 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Environments for Vehicle Routing Problems
Nov 21, 2024Research on Reinforcement Learning (RL) approaches for discrete optimization problems has increased considerably, extending RL to an area classically dominated by Operations Research (OR). Vehicle routing problems are a good example of discrete optimization problems with high practical relevance where RL techniques have had considerable success. Despite these advances, open-source development frameworks remain scarce, hampering both the testing of algorithms and the ability to objectively compare results. This ultimately slows down progress in the field and limits the exchange of ideas between the RL and OR communities. Here we propose a library composed of multi-agent environments that simulates classic vehicle routing problems. The library, built on PyTorch, provides a flexible modular architecture design that allows easy customization and incorporation of new routing problems. It follows the Agent Environment Cycle ("AEC") games model and has an intuitive API, enabling rapid adoption and easy integration into existing reinforcement learning frameworks. The library allows for a straightforward use of classical OR benchmark instances in order to narrow the gap between the test beds for algorithm benchmarking used by the RL and OR communities. Additionally, we provide benchmark instance sets for each environment, as well as baseline RL models and training code.
Solving the Team Orienteering Problem with Transformers
Dec 01, 2023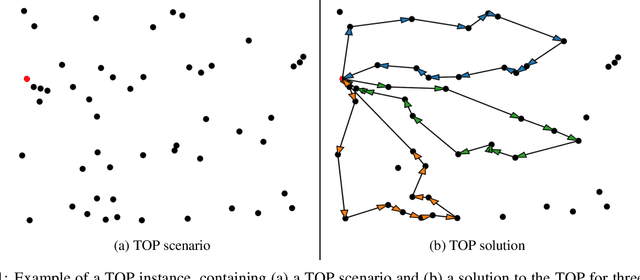
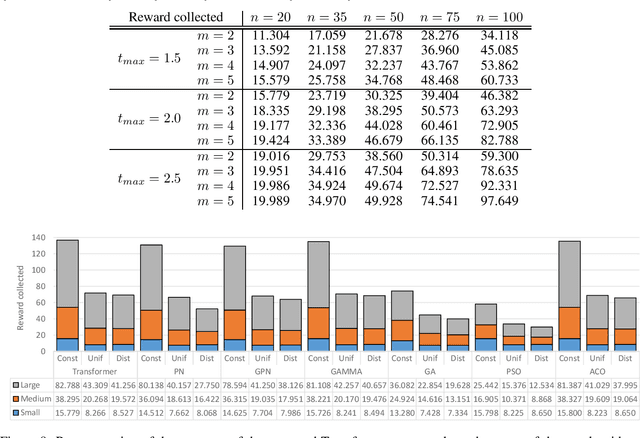
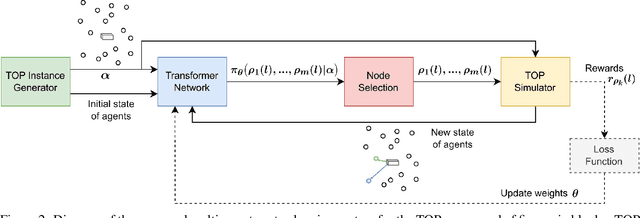
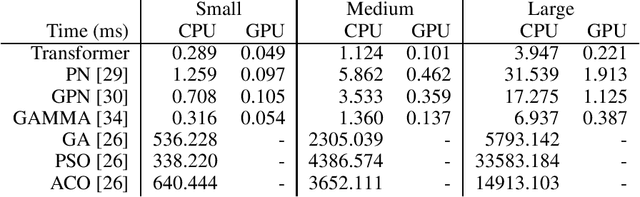
Route planning for a fleet of vehicles is an important task in applications such as package delivery, surveillance, or transportation. This problem is usually modeled as a Combinatorial Optimization problem named as Team Orienteering Problem. The most popular Team Orienteering Problem solvers are mainly based on either linear programming, which provides accurate solutions by employing a large computation time that grows with the size of the problem, or heuristic methods, which usually find suboptimal solutions in a shorter amount of time. In this paper, a multi-agent route planning system capable of solving the Team Orienteering Problem in a very fast and accurate manner is presented. The proposed system is based on a centralized Transformer neural network that can learn to encode the scenario (modeled as a graph) and the context of the agents to provide fast and accurate solutions. Several experiments have been performed to demonstrate that the presented system can outperform most of the state-of-the-art works in terms of computation speed. In addition, the code is publicly available at http://gti.ssr.upm.es/data.