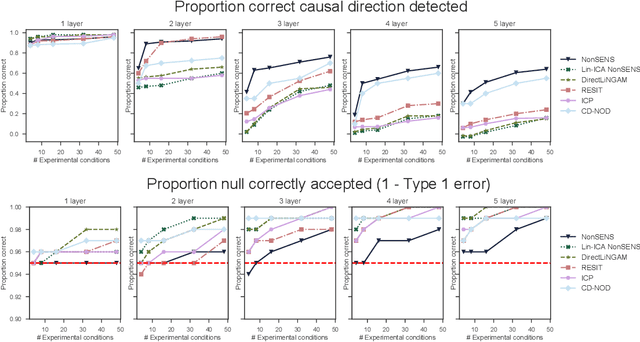
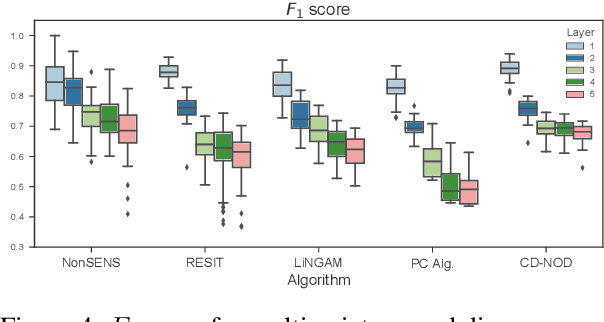
We consider the problem of inferring causal relationships between two or more passively observed variables. While the problem of such causal discovery has been extensively studied especially in the bivariate setting, the majority of current methods assume a linear causal relationship, and the few methods which consider non-linear dependencies usually make the assumption of additive noise. Here, we propose a framework through which we can perform causal discovery in the presence of general non-linear relationships. The proposed method is based on recent progress in non-linear independent component analysis and exploits the non-stationarity of observations in order to recover the underlying sources or latent disturbances. We show rigorously that in the case of bivariate causal discovery, such non-linear ICA can be used to infer the causal direction via a series of independence tests. We further propose an alternative measure of causal direction based on asymptotic approximations to the likelihood ratio, as well as an extension to multivariate causal discovery. We demonstrate the capabilities of the proposed method via a series of simulation studies and conclude with an application to neuroimaging data.
A Unified Probabilistic Model for Learning Latent Factors and Their Connectivities from High-Dimensional Data
May 24, 2018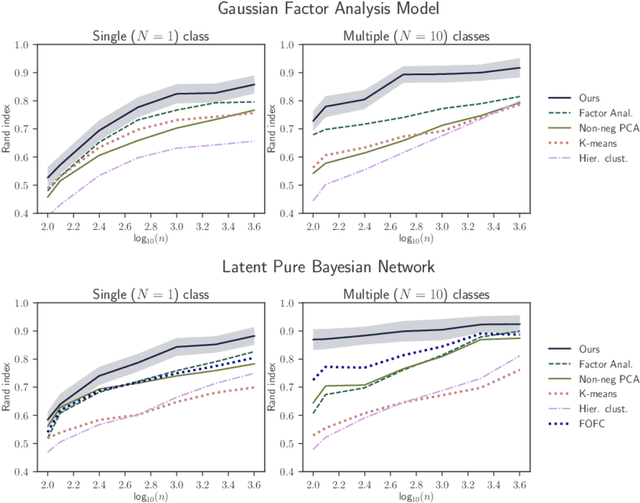
Connectivity estimation is challenging in the context of high-dimensional data. A useful preprocessing step is to group variables into clusters, however, it is not always clear how to do so from the perspective of connectivity estimation. Another practical challenge is that we may have data from multiple related classes (e.g., multiple subjects or conditions) and wish to incorporate constraints on the similarities across classes. We propose a probabilistic model which simultaneously performs both a grouping of variables (i.e., detecting community structure) and estimation of connectivities between the groups which correspond to latent variables. The model is essentially a factor analysis model where the factors are allowed to have arbitrary correlations, while the factor loading matrix is constrained to express a community structure. The model can be applied on multiple classes so that the connectivities can be different between the classes, while the community structure is the same for all classes. We propose an efficient estimation algorithm based on score matching, and prove the identifiability of the model. Finally, we present an extension to directed (causal) connectivities over latent variables. Simulations and experiments on fMRI data validate the practical utility of the method.
Adaptive regularization for Lasso models in the context of non-stationary data streams
Dec 14, 2017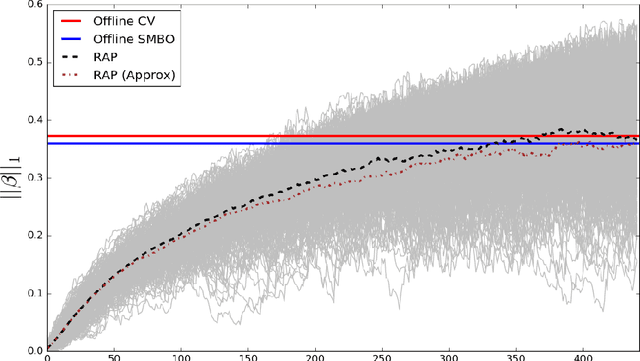
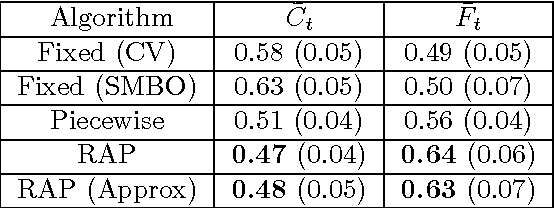
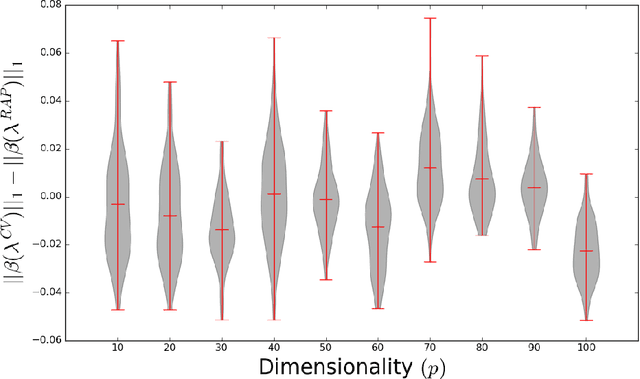
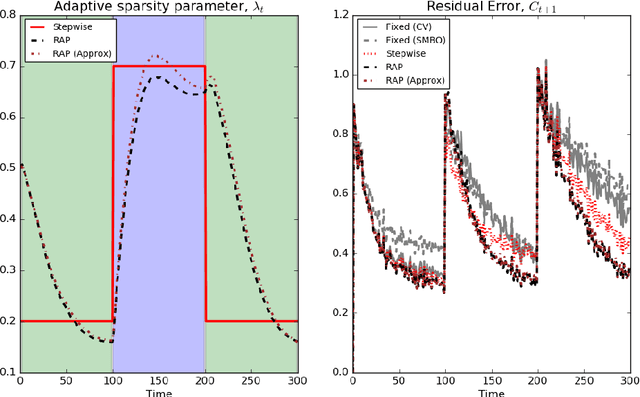
Large scale, streaming datasets are ubiquitous in modern machine learning. Streaming algorithms must be scalable, amenable to incremental training and robust to the presence of non-stationarity. In this work consider the problem of learning $\ell_1$ regularized linear models in the context of streaming data. In particular, the focus of this work revolves around how to select the regularization parameter when data arrives sequentially and the underlying distribution is non-stationary (implying the choice of optimal regularization parameter is itself time-varying). We propose a framework through which to infer an adaptive regularization parameter. Our approach employs an $\ell_1$ penalty constraint where the corresponding sparsity parameter is iteratively updated via stochastic gradient descent. This serves to reformulate the choice of regularization parameter in a principled framework for online learning. The proposed method is derived for linear regression and subsequently extended to generalized linear models. We validate our approach using simulated and real datasets and present an application to a neuroimaging dataset.
Streaming regularization parameter selection via stochastic gradient descent
Nov 02, 2016We propose a framework to perform streaming covariance selection. Our approach employs regularization constraints where a time-varying sparsity parameter is iteratively estimated via stochastic gradient descent. This allows for the regularization parameter to be efficiently learnt in an online manner. The proposed framework is developed for linear regression models and extended to graphical models via neighbourhood selection. Under mild assumptions, we are able to obtain convergence results in a non-stochastic setting. The capabilities of such an approach are demonstrated using both synthetic data as well as neuroimaging data.