 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Independent Component Analysis for Principled Disentanglement in Unsupervised Deep Learning
Mar 29, 2023A central problem in unsupervised deep learning is how to find useful representations of high-dimensional data, sometimes called "disentanglement". Most approaches are heuristic and lack a proper theoretical foundation. In linear representation learning, independent component analysis (ICA) has been successful in many applications areas, and it is principled, i.e. based on a well-defined probabilistic model. However, extension of ICA to the nonlinear case has been problematic due to the lack of identifiability, i.e. uniqueness of the representation. Recently, nonlinear extensions that utilize temporal structure or some auxiliary information have been proposed. Such models are in fact identifiable, and consequently, an increasing number of algorithms have been developed. In particular, some self-supervised algorithms can be shown to estimate nonlinear ICA, even though they have initially been proposed from heuristic perspectives. This paper reviews the state-of-the-art of nonlinear ICA theory and algorithms.
Identifiability of latent-variable and structural-equation models: from linear to nonlinear
Feb 06, 2023



An old problem in multivariate statistics is that linear Gaussian models are often unidentifiable, i.e. some parameters cannot be uniquely estimated. In factor analysis, an orthogonal rotation of the factors is unidentifiable, while in linear regression, the direction of effect cannot be identified. For such linear models, non-Gaussianity of the (latent) variables has been shown to provide identifiability. In the case of factor analysis, this leads to independent component analysis, while in the case of the direction of effect, non-Gaussian versions of structural equation modelling solve the problem. More recently, we have shown how even general nonparametric nonlinear versions of such models can be estimated. Non-Gaussianity is not enough in this case, but assuming we have time series, or that the distributions are suitably modulated by some observed auxiliary variables, the models are identifiable. This paper reviews the identifiability theory for the linear and nonlinear cases, considering both factor analytic models and structural equation models.
Causal Autoregressive Flows
Nov 04, 2020

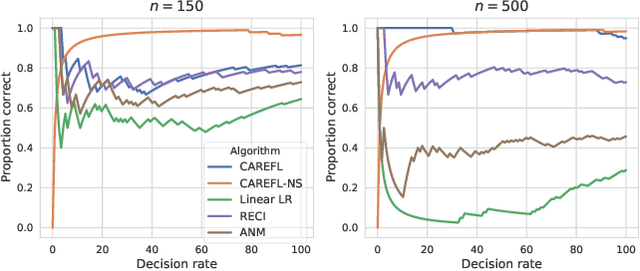

Two apparently unrelated fields -- normalizing flows and causality -- have recently received considerable attention in the machine learning community. In this work, we highlight an intrinsic correspondence between a simple family of flows and identifiable causal models. We exploit the fact that autoregressive flow architectures define an ordering over variables, analogous to a causal ordering, to show that they are well-suited to performing a range of causal inference tasks. First, we show that causal models derived from both affine and additive flows are identifiable. This provides a generalization of the additive noise model well-known in causal discovery. Second, we derive a bivariate measure of causal direction based on likelihood ratios, leveraging the fact that flow models estimate normalized log-densities of data. Such likelihood ratios have well-known optimality properties in finite-sample inference. Third, we demonstrate that the invertibility of flows naturally allows for direct evaluation of both interventional and counterfactual queries. Finally, throughout a series of experiments on synthetic and real data, the proposed method is shown to outperform current approaches for causal discovery as well as making accurate interventional and counterfactual predictions.
Autoregressive flow-based causal discovery and inference
Jul 26, 2020

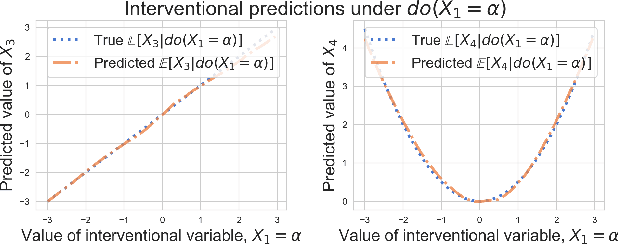
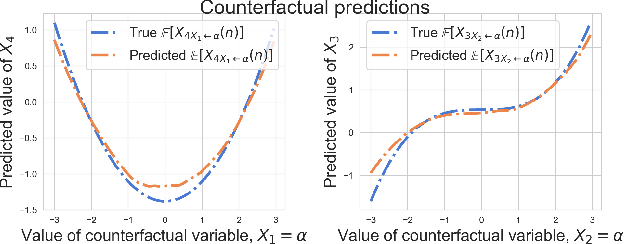
We posit that autoregressive flow models are well-suited to performing a range of causal inference tasks - ranging from causal discovery to making interventional and counterfactual predictions. In particular, we exploit the fact that autoregressive architectures define an ordering over variables, analogous to a causal ordering, in order to propose a single flow architecture to perform all three aforementioned tasks. We first leverage the fact that flow models estimate normalized log-densities of data to derive a bivariate measure of causal direction based on likelihood ratios. Whilst traditional measures of causal direction often require restrictive assumptions on the nature of causal relationships (e.g., linearity),the flexibility of flow models allows for arbitrary causal dependencies. Our approach compares favourably against alternative methods on synthetic data as well as on the Cause-Effect Pairs bench-mark dataset. Subsequently, we demonstrate that the invertible nature of flows naturally allows for direct evaluation of both interventional and counterfactual predictions, which require marginalization and conditioning over latent variables respectively. We present examples over synthetic data where autoregressive flows, when trained under the correct causal ordering, are able to make accurate interventional and counterfactual predictions
ICE-BeeM: Identifiable Conditional Energy-Based Deep Models
Feb 26, 2020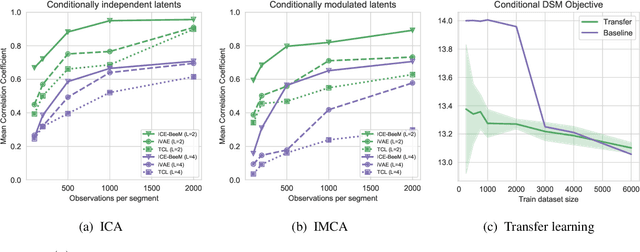

Despite the growing popularity of energy-based models, their identifiability properties are not well-understood. In this paper we establish sufficient conditions under which a large family of conditional energy-based models is identifiable in function space, up to a simple transformation. Our results build on recent developments in the theory of nonlinear ICA, showing that the latent representations in certain families of deep latent-variable models are identifiable. We extend these results to a very broad family of conditional energy-based models. In this family, the energy function is simply the dot-product between two feature extractors, one for the dependent variable, and one for the conditioning variable. We show that under mild conditions, the features are unique up to scaling and permutation. Second, we propose the framework of independently modulated component analysis (IMCA), a new form of nonlinear ICA where the indepencence assumption is relaxed. Importantly, we show that our energy-based model can be used for the estimation of the components: the features learned are a simple and often trivial transformation of the latents.
Variational Autoencoders and Nonlinear ICA: A Unifying Framework
Jul 10, 2019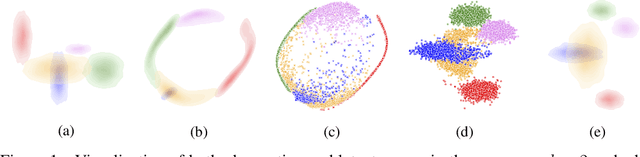
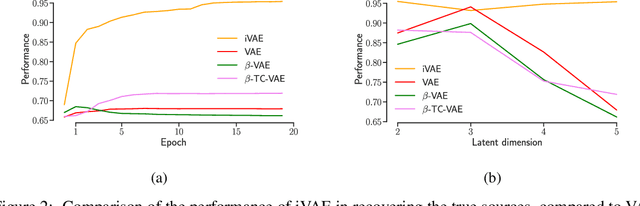
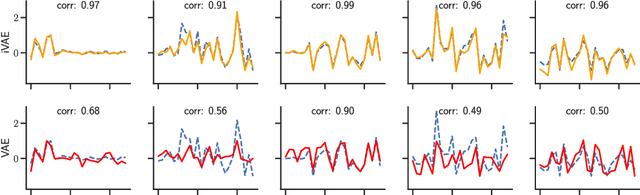
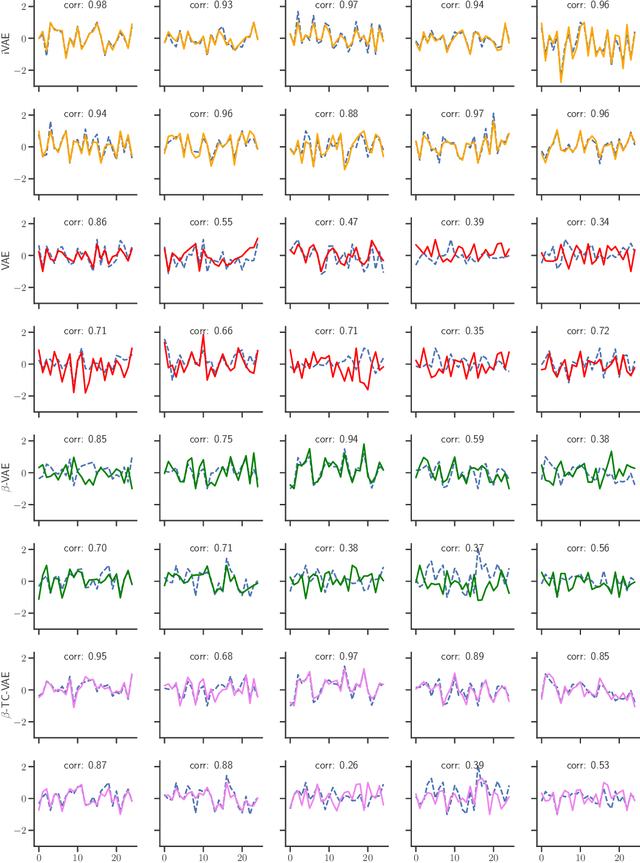
The framework of variational autoencoders allows us to efficiently learn deep latent-variable models, such that the model's marginal distribution over observed variables fits the data. Often, we're interested in going a step further, and want to approximate the true joint distribution over observed and latent variables, including the true prior and posterior distributions over latent variables. This is known to be generally impossible due to unidentifiability of the model. We address this issue by showing that for a broad family of deep latent-variable models, identification of the true joint distribution over observed and latent variables is actually possible up to a simple transformation, thus achieving a principled and powerful form of disentanglement. Our result requires a factorized prior distribution over the latent variables that is conditioned on an additionally observed variable, such as a class label or almost any other observation. We build on recent developments in nonlinear ICA, which we extend to the case with noisy, undercomplete or discrete observations, integrated in a maximum likelihood framework. The result also trivially contains identifiable flow-based generative models as a special case.