 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Apr 13, 2026Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Integrating Generic Sensor Fusion Algorithms with Sound State Representations through Encapsulation of Manifolds
Jul 06, 2011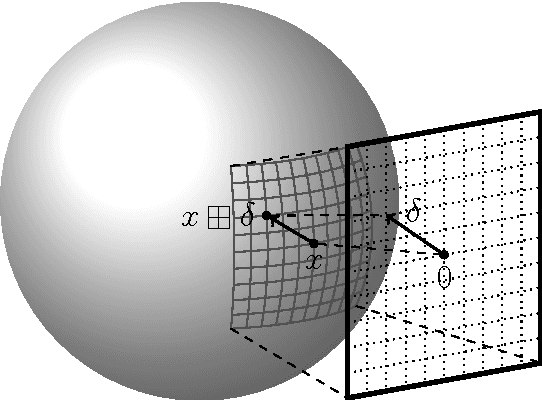
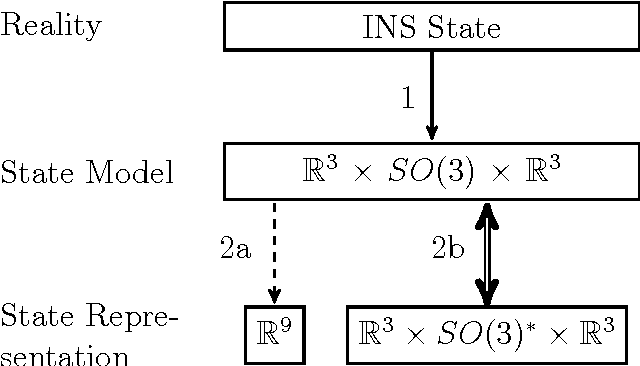
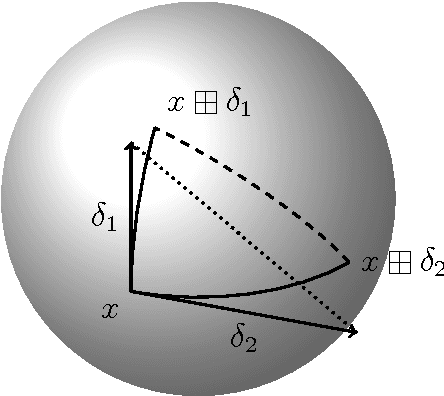
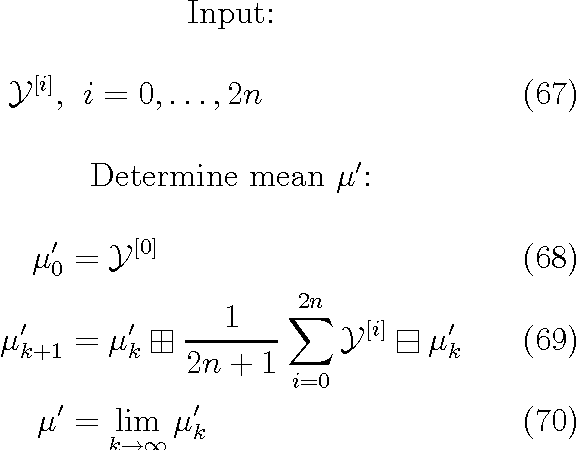
Common estimation algorithms, such as least squares estimation or the Kalman filter, operate on a state in a state space S that is represented as a real-valued vector. However, for many quantities, most notably orientations in 3D, S is not a vector space, but a so-called manifold, i.e. it behaves like a vector space locally but has a more complex global topological structure. For integrating these quantities, several ad-hoc approaches have been proposed. Here, we present a principled solution to this problem where the structure of the manifold S is encapsulated by two operators, state displacement [+]:S x R^n --> S and its inverse [-]: S x S --> R^n. These operators provide a local vector-space view \delta; --> x [+] \delta; around a given state x. Generic estimation algorithms can then work on the manifold S mainly by replacing +/- with [+]/[-] where appropriate. We analyze these operators axiomatically, and demonstrate their use in least-squares estimation and the Unscented Kalman Filter. Moreover, we exploit the idea of encapsulation from a software engineering perspective in the Manifold Toolkit, where the [+]/[-] operators mediate between a "flat-vector" view for the generic algorithm and a "named-members" view for the problem specific functions.