 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Term and Long-Term Context Aggregation Network for Video Inpainting
Sep 12, 2020
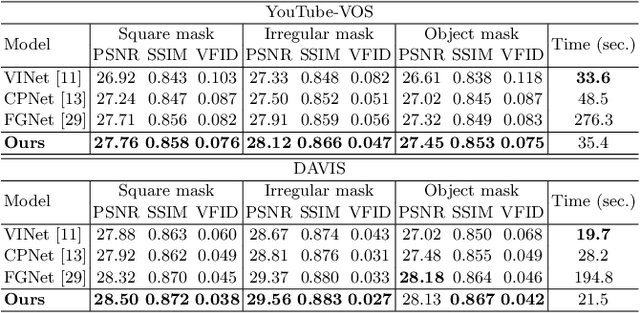


Video inpainting aims to restore missing regions of a video and has many applications such as video editing and object removal. However, existing methods either suffer from inaccurate short-term context aggregation or rarely explore long-term frame information. In this work, we present a novel context aggregation network to effectively exploit both short-term and long-term frame information for video inpainting. In the encoding stage, we propose boundary-aware short-term context aggregation, which aligns and aggregates, from neighbor frames, local regions that are closely related to the boundary context of missing regions into the target frame. Furthermore, we propose dynamic long-term context aggregation to globally refine the feature map generated in the encoding stage using long-term frame features, which are dynamically updated throughout the inpainting process. Experiments show that it outperforms state-of-the-art methods with better inpainting results and fast inpainting speed.
Boosted GAN with Semantically Interpretable Information for Image Inpainting
Aug 13, 2019
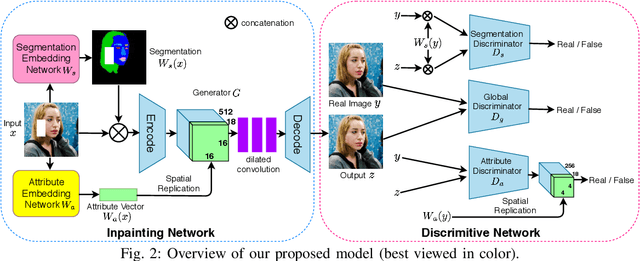


Image inpainting aims at restoring missing region of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based inpainting models fail to explicitly consider the semantic consistency between restored images and original images. Forexample, given a male image with image region of one eye missing, current models may restore it with a female eye. This is due to the ambiguity of GAN-based inpainting models: these models can generate many possible restorations given a missing region. To address this limitation, our key insight is that semantically interpretable information (such as attribute and segmentation information) of input images (with missing regions) can provide essential guidance for the inpainting process. Based on this insight, we propose a boosted GAN with semantically interpretable information for image inpainting that consists of an inpainting network and a discriminative network. The inpainting network utilizes two auxiliary pretrained networks to discover the attribute and segmentation information of input images and incorporates them into the inpainting process to provide explicit semantic-level guidance. The discriminative network adopts a multi-level design that can enforce regularizations not only on overall realness but also on attribute and segmentation consistency with the original images. Experimental results show that our proposed model can preserve consistency on both attribute and segmentation level, and significantly outperforms the state-of-the-art models.
Invariant backpropagation: how to train a transformation-invariant neural network
Jan 15, 2016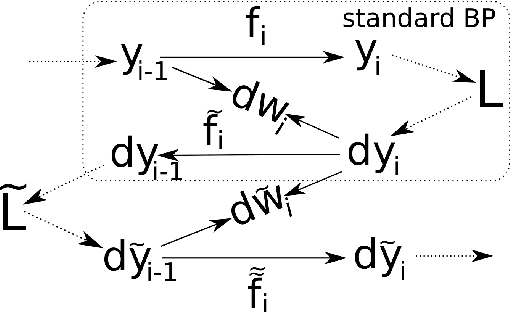
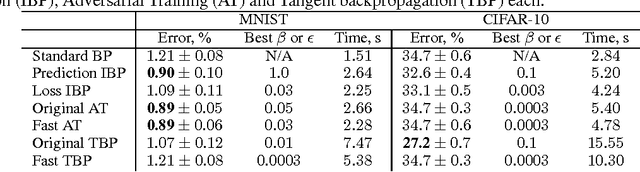
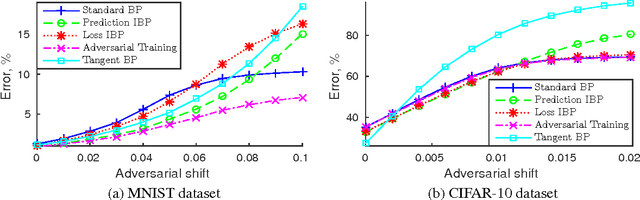
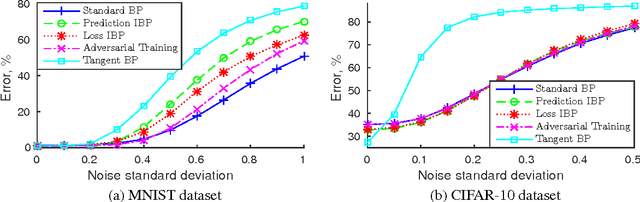
In many classification problems a classifier should be robust to small variations in the input vector. This is a desired property not only for particular transformations, such as translation and rotation in image classification problems, but also for all others for which the change is small enough to retain the object perceptually indistinguishable. We propose two extensions of the backpropagation algorithm that train a neural network to be robust to variations in the feature vector. While the first of them enforces robustness of the loss function to all variations, the second method trains the predictions to be robust to a particular variation which changes the loss function the most. The second methods demonstrates better results, but is slightly slower. We analytically compare the proposed algorithm with two the most similar approaches (Tangent BP and Adversarial Training), and propose their fast versions. In the experimental part we perform comparison of all algorithms in terms of classification accuracy and robustness to noise on MNIST and CIFAR-10 datasets. Additionally we analyze how the performance of the proposed algorithm depends on the dataset size and data augmentation.