 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Environments for Vehicle Routing Problems
Nov 21, 2024Research on Reinforcement Learning (RL) approaches for discrete optimization problems has increased considerably, extending RL to an area classically dominated by Operations Research (OR). Vehicle routing problems are a good example of discrete optimization problems with high practical relevance where RL techniques have had considerable success. Despite these advances, open-source development frameworks remain scarce, hampering both the testing of algorithms and the ability to objectively compare results. This ultimately slows down progress in the field and limits the exchange of ideas between the RL and OR communities. Here we propose a library composed of multi-agent environments that simulates classic vehicle routing problems. The library, built on PyTorch, provides a flexible modular architecture design that allows easy customization and incorporation of new routing problems. It follows the Agent Environment Cycle ("AEC") games model and has an intuitive API, enabling rapid adoption and easy integration into existing reinforcement learning frameworks. The library allows for a straightforward use of classical OR benchmark instances in order to narrow the gap between the test beds for algorithm benchmarking used by the RL and OR communities. Additionally, we provide benchmark instance sets for each environment, as well as baseline RL models and training code.
The First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022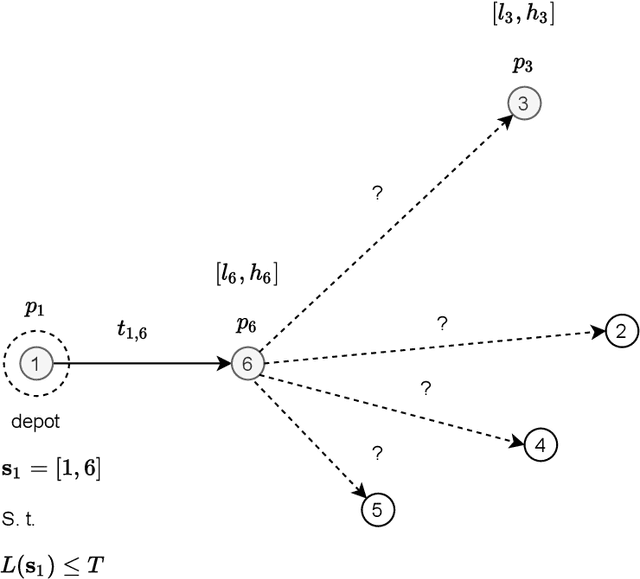
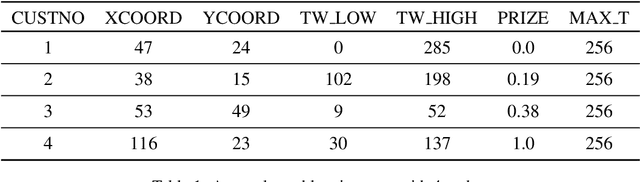

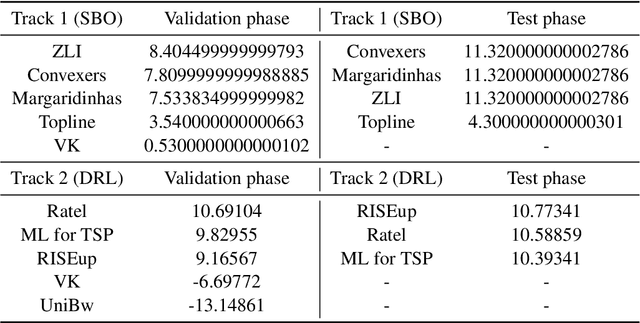
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
A Reinforcement Learning Approach to the Orienteering Problem with Time Windows
Nov 07, 2020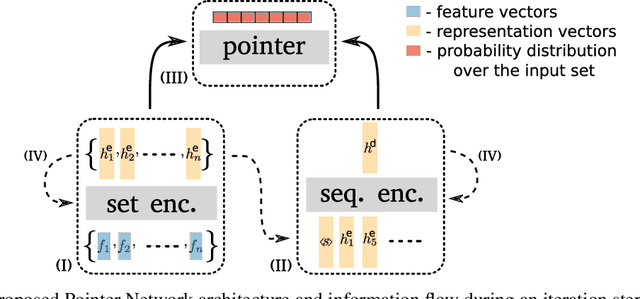
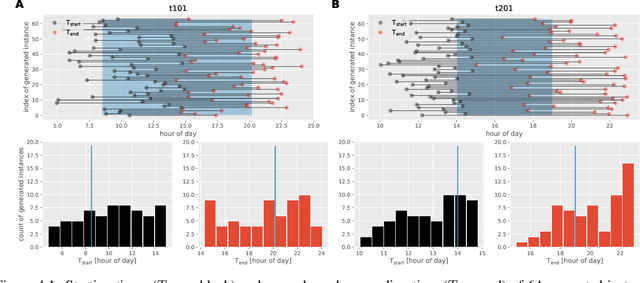
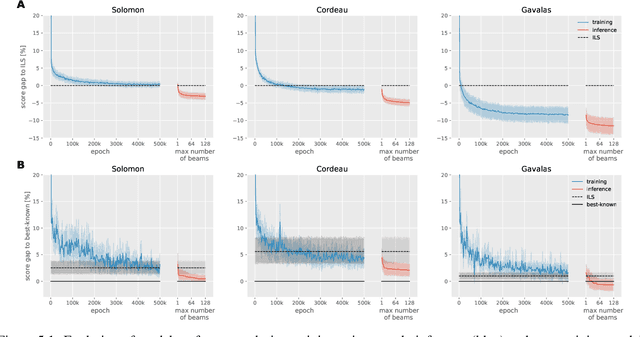
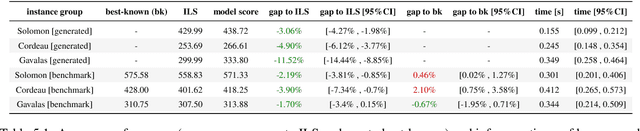
The Orienteering Problem with Time Windows (OPTW) is a combinatorial optimization problem where the goal is to maximize the total scores collected from visited locations, under some time constraints. Several heuristics have been proposed for the OPTW, yet in comparison with machine learning models, a heuristic typically has a smaller potential for generalization and personalization. The application of neural network models to combinatorial optimization has recently shown promising results in similar problems like the Travelling Salesman Problem. A neural network allows learning solutions using reinforcement learning or in a supervised way, depending on the available data. After learning, it can potentially generalize and be quickly fine-tuned to further improve performance and personalization. This is advantageous since, for real word applications, a solution's quality, personalization and execution times are all important factors to be taken into account. Here we explore the use of Pointer Network models trained with reinforcement learning for solving the OPTW problem. Among its various applications, the OPTW can be used to model the Tourist Trip Design Problem (TTDP). We train the Pointer Network with the TTDP problem in mind, by sampling variables that can change across tourists for a particular instance-region: starting position, starting time, time available and the scores of each point of interest. After a model-region is trained it can infer a solution for a particular tourist using beam search. We evaluate our approach on several existing benchmark OPTW instances. We show that it is able to generalize across different generated tourists for each region and that it generally outperforms the most commonly used heuristic while computing the solution in realistic times.